Wetenschap
Ziekte herkennen met minder gegevens
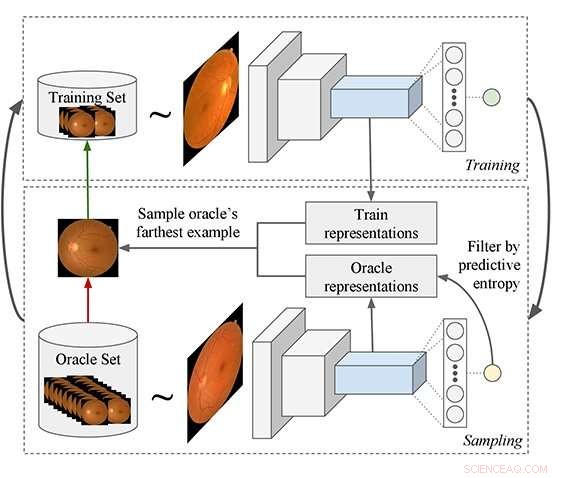
Voorgestelde Active Learning-pijplijn:het proces begint met het trainen van een model en het gebruiken ervan om voorbeelden op te vragen uit een niet-gelabelde gegevensset die vervolgens aan de trainingsset worden toegevoegd. Er wordt een nieuwe zoekfunctie voorgesteld die beter geschikt is voor Deep Learning (DL)-modellen. Het DL-model wordt gebruikt om functies te extraheren uit zowel de orakel- als de trainingssetvoorbeelden, en vervolgens filtert het algoritme de orakelvoorbeelden uit die een lage voorspellende entropie hebben. Eindelijk, het orakelvoorbeeld wordt geselecteerd dat gemiddeld het verst in functieruimte ligt ten opzichte van alle trainingsvoorbeelden. Krediet:Asim Smailagic
Naarmate kunstmatige-intelligentiesystemen afbeeldingen beter leren herkennen en classificeren, ze worden zeer betrouwbaar bij het diagnosticeren van ziekten, zoals huidkanker, van medische beelden. Maar hoe goed ze ook zijn in het detecteren van patronen, AI zal je dokter niet snel vervangen. Zelfs als het als hulpmiddel wordt gebruikt, beeldherkenningssystemen hebben nog steeds een expert nodig om de gegevens te labelen, en veel data:het heeft afbeeldingen nodig van zowel gezonde patiënten als zieke patiënten. Het algoritme vindt patronen in de trainingsgegevens en wanneer het nieuwe gegevens ontvangt, het gebruikt wat het heeft geleerd om het nieuwe beeld te identificeren.
Een uitdaging is dat het voor een expert tijdrovend en kostbaar is om elk beeld te verkrijgen en te labelen. Om dit probleem aan te pakken, een groep onderzoekers van Carnegie Mellon University's College of Engineering, waaronder professoren Hae Young Noh en Asim Smailagic, hebben samengewerkt om een actieve leertechniek te ontwikkelen die een beperkte dataset gebruikt om een hoge mate van nauwkeurigheid te bereiken bij het diagnosticeren van ziekten zoals diabetische retinopathie of huidkanker.
Het model van de onderzoekers begint te werken met een reeks niet-gelabelde afbeeldingen. Het model bepaalt hoeveel afbeeldingen er moeten worden gelabeld om een robuuste en nauwkeurige set trainingsgegevens te hebben. Het kiest een eerste set willekeurige gegevens om te labelen. Zodra die gegevens zijn gelabeld, het plot die gegevens over een distributie omdat de afbeeldingen zullen variëren naar leeftijd, geslacht, fysieke eigendom, etc. Om op basis van deze gegevens een goede beslissing te nemen, de monsters moeten een grote distributieruimte beslaan. Het systeem bepaalt vervolgens welke nieuwe gegevens aan de dataset moeten worden toegevoegd, gezien de huidige verspreiding van gegevens.
"Het systeem meet hoe optimaal deze verdeling is, " zei nee, een universitair hoofddocent civiele en milieutechniek, "en berekent vervolgens statistieken wanneer er een bepaalde set nieuwe gegevens aan wordt toegevoegd, en selecteert de nieuwe dataset die de optimaliteit maximaliseert."
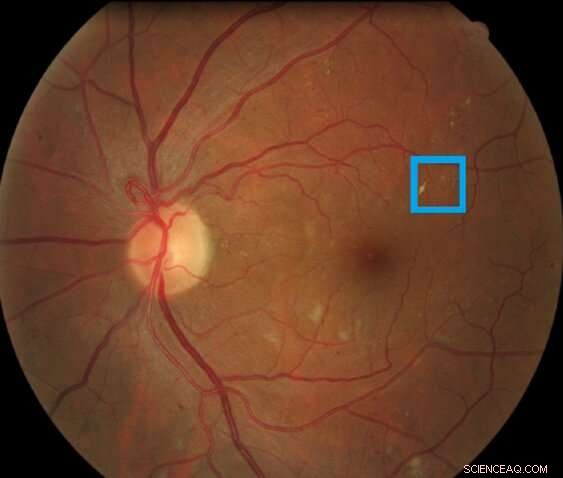
Afbeelding van een netvlies met een netvlieslaesie geassocieerd met diabetische retinopathie gemarkeerd in het vak. Dit soort laesie wordt een micro-aneurysma genoemd. Krediet:Asim Smailagic
Het proces wordt herhaald totdat de gegevensset voldoende is verdeeld om als trainingsset te worden gebruikt. hun methode, genaamd MedAL (voor medisch actief leren), bereikte 80% nauwkeurigheid bij het detecteren van diabetische retinopathie, met slechts 425 gelabelde afbeeldingen, wat een vermindering van 32% is van het aantal vereiste gelabelde voorbeelden in vergelijking met de standaard onzekerheidssteekproeftechniek, en een vermindering van 40% in vergelijking met willekeurige steekproeven.
Ze testten het model ook op andere ziekten, inclusief afbeeldingen van huidkanker en borstkanker, om aan te tonen dat het van toepassing kan zijn op een verscheidenheid aan verschillende medische beelden. De methode is generaliseerbaar, omdat de focus ligt op het strategisch gebruik van gegevens in plaats van te proberen een specifiek patroon of kenmerk voor een ziekte te vinden. Het kan ook worden toegepast op andere problemen die deep learning gebruiken, maar databeperkingen hebben.
"Onze actieve leerbenadering combineert op voorspellende entropie gebaseerde onzekerheidsbemonstering en een afstandsfunctie op een geleerde functieruimte om de selectie van niet-gelabelde monsters te optimaliseren, " zei Smailagic, een onderzoeksprofessor in Carnegie Mellon's Engineering Research Accelerator. "De methode overwint de beperkingen van de traditionele benaderingen door efficiënt alleen de afbeeldingen te selecteren die de meeste informatie geven over de algehele gegevensdistributie, het verminderen van de rekenkosten en het verhogen van zowel de snelheid als de nauwkeurigheid."
Het team omvatte civiele en milieutechniek Ph.D. studenten Mostafa Mirshekari, Jonathon Fagert, en Susu Xu, en masterstudenten elektrotechniek en computertechniek Devesh Walawalkar en Kartik Khandelwal. Ze presenteerden hun bevindingen op de IEEE International Conference on Machine Learning and Applications 2018 in december, waar ze een Best Paper Award ontvingen voor hun nieuwe werk.
 Nieuwe geleidende coating kan de biometrische en draagbare technologie van de toekomst ontsluiten
Nieuwe geleidende coating kan de biometrische en draagbare technologie van de toekomst ontsluiten- Waar vindt chemische vertering plaats?
- Wat zijn subscripts in een chemische formule die wordt gebruikt om aan te geven?
- Koolstofneutrale brandstoffen komen een stap dichterbij
- Het visualiseren van de warmtestroom in bamboe kan helpen bij het ontwerpen van meer energie-efficiënte en brandveilige gebouwen
- Verkeersdrempels op Duitse weg om klimaatverandering tegen te gaan
- Buurtvergroening kan leiden tot gentrificatie en ontheemding
- Traditie ontmoet technologie terwijl Keniaanse herders zich aanpassen aan klimaatverandering
- NASA bespioneert windschering nog steeds van invloed op tropische storm Nalgae
- Over voedselketens in het toendra-ecosysteem
Hoofdlijnen
- Bonobo's helpen vreemden ongevraagd
- Brigitte Macron viert eerste panda geboren in Frankrijk
- Twee soorten spitssnuitdolfijnen duren erg lang, diepe duiken voor hun grootte
- Welk enzym is verantwoordelijk voor het verlengen van de RNA-keten?
- Animatie ontmoet biologie - werpt nieuw licht op het gedrag van dieren
- Hoe wetenschappers de gezondheid van walvissen in de gaten houden door drones te gebruiken om hun slag op te vangen
- Waarom het zo goed voelt om bang te zijn
- Vloeken maakt je sterker,
- Gentherapie kan kreupelheid bij paarden genezen, onderzoek vindt
- Lokaal opgewekte stroom kan het antwoord zijn voor kwetsbaar energienet

- Leica blaast iconische Sovjet Zenit-camera nieuw leven in

- Stel je voor Apples App Store zonder ommuurde tuin

- Autofabrikant Rolls-Royce steunt VK na recordjaar (update)

- Onderzoekers zeggen dat de gezichtsdetectietechnologie van Amazon vooringenomenheid vertoont


 Militaire oefeningen voor robots
Militaire oefeningen voor robots- Hoe gaan supercharged racejachten zo snel? Een ingenieur legt uit:
- Blauwe nachtlichtende wolken verschijnen verder naar het zuiden dan ooit tevoren, en vervuiling kan een oorzaak zijn
- Afrikaanse immigranten:hoe ras en geslacht de Amerikaanse droom vormen
- Zelfaangedreven op papier gebaseerde SPED's kunnen leiden tot nieuwe medisch-diagnostische hulpmiddelen
- Wiskundefeiten leren
- Ontdekking verhoogt de mogelijkheid om neurologische aandoeningen te behandelen
- Kosmonaut, twee Amerikaanse astronauten keren terug naar de aarde vanuit ISS
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
