Wetenschap
Blinde vlekken op het gebied van kunstmatige intelligentie identificeren
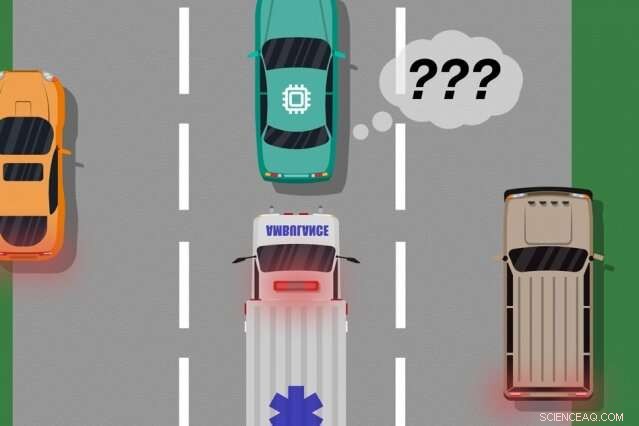
Een model van MIT- en Microsoft-onderzoekers identificeert gevallen waarin autonome auto's hebben "geleerd" van trainingsvoorbeelden die niet overeenkomen met wat er daadwerkelijk op de weg gebeurt, die kan worden gebruikt om te identificeren welke aangeleerde acties echte fouten kunnen veroorzaken. Krediet:MIT Nieuws
Een nieuw model ontwikkeld door onderzoekers van MIT en Microsoft identificeert gevallen waarin autonome systemen hebben "geleerd" van trainingsvoorbeelden die niet overeenkomen met wat er in de echte wereld gebeurt. Ingenieurs zouden dit model kunnen gebruiken om de veiligheid van kunstmatige-intelligentiesystemen te verbeteren, zoals voertuigen zonder bestuurder en autonome robots.
De AI-systemen die auto's zonder bestuurder aandrijven, bijvoorbeeld, worden uitgebreid getraind in virtuele simulaties om het voertuig voor te bereiden op bijna elk evenement op de weg. Maar soms maakt de auto een onverwachte fout in de echte wereld omdat er een gebeurtenis plaatsvindt die, maar niet, het gedrag van de auto veranderen.
Denk aan een auto zonder bestuurder die niet is opgeleid, en nog belangrijker, niet over de benodigde sensoren beschikt, onderscheid te maken tussen duidelijk verschillende scenario's, zoals grote, witte auto's en ambulances met rood, zwaailichten op de weg. Als de auto over de snelweg rijdt en een ambulance loeit op zijn sirenes, de auto weet misschien niet om te vertragen en te stoppen, omdat hij de ambulance niet anders ziet dan een grote witte auto.
In een paar papers - gepresenteerd op de Autonomous Agents and Multiagent Systems-conferentie van vorig jaar en de komende Association for the Advancement of Artificial Intelligence-conferentie - beschrijven de onderzoekers een model dat menselijke input gebruikt om deze 'blinde vlekken' voor training bloot te leggen.
Net als bij traditionele benaderingen, de onderzoekers lieten een AI-systeem door middel van simulatietraining. Maar dan, een mens houdt de acties van het systeem nauwlettend in de gaten terwijl het in de echte wereld handelt, feedback geven wanneer het systeem heeft gemaakt, of stond op het punt te maken, enige fouten. De onderzoekers combineren vervolgens de trainingsgegevens met de menselijke feedbackgegevens, en gebruik machine learning-technieken om een model te produceren dat situaties aangeeft waarin het systeem hoogstwaarschijnlijk meer informatie nodig heeft over hoe het correct moet handelen.
De onderzoekers valideerden hun methode met behulp van videogames, met een gesimuleerde mens die het geleerde pad van een personage op het scherm corrigeert. Maar de volgende stap is om het model te integreren met traditionele trainings- en testbenaderingen voor autonome auto's en robots met menselijke feedback.
"Het model helpt autonome systemen beter te weten wat ze niet weten, " zegt eerste auteur Ramya Ramakrishnan, een afgestudeerde student in het Computer Science and Artificial Intelligence Laboratory. "Vele keren, wanneer deze systemen worden ingezet, hun getrainde simulaties komen niet overeen met de echte wereld [en] ze kunnen fouten maken, zoals het krijgen van ongelukken. Het idee is om mensen te gebruiken om die kloof tussen simulatie en de echte wereld te overbruggen, op een veilige manier, zodat we een aantal van die fouten kunnen verminderen."
Co-auteurs van beide artikelen zijn:Julie Shah, een universitair hoofddocent bij de afdeling Lucht- en ruimtevaart en hoofd van de Interactive Robotics Group van CSAIL; en Ece Kamar, Debadeepta Dey, en Eric Horvitz, allemaal van Microsoft Research. Besmira Nushi is een extra co-auteur van de komende paper.
Feedback ontvangen
Sommige traditionele trainingsmethoden geven menselijke feedback tijdens praktijktests, maar alleen om de acties van het systeem bij te werken. Deze benaderingen identificeren geen blinde vlekken, die nuttig zou kunnen zijn voor een veiligere uitvoering in de echte wereld.
De aanpak van de onderzoekers zet eerst een AI-systeem door middel van simulatietraining, waar het een "beleid" zal produceren dat in wezen elke situatie in kaart brengt voor de beste actie die het kan nemen in de simulaties. Vervolgens, het systeem zal worden ingezet in de echte wereld, waar mensen foutsignalen geven in regio's waar de acties van het systeem onaanvaardbaar zijn.
Mensen kunnen op meerdere manieren gegevens verstrekken, zoals door middel van "demonstraties" en "correcties". Bij demonstraties, de menselijke handelingen in de echte wereld, terwijl het systeem de acties van de mens observeert en vergelijkt met wat het in die situatie zou hebben gedaan. Voor auto's zonder bestuurder, bijvoorbeeld, een mens zou de auto handmatig besturen terwijl het systeem een signaal afgeeft als het geplande gedrag afwijkt van het gedrag van de mens. Matches en mismatches met de acties van de mens geven luidruchtige indicaties van waar het systeem acceptabel of onacceptabel zou kunnen handelen.
Alternatief, de mens kan corrigeren, met de mens die het systeem in de gaten houdt zoals het in de echte wereld werkt. Een mens zou in de bestuurdersstoel kunnen zitten terwijl de autonome auto zichzelf langs zijn geplande route rijdt. Als de acties van de auto correct zijn, de mens doet niets. Als de acties van de auto niet correct zijn, echter, de mens mag het stuur overnemen, die een signaal afgeeft dat het systeem in die specifieke situatie niet onaanvaardbaar heeft gehandeld.
Zodra de feedbackgegevens van de mens zijn verzameld, het systeem heeft in wezen een lijst met situaties en, voor elke situatie, meerdere labels die zeiden dat zijn acties acceptabel of onaanvaardbaar waren. Een enkele situatie kan veel verschillende signalen ontvangen, omdat het systeem veel situaties als identiek waarneemt. Bijvoorbeeld, een zelfrijdende auto kan vele malen naast een grote auto zijn gereden zonder te vertragen en te stoppen. Maar, in slechts één geval, een ambulance, die precies hetzelfde lijkt voor het systeem, cruises voorbij. De zelfrijdende auto stopt niet en krijgt een signaal dat het systeem een onacceptabele actie heeft ondernomen.
"Op dat punt, het systeem heeft meerdere tegenstrijdige signalen gekregen van een mens:sommige met een grote auto ernaast, en het ging goed, en een waar een ambulance was op dezelfde exacte locatie, maar dat was niet goed. Het systeem maakt een kleine opmerking dat het iets verkeerd heeft gedaan, maar hij weet niet waarom, " zegt Ramakrishnan. "Omdat de agent al deze tegenstrijdige signalen krijgt, de volgende stap is het verzamelen van de informatie om te vragen, 'Hoe waarschijnlijk is het dat ik een fout maak in deze situatie waarin ik deze gemengde signalen heb ontvangen?'"
Intelligente aggregatie
Het einddoel is om deze ambigue situaties als blinde vlekken te bestempelen. Maar dat gaat verder dan alleen het optellen van de aanvaardbare en onaanvaardbare acties voor elke situatie. Als het systeem negen van de tien keer de juiste acties heeft uitgevoerd in de ambulancesituatie, bijvoorbeeld, een gewone meerderheid van stemmen zou die situatie als veilig bestempelen.
"Maar omdat onaanvaardbare acties veel zeldzamer zijn dan aanvaardbare acties, het systeem zal uiteindelijk leren om alle situaties als veilig te voorspellen, die zeer gevaarlijk kunnen zijn, ' zegt Ramakrishnan.
Daartoe, gebruikten de onderzoekers het Dawid-Skene-algoritme, een machinale leermethode die vaak wordt gebruikt voor crowdsourcing om labelruis aan te pakken. Het algoritme neemt als invoer een lijst met situaties, elk met een reeks luidruchtige "aanvaardbare" en "onaanvaardbare" labels. Vervolgens verzamelt het alle gegevens en gebruikt het enkele waarschijnlijkheidsberekeningen om patronen te identificeren in de labels van voorspelde blinde vlekken en patronen voor voorspelde veilige situaties. Met behulp van die informatie, het geeft voor elke situatie een enkel geaggregeerd "veilige" of "dode hoek"-label af, samen met een betrouwbaarheidsniveau in dat label. Opmerkelijk, het algoritme kan leren in een situatie waarin het kan, bijvoorbeeld, 90 procent van de tijd acceptabel uitgevoerd, de situatie is nog steeds dubbelzinnig genoeg om een "blinde vlek" te verdienen.
Uiteindelijk, het algoritme produceert een soort "warmtekaart, " waarbij elke situatie uit de oorspronkelijke training van het systeem een lage tot hoge kans krijgt om een blinde vlek voor het systeem te zijn.
"Wanneer het systeem in de echte wereld wordt geïmplementeerd, het kan dit aangeleerde model gebruiken om voorzichtiger en intelligenter te handelen. Als het geleerde model voorspelt dat een toestand een blinde vlek is met een hoge waarschijnlijkheid, het systeem kan een mens vragen naar de acceptabele actie, waardoor een veiligere uitvoering mogelijk is, ' zegt Ramakrishnan.
Dit verhaal is opnieuw gepubliceerd met dank aan MIT News (web.mit.edu/newsoffice/), een populaire site met nieuws over MIT-onderzoek, innovatie en onderwijs.
 Welke rol speelt warmte bij chemische reacties?
Welke rol speelt warmte bij chemische reacties? - Hoe kunnen de chemische eigenschappen van een stof worden bepaald?
- Additieve productie van op cellulose gebaseerde materialen met continue, multidirectionele stijfheidsgradiënten
- Een universele methode om eenvoudig stevige en rekbare hydrogels te ontwerpen
- Schuimbruis
- Waarom steeds meer inwoners van de VS in risicovolle natuurbrand- en overstromingsgebieden leven
- De beroemde espen van Colorado zal naar verwachting afnemen als gevolg van klimaatverandering
- Koralen helpen omgaan met druk
- Zou donkere koolstof de ware schaal van dode zones in de oceaan kunnen verbergen?
- Holoceentemperatuur op het Iberisch schiereiland gereconstrueerd met subfossielen van insecten
Hoofdlijnen
- De krimpende eland van Isle Royale
- Team ontdekt nieuwe mechanismen voor DNA-stabiliteit
- Wat is het verschil tussen actieve en passieve transportprocessen?
- Maak een lijst van de 3 stappen die zich voordoen tijdens de interfase
- Los Angeles Zoos oude Indiase neushoorn geëuthanaseerd
- Nu waren gestrest? Geschiedenis toont de oudste emotie
- Onderzoekers verkrijgen gegevens over de ontwikkeling van kippenembryo's
- Ter verdediging van kamsalamanders - waarom deze ongrijpbare amfibieën de moeite waard zijn?
- Het gebruik van kwallenbloei als oplossing voor het maken van nieuwe producten
- Optimale toewijzing van middelen voor UAV-communicatiesystemen bij rampenbeheer
- Bouwen aan de toekomst, één RoboBoat tegelijk

- Mens-machine-interactie maakt de ontwikkeling van zeer nauwkeurige besluitvormingssystemen mogelijk
- Evoluerende neurale netwerken met een lineaire groei in hun gedragscomplexiteit
- BA-piloten staken in september drie dagen


 Een nieuwe kijk op koraalriffen
Een nieuwe kijk op koraalriffen- Nissan meldt recordwinst voor het hele jaar, maar waarschuwt voor vooruitzichten
- Hoe kunnen aardbevingen een positieve invloed hebben op het milieu?
- Bosch stopt met het delen van scooters Coup in Europa
- Gas geeft laser-geïnduceerde grafeen super eigenschappen
- Onderzoek toont aan waar wereldwijde investeringen in hernieuwbare energie de grootste voordelen hebben
- Studie wijst op een meer holistische manier om de economische gevolgen van aardbevingen te meten
- Naar Mars gaan en nooit meer terugkomen
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
