Wetenschap
Onderzoekers ontginnen de cache van Intel-processors om de verwerking van datapakketten te versnellen
Krediet:KTH The Royal Institute of Technology
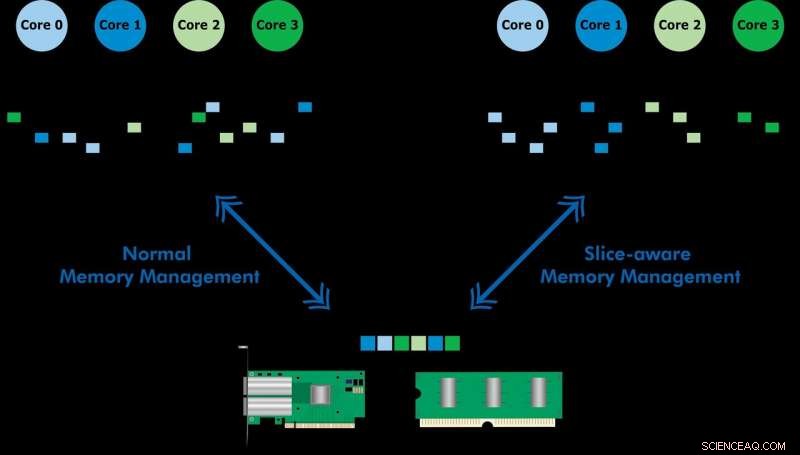
Ontwikkeld met Ericsson Research, het slice-aware geheugenbeheerschema zorgt ervoor dat veelgebruikte gegevens sneller toegankelijk zijn via de last-level cache of memory (LLC) van een Intel Xeon CPU. Door een sleutelwaardeopslag op te zetten en geheugen toe te wijzen op een manier dat het wordt toegewezen aan het meest geschikte LLC-segment, ze demonstreerden zowel snelle pakketverwerking als verbeterde prestaties van een sleutelwaardearchief. Het team gebruikte het voorgestelde schema om een tool genaamd CacheDirector te implementeren, die Data Direct I/O (DDIO) slice-aware maakt en een conferentiepaper publiceerde, Haal het meeste uit Last Level Cache in Intel-processors, die in het voorjaar werd gepresenteerd op EuroSys 2019.
"Momenteel, een server die 64-byte pakketten ontvangt met 100 Gbps heeft slechts 5,12 nanoseconden om elk pakket te verwerken voordat het volgende arriveert, " zegt co-auteur Alireza Farshin, een doctoraatsstudent bij KTH's Network Systems Laboratory. Maar als gegevens naar de juiste cacheschijf in de CPU worden gerouteerd, het is sneller toegankelijk, waardoor snellere verwerking van meer pakketten mogelijk is, in minder dan 5 nanoseconden.
Data Direct I/O (DDIO) stuurt pakketten naar willekeurige slices, wat verre van efficiënt is. Gezien de huidige niet-uniforme cache-architectuur (NUCA), de oplossing voor cachebeheer is van onschatbare waarde, zegt KTH-professor Dejan Kostic, die het onderzoek leidde.
"In combinatie met de introductie van dynamische headroom in de Data Plane Development Kit (DPDK), de header van het pakket kan in de plak van de LLC worden geplaatst die zich het dichtst bij de relevante verwerkingskern bevindt. Als resultaat, de kern kan sneller toegang krijgen tot pakketten en tegelijkertijd de wachtrijtijd verkorten, " hij zegt.
"Ons werk toont aan dat het profiteren van verbeteringen in de latentie van nanoseconden een grote impact kan hebben op de prestaties van applicaties die draaien op reeds sterk geoptimaliseerde computersystemen. ", zegt Farshin. Het team ontdekte dat voor een CPU met een snelheid van 3,2 GHz, CacheDirector kan tot ongeveer 20 cycli per toegang tot de LLC besparen, wat neerkomt op 6,25 nanoseconden. Dit versnelt de pakketverwerking en vermindert de staartlatentie van geoptimaliseerde Network Function Virtualization (NFV)-serviceketens met een snelheid van 100 Gbps tot 21,5 procent.
 Hoe Kovats te berekenen Index
Hoe Kovats te berekenen Index- Hoe worden whiteboards gemaakt?
- Onderzoekers creëren duurzame, wasbare textielcoating die virussen kan afstoten
- Nieuwe bevindingen over het effect van Epsom-zout - Epsom-zoutreceptor geïdentificeerd
- Zuurstof-vacature-gemedieerde katalyse stimuleert directe methanisering van biomassa
- Historische neerslagniveaus zijn significant in koolstofemissies uit de bodem
- Waarom zitten we niet allemaal in dezelfde tijdzone?
- Erosie en verwering bestuderen op een van de meest extreme plekken op aarde
- Hoe werkt verbranding van fossiele brandstoffen van invloed op de stikstofcyclus?
- Balis Agung - met behulp van forensisch onderzoek van de vulkaan om het verleden in kaart te brengen, en de toekomst voorspellen
Hoofdlijnen
- Studie vindt toename van herbicide bij oudere volwassenen
- Your Body On: A Horror Movie
- Onderzoekers beschrijven allereerste hybride vogelsoorten uit de Amazone
- Drie artikelen helpen de code van co-enzym Q-biosynthese te kraken
- Volledige structuur van mitochondriaal respiratoir supercomplex gedecodeerd
- Wat zijn de verschillen tussen een oog van een koe en een menselijk oog?
- Zelfgemaakte UV-sterilisator
- Nieuw onderzoek onthult de enige tuimelaars in Engeland
- DNA-modellen maken met behulp van papier
- Elektrische voertuigen sturen realtime gegevens naar de Chinese overheid

- $1, 000 voor een smartphone? Wat dacht je van $ 100?

- Winst Boeing stijgt na belastingafrekening verhoogt schatting van inkomsten

- Cambridge Analytica gebruikte onze geheimen voor winst – dezelfde gegevens kunnen worden gebruikt voor algemeen belang

- Winst eerste kwartaal Panasonic stijgt met 17,6 procent


 Vier soorten fysieke weersomstandigheden
Vier soorten fysieke weersomstandigheden - Elektrisch verwarmd textiel nu mogelijk
- Vraag en antwoord:hoe Facebook het wilde westen van politieke advertenties reguleert
- Filippijnse vulkaanuitbarsting kan volgende winter leiden tot opwarming van El Nino
- Wat zijn vier niet-levende dingen in een woestijnecosysteem?
- Hoe worden fossielen in de wetenschap gebruikt?
- Nadere beschouwing van de impact op de levenscyclus van lithium-ionbatterijen en brandstofcellen met protonenuitwisselingsmembraan
- Wat hebben de grotere planeten gemeen?
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Swedish | German | Dutch | Danish | Norway | Portuguese |

-
Wetenschap © https://nl.scienceaq.com
