Wetenschap
Bekrachtigingsleren gebruiken om mensachtige strategieën voor balanscontrole in robots te bereiken
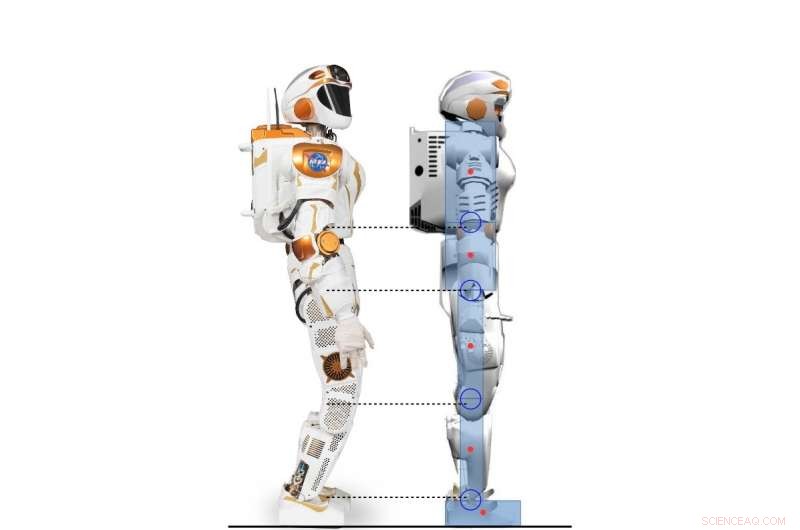
Zijaanzicht van Valkyrie-robot en het 2D-humanoïde karakter gemodelleerd volgens Valkyrie-robot. Krediet:Yang, Komura &Li
Onderzoekers van de Universiteit van Edinburgh hebben een hiërarchisch raamwerk ontwikkeld op basis van diep versterkend leren (RL) dat een verscheidenheid aan strategieën kan verwerven voor het beheersen van humanoïde balans. Hun kader, geschetst in een paper dat vooraf is gepubliceerd op arXiv en gepresenteerd op de International Conference on Humanoid Robotics 2017, zou veel menselijker evenwichtsgedrag kunnen vertonen dan conventionele controllers.
Bij staan of lopen, mensen gebruiken van nature en effectief een aantal technieken voor onderbekrachtigde controle die hen helpen hun evenwicht te bewaren. Deze omvatten het kantelen van de tenen en het rollen van de hiel, die een betere voet-bodemvrijheid creëren. Het repliceren van soortgelijk gedrag in humanoïde robots zou hun motorische en bewegingscapaciteiten aanzienlijk kunnen verbeteren.
"Ons onderzoek richt zich op het gebruik van diepe RL om dynamische voortbeweging van humanoïde robots op te lossen, "Dr. Zhibin Li, een docent robotica en controle aan de Universiteit van Edinburgh, die de studie heeft uitgevoerd, vertelde TechXplore. "Vroeger, voortbeweging werd voornamelijk gedaan met behulp van conventionele analytische benaderingen - op modellen gebaseerde, die beperkt zijn omdat ze menselijke inspanning en kennis vereisen, en vereisen een hoge rekenkracht om online te kunnen draaien."
Vereist minder menselijke inspanning en handmatige afstemming, machine learning-technieken zouden kunnen leiden tot de ontwikkeling van effectievere en specifiekere controllers dan traditionele technische benaderingen. Een ander voordeel van het gebruik van RL is dat de berekening voor deze tools ook offline kan worden uitbesteed, wat resulteert in snellere online prestaties voor hoogdimensionale besturingssystemen, zoals humanoïde robots.

Een gesimuleerde Valkyrie-robot in teen/hiel kantelende pose. Krediet:Yang, Komura &Li
"Gezien de steeds krachtigere diepe RL-algoritmen, een toenemend aantal onderzoeken is begonnen met het gebruik van diepe RL om controletaken op te lossen, aangezien de recente vooruitgang in diepe RL-algoritmen die zijn ontworpen voor het domein van continue actie, de mogelijkheid heeft geboden om continue controletaken met versterkingsleren toe te passen die gecompliceerde dynamiek met zich meebrengen, " Dr. Li legde uit. "Het belangrijkste doel van ons onderzoek was om de mogelijkheden te verkennen van het gebruik van diepgaand leren om een veelzijdig controlebeleid te verwerven dat vergelijkbaar of beter is dan analytische benaderingen, terwijl er minder menselijke inspanning nodig is."
Het raamwerk ontwikkeld door Dr. Li, in samenwerking met Dr. Taku Komura en Ph.D. student Chuanyu Yang, gebruikt diepe RL om controlebeleid op hoog niveau te bereiken. Voortdurend feedback ontvangen over de status van de robot, deze strategieën maken gewenste gewrichtshoeken mogelijk met een lagere frequentie.
"Op het laagste niveau proportionele en afgeleide (PD) controllers worden gebruikt met een veel hogere regelfrequentie om de stabiele gewrichtsbewegingen te garanderen, " Promovendus Chuanyu zei. "De inputs voor de low-level PD-controller zijn gewenste gewrichtshoeken geproduceerd door het high-level neurale netwerk, en de uitgangen zijn de gewenste koppels voor gezamenlijke motoren."
De onderzoekers testten de prestaties van hun algoritme en kwamen tot veelbelovende resultaten. Ze ontdekten dat het overbrengen van menselijke kennis van methoden voor regeltechniek naar het beloningsontwerp voor RL-algoritmen balanscontrolestrategieën mogelijk maakte die leken op die van mensen. Bovendien, naarmate RL-algoritmen verbeteren door middel van een proces van vallen en opstaan, automatisch aanpassen aan nieuwe situaties, hun raamwerk vereist weinig handafstemming of andere interventies door menselijke ingenieurs.
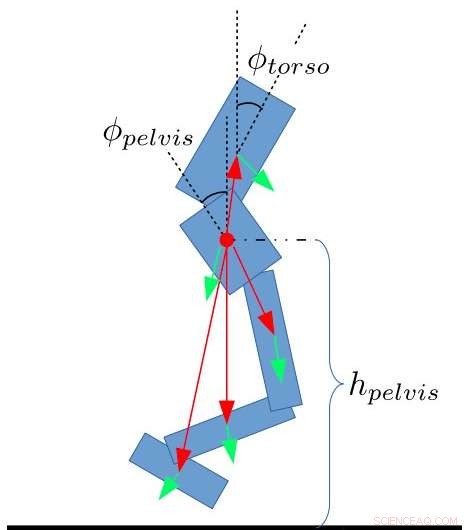
Staatskenmerken voor de tweevoeter. Yang, Komura &Li
"Ons onderzoek toont aan dat diepgaand leren met versterking een krachtig hulpmiddel kan zijn om vergelijkbare balanceringsresultaten te produceren als die van een door mensen ontworpen controller met minder handmatige afstemming en kortere tijd, " Dr. Li zei. "Het diepe versterkende leeralgoritme dat we hebben ontwikkeld, is zelfs in staat om opgekomen mensachtig gedrag te leren, zoals kantelen rond tenen of hielen, die de meeste technische methoden niet kunnen uitvoeren."
Dr. Li en zijn collega's werken nu aan een uitbreiding van hun studie die RL toepast op een full body Valkyrie-robot in een 3D-simulatie. In deze nieuwe onderzoeksinspanning, ze waren in staat om op mensen lijkende evenwichtsstrategieën te generaliseren naar lopen en andere voortbewegingstaken.
"Eventueel, we willen dit hiërarchische raamwerk van het combineren van machine learning en robotbesturing toepassen op echte humanoïde robots, evenals voor andere robotplatforms, ' zei dokter Li.
© 2018 Tech Xplore
 Wat gebeurt er als u zwembadchloor mengt en vloeistof breekt?
Wat gebeurt er als u zwembadchloor mengt en vloeistof breekt? - Geneesmiddeldiversiteit in bacteriën
- Nieuwe elektrokatalysator ontwikkeld voor zuurstofreductiereactie
- Tandemkatalysator om de elektroreductie van kooldioxide tot methaan te verbeteren
- Nieuwe tool stelt wetenschappers in staat om ongrijpbare eiwitten in actie te vangen
Hoofdlijnen
- Wat is het Forer-effect?
- Welke mechanismen zorgen voor de nauwkeurigheid van DNA-replicatie?
- Sequentiebepaling van het genoom van stevia-planten voor het eerst onthuld
- Whodunnit, als Aussie-reptielen uitsterven:studie (update)
- Conserveringsonderzoek gebruikt kleine loopbanden om het uithoudingsvermogen van de zeeschildpadden te testen
- Wat is urushiol?
- Lijst van aseksueel reproducerende organismen
- Wat maakt de aarde precies goed voor leven?
- Hoe voeden bacteriën?
- Zesjarige boom dwingt New York om Uber-regelgeving te overwegen

- Australië kan binnenkort zonneschijn naar Azië exporteren via een kabel van 3800 km

- Vereenvoudigde modellering van applicatie en infrastructuur

- Een brandschoon:vriendelijke robots verfraaien Singapore

- Uber prijst IPO op $ 45, bedrijf waarderen op $ 82 miljard:bron


 Satelliet bekeek tropische storm Jose die kustwateren kolkt
Satelliet bekeek tropische storm Jose die kustwateren kolkt- Kabellengte versus stroomuitval
- Hoge druk doet waterstofvarianten instorten
- NASA zonnezeil asteroïde missie klaar voor lancering op Artemis I
- Resultaten schrijven voor een Science Fair Project
- Diep graven in diamanten, natuurkundigen bevorderen kwantumwetenschap en -technologie
- Waarom het loont om emoties op de werkvloer op te merken
- Waarom een ontwerp het Amerikaanse leger zou verzwakken?
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
