Wetenschap
Een aanpak voor het beveiligen van audioclassificatie tegen aanvallen van tegenstanders
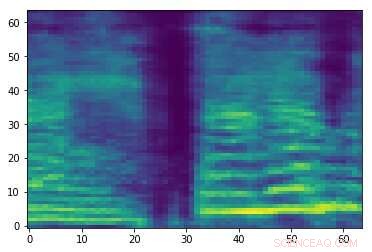
Spectrogram van een willekeurig audiosignaal. Krediet:Esmailpour, Kardinaal &Lemeiras Koerich.
Tegenstrijdige audio-aanvallen zijn kleine verstoringen die niet waarneembaar zijn voor mensen en die opzettelijk worden toegevoegd aan audiosignalen om de prestaties van machine learning (ML)-modellen te verminderen. Deze aanvallen geven aanleiding tot ernstige bezorgdheid over de veiligheid van ML-modellen, omdat ze ervoor kunnen zorgen dat ze fouten maken en uiteindelijk verkeerde voorspellingen genereren.
Onderzoekers van de École de Technologie Supérieure, een deel van de Universiteit van Quebec in Canada hebben onlangs een nieuwe aanpak ontwikkeld die kan helpen bij het beveiligen van audioclassificatietools tegen aanvallen van tegenstanders. In hun krant voorgepubliceerd op arXiv, ze beoordelen enkele van de sterkste bestaande aanvallen van tegenstanders en hun impact op de prestaties van veelvoorkomende ML-modellen, stel vervolgens een aanpak voor die deze aanvallen zou kunnen tegengaan.
"Momenteel, er zijn veel sterke en snelle (at runtime) classifiers in termen van nauwkeurigheid, namelijk deep learning classifiers (bijv. convolutionele neurale netwerken), die zelfs beter kunnen presteren dan het menselijke niveau van media (bijv. spraak, afbeelding, video, animatie, tekst, enz.) herkenning en regressie, "Mohammad Esmaeilpour, een van de onderzoekers die het onderzoek heeft uitgevoerd, vertelde TechXplore. "De achilleshiel van deze geavanceerde algoritmen is hun kwetsbaarheid voor invoer die zorgvuldig vervaardigde verstoringen bevat, bekend als vijandige aanvallen."
Adversariële aanvallen werken door het produceren van voorbeelden die sterk lijken op legitieme trainingsvoorbeelden, maar die er in feite toe leiden dat een ML-model of modellen verkeerde labels genereren met hoge betrouwbaarheidsniveaus. In ML-onderzoek als er voldoende gegevens zijn om een classifier te trainen, de belangrijkste uitdaging is niet langer de nauwkeurigheid van de herkenning te verbeteren, maar ervoor zorgen dat het bestand is tegen vijandige aanvallen.
"Adversariële aanvallen zijn actieve bedreigingen voor alle gegevensgestuurde algoritmen, zelfs degenen die getraind zijn op kleine datasets, "Dit wekte onze interesse om de dreiging van vijandige aanvallen voor audio- en spraakherkenningstoepassingen te bestuderen", aldus Esmaeilpour. aangezien alle smartphones nu zijn uitgerust met een virtuele spraakassistent zoals Siri, Google-assistent en Cortana."
In hun studie hebben Esmaeilpour en zijn collega's voerden experimenten uit met omgevingsgeluidsdatasets, in plaats van spraakdatasets. Niettemin, in de toekomst zou hun aanpak mogelijk ook kunnen worden uitgebreid tot spraakherkenning, die zou helpen om stemassistenten te beveiligen tegen vijandige aanvallen.
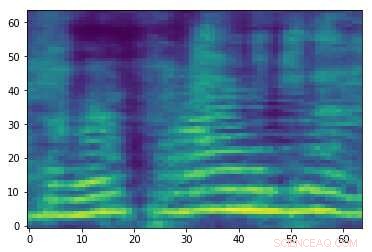
Vervaardigd tegengesteld spectrogram dat is gekoppeld aan het audiosignaal in de eerste afbeelding. Hoewel de twee afbeeldingen op elkaar lijken, ze hebben verschillende labels, suggereert dat er een aanval plaatsvindt. Krediet:Esmailpour, Kardinaal &Lemeiras Koerich.
"Ons hoofddoel in dit artikel was om de dreiging van vijandige aanvallen voor zowel conventionele als deep learning audioclassificaties te bestuderen en idealiter een betrouwbaarder algoritme voor te stellen in termen van veerkracht tegen sommige veelvoorkomende aanvallen als basis voor echte robuuste audioclassificatie, Esmaeilpour legde uit. "We wilden een eerlijke balans maken voor classificaties in herkenningsnauwkeurigheid, rekenkundige complexiteit, en robuustheid tegen vijandige aanvallen."
Over het algemeen, classificaties die robuuster zijn tegen aanvallen van tegenstanders, bereiken een lagere herkenningsnauwkeurigheid, en vice versa. In hun studie hebben de onderzoekers richtten zich op vijandige omscholing, een van de meest geldige bestaande verdedigingstechnieken die gradiëntinformatie niet verduisteren. Ondanks zijn voordelen, deze specifieke verdedigingsstrategie is kostbaar (aangezien sterke aanvallen duur zijn, vijandige omscholing met behulp van deze aanvallen zal duurder zijn) en kan de herkenningsprestaties van een classifier negatief beïnvloeden.
"Het ideale geval voor ons zou zijn om een audioclassificatie zonder gradiëntverduistering en zonder tegenstanders om te trainen, die inherent 'robuuste functies' leert, " zei Esmaeilpour. "Ons classificatiescenario omvat verschillende stappen, voornamelijk spectrogram (2D-weergave voor audiosignalen) verbetering, dimensionaliteitsreductie met behulp van een algebraïsche decompositietechniek, en afvlakking door gebruik te maken van een convolutionele de-noising autoencoder, waar de laatste twee stappen (op elkaar gestapeld) positieve effecten hebben laten zien op het verwijderen van kleine onbekende potentiële vijandige verstoringen."
Na het bekijken van enkele van de sterkste vijandige aanvallen die er zijn en hun effecten op de prestaties van ML-modellen, de onderzoekers extraheren kenmerken uit de spectrogrammen die door de modellen zijn verwerkt, organiseerde ze in een codeboek en trainde een support vector machine (SVM) algoritme op dit codeboek. In hun opleidingstraject ze hebben geen proactieve of reactieve aanvalsdetectietechnieken of verdedigingsalgoritmen geïmplementeerd.
"Ons hoofddoel was om 'robuuste kenmerkvectoren' te leren zonder enige overhead voor of na de verwerking voor het detecteren van potentiële tegenstanders, Esmaeilpour legde uit. "Onze resultaten laten zien dat onze voorgestelde classificatie beter presteert dan de modernste deep learning en conventionele algoritmen tegen vijf soorten sterke vijandige aanvallen voor een aantal praktische audiodatasets uit de omgeving."
Esmaeilpour en zijn collega's hebben statistisch de kwetsbaarheid bewezen van zowel conventionele classifiers (d.w.z. classifiers die leren van feature space) als deep learning-algoritmen (d.w.z. algoritmen die leren van ruwe data) tegen aanvallen van tegenstanders. Volgens de onderzoekers is er is momenteel geen betrouwbaar datagestuurd algoritme voor audioclassificatie dat ook robuust is tegen aanvallen van tegenstanders. Onder de bestaande modellen, op diep leren gebaseerde benaderingen lijken het minst veilig te zijn tegen deze aanvallen, zelfs als ze doorgaans de hoogste herkenningsnauwkeurigheid bereiken.
"Het classificatiescenario dat we in onze paper hebben voorgesteld, gebruikt een SVM met polynoomkernel als laatste classificatie, "zei Esmaeilpour. "Echter, het toepassen van een convolutionele de-ruisende auto-encoder bovenop singuliere waardedecompositie gevolgd door een onbewaakte clustering van geëxtraheerde versnelde robuuste kenmerkvectoren zou kunnen helpen om meer structurele componenten en waarschijnlijk robuuste kenmerken te leren, wat ons in staat zou kunnen stellen een redelijk evenwicht te bereiken tussen herkenningsnauwkeurigheid (vergelijkbaar met de modernste prestaties) en robuustheid tegen vijf veelvoorkomende sterke vijandige aanvallen."
Hoewel de door de onderzoekers verzamelde resultaten veelbelovend zijn, ze kunnen variëren afhankelijk van de gebruikte dataset of de specifieke toepassing van een classifier, daarom zijn ze nog niet generaliseerbaar. In de toekomst, hun studie zou de ontwikkeling van andere classificaties kunnen informeren die beter zijn toegerust tegen vijandige aanvallen, zonder aanzienlijke prestatieverliezen (d.w.z. herkenningsnauwkeurigheid).
"Het leren van robuuste functies is een open probleem en we hebben nog steeds geen duidelijk idee hoe we het op de juiste manier moeten aanpakken; het wordt bestudeerd door ons onderzoeksteam en sommige resultaten zullen binnenkort worden vrijgegeven, ' zei Esmaeilpour. 'Ondertussen, we werken aan een nieuwe, sterke en snelle vijandige aanvalstechniek gericht op het gebruik van deze aanval om het leermodel (wat de robuustheid ervan verbetert) adversarieel te trainen en ook de herkenningsprestaties van het model op te slaan voordat het wordt getraind."
© 2019 Wetenschap X Netwerk
 Wat is een eco-therapeut?
Wat is een eco-therapeut? - De lucht decoderen:de impact van waterdamp op regen in de middag
- Het meten van de gevolgen voor de volksgezondheid na rampen
- Verborgen in Afrikaanse diamanten, meer dan een miljard jaar geschiedenis van de diepe aarde
- Lessen uit de Nederlandse geologische geschiedenis kunnen nuttig zijn voor andere hedendaagse delta's
Hoofdlijnen
- Onderzoekers ontdekken de onverwachte atomaire structuur van koude- en mentholsensor TRPM8
- Waarom kunnen we de voetstappen van anderen horen,
- Lake Michigan watervogels botulisme sterfgevallen in verband met warm water, algen
- Voeding die de productiviteit in de intensieve veehouderij verhoogt
- De leeftijd van een skelet bepalen
- Stamcelplatform werpt nieuw licht op het begin van menselijke ontwikkeling
- Het verschil tussen histon en nonhiston
- Kiemvrije broedeieren:een alternatief voor het gebruik van formaldehyde
- Elektronenmicroscoopbeelden laten zien hoe cellen een vitaal mineraal opnemen
- Rechtop? DIY colonoscopie onder rare wetenschap op Tokyo show

- China's 737-beweging toont groeiende wereldwijde luchtvaartkracht:analisten

- Hoe speltheorie mens en robot dichter bij elkaar kan brengen

- EU geeft Google een nieuwe boete:bronnen

- Katachtig gehoor met apparaat dat tientallen biljoenen keer kleiner is dan het menselijk trommelvlies


 Broeikasgasemissies van internationale scheepvaart nemen toe
Broeikasgasemissies van internationale scheepvaart nemen toe- Franse parlementsleden geven online platforms 24 uur om haatzaaiende uitlatingen te verwijderen
- Satellietanalyse op lange termijn laat zien dat het regenseizoen nu natter is dan ooit
- Groen nationalisme? Hoe extreemrechts kan leren van het milieu te houden
- High Definition Earth-Viewing-lading bereikt einde levensduur op station, levensverwachting overtreffen
- Een boxplot van een cumulatieve frequentie maken
- Permafrost:een klimaattijdbom?
- Nieuwe nanodeeltjes maken zonnecellen goedkoper te produceren
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
