Wetenschap
Een netwerk met twee aanzichten om diepte en egobeweging te voorspellen uit monoculaire sequenties
Krediet:Prasad, Das &Bhowmick.
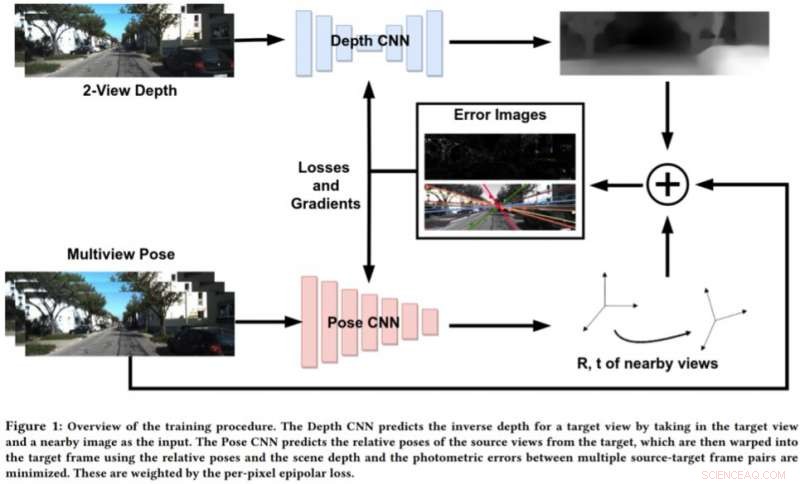
Onderzoekers van de Embedded Systems and Robotics-groep bij TCS Research &Innovation hebben onlangs een dieptenetwerk met twee aanzichten ontwikkeld om diepte en ego-beweging af te leiden uit opeenvolgende monoculaire sequenties. Hun aanpak, gepresenteerd in een paper dat vooraf is gepubliceerd op arXiv, omvat ook epipolaire beperkingen, die het geometrische begrip van het netwerk verbeteren.
"Ons belangrijkste idee was om te proberen pixelgewijze diepte en camerabewegingen rechtstreeks uit enkele beeldsequenties te voorspellen, "Dr. Brojeshwar Bhowmick, een van de onderzoekers die het onderzoek heeft uitgevoerd, vertelde TechXplore. "Traditioneel, structuur van op beweging gebaseerde reconstructie-algoritmen bieden schaarse diepte-uitgangen voor opvallende punten van belang in het beeld, die worden gevolgd over meerdere afbeeldingen met behulp van multi-view-geometrie. Nu deep learning steeds populairder wordt bij computervisietaken, we dachten eraan om bestaande methoden te gebruiken om onze zaak te helpen door het probleem op een meer fundamentele manier te benaderen met behulp van een combinatie van concepten uit de epipolaire geometrie en diep leren."
De meeste bestaande deep learning-benaderingen om monoculaire diepte en egobeweging te voorspellen, optimaliseren de fotometrische consistentie in beeldsequenties door de ene weergave in de andere te vervormen. Door diepte af te leiden uit een enkele weergave, echter, deze methoden slagen er mogelijk niet in om de relatie tussen pixels vast te leggen en dus om de juiste pixelovereenkomsten te verschaffen.
Om de beperkingen van deze benaderingen aan te pakken, Bhowmick en zijn collega's ontwikkelden een nieuwe benadering die geometrische computervisie en diepgaande leerparadigma's combineert. Hun aanpak maakt gebruik van twee neurale netwerken, een voor het voorspellen van de diepte van een enkel referentieaanzicht en een voor het voorspellen van de relatieve houdingen van een reeks aanzichten ten opzichte van het referentieaanzicht.

Krediet:Prasad, Das &Bhowmick.
"De doelbeeldscène kan worden gereconstrueerd vanuit een van de gegeven poses door ze te vervormen op basis van de diepte en relatieve poses, Bhowmick legde uit. "Gezien dit gereconstrueerde beeld en het referentiebeeld, we berekenen de fout in de pixelintensiteiten, die fungeert als ons belangrijkste verlies. We voegen de nieuwigheid toe van het gebruik van het epipolaire verlies per pixel, een concept uit multi-view geometrie, in het totale verlies, wat zorgt voor betere overeenkomsten en het extra voordeel heeft dat bewegende objecten in de scène worden verdisconteerd die anders het leren kunnen verslechteren."
In plaats van diepte te voorspellen door een enkel beeld te analyseren, deze nieuwe benadering werkt door een paar afbeeldingen uit een video te analyseren en interpixelrelaties te leren om diepte te voorspellen. Het lijkt enigszins op traditionele SLAM/SfM-algoritmen, die in de loop van de tijd pixelbewegingen kan waarnemen.
"De meest betekenisvolle bevindingen van onze studie zijn dat het gebruik van twee weergaven voor het voorspellen van de diepte beter werkt dan een enkele afbeelding, en dat zelfs zwakke handhaving van overeenkomsten op pixelniveau via epipolaire beperkingen goed werkt, " Bhowmick zei. "Zodra dergelijke methoden volwassen zijn en de generaliseerbaarheid verbeteren, we zouden ze kunnen toepassen voor waarneming op drones, waar men maximale zintuiglijke informatie zou willen extraheren door zo min mogelijk stroom te verbruiken, die kan worden bereikt door het gebruik van een enkele camera."
Bij voorlopige evaluaties de onderzoekers ontdekten dat hun methode diepte met een hogere nauwkeurigheid kon voorspellen dan bestaande benaderingen, het produceren van scherpere diepte-inschattingen en verbeterde pose-schattingen. Echter, momenteel, hun aanpak kan alleen gevolgtrekkingen op pixelniveau uitvoeren. Toekomstig werk zou deze beperking kunnen aanpakken door de semantiek van de scène in het model te integreren, wat zou kunnen leiden tot betere correlaties tussen objecten in de scène en zowel diepte- als ego-bewegingsschattingen.
"We onderzoeken verder de generaliseerbaarheid van deze methode en andere vergelijkbare methoden op verschillende scènes, zowel binnen als buiten, " zei Bhowmick. "Momenteel, de meeste werken presteren goed op buitengegevens, zoals rijgegevens, maar presteren zeer slecht op indoor sequenties met willekeurige bewegingen."
© 2019 Wetenschap X Netwerk
 Onderzoekers onthullen activiteit op atomair niveau van groene katalysator die wordt gebruikt bij de productie van PVC
Onderzoekers onthullen activiteit op atomair niveau van groene katalysator die wordt gebruikt bij de productie van PVC- 7e-grade Science Fair-projecten met Sodas
- Voorbeelden van niet-mengbare vloeistoffen
- Lasers gebruiken om moleculaire mysteries in onze atmosfeer te visualiseren
- Bereken Hitte-index Formula
- Opwarming van de aarde vergroot potentiële schade door natuurbranden in mediterraan Europa
- Niet te rechtvaardigen:nieuw rapport laat zien hoe de gasexpansie van de natie Australiërs in gevaar brengt
- Studie van het oude klimaat suggereert dat de toekomstige opwarming zou kunnen versnellen
- Mental accounting heeft invloed op duurzaam gedrag
- Diepzeesedimenten onthullen chaos in het zonnestelsel:een vooruitgang in het dateren van geologische archieven
Hoofdlijnen
- Studie belicht de instandhoudingsbehoeften van recent ontdekte vissoorten in Southwest Virginia
- Hoe slaaplabs werken
- Nieuwe methode voor het planten van citrusvruchten stopt insecten, levert extra voordelen op
- Waarom verhuizen chloroplasten in Elodea?
- Waarom planten spruiten vormen in het donker
- Kunnen eukaryoten overleven zonder mitochondria?
- Honden zijn expressiever als iemand kijkt
- Officiële vishandel onderschat wereldwijde vangsten enorm
- Wat gebeurt er met een dierlijke cel in een hypotone oplossing?
- Golf van verkeerde informatie over het coronavirus terwijl gebruikers van sociale media zich richten op populariteit, geen nauwkeurigheid

- Kritieke Starbleed-kwetsbaarheid in FPGA-chips geïdentificeerd
- Winst stijgt voor Microsoft dankzij cloud, Bedrijfsdiensten

- Hoge brandstofkosten drijven Lufthansa dieper in het rood in Q1

- MobiKa:een goedkope mobiele robot die mensen in verschillende omgevingen kan helpen


 Op metaal gebaseerde verbindingen maken de weg vrij voor nieuwe antivirale behandelingen
Op metaal gebaseerde verbindingen maken de weg vrij voor nieuwe antivirale behandelingen- Wat veroorzaakt waterstofbinding?
- De winst van Baidu groeit met 56% naarmate apps en AI de inkomsten verhogen
- Klimaatmodellen met hoge resolutie presenteren alarmerende nieuwe projecties voor de VS
- Sri Lanka stelt vragen over brandende bemanning van vrachtschepen als ecologische verwoesting beoordeeld
- Nulpunten vinden in Excel
- Hoe beïnvloeden het uitsterven van andere wezens mensen direct?
- Een nieuw begrip van eiwitbeweging
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
