Wetenschap
Berkeley-lab, Intel, Cray benut de kracht van diep leren om het universum te bestuderen
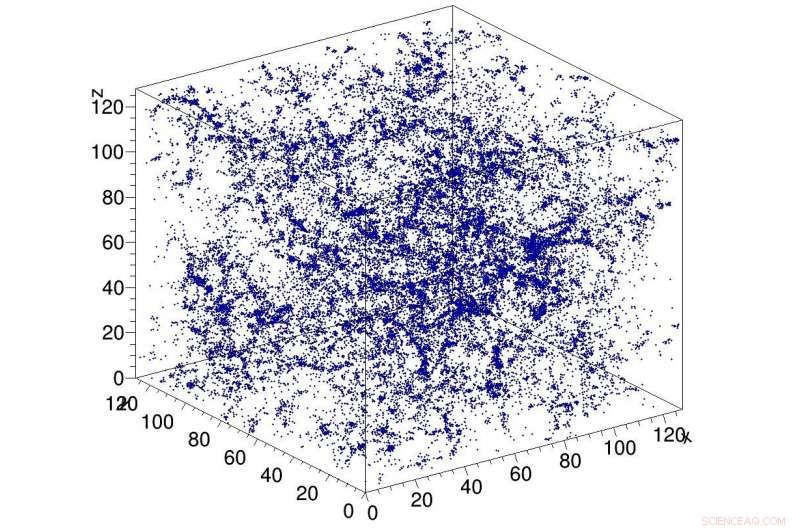
Voorbeeldsimulatie van donkere materie in het heelal, gebruikt als invoer voor het CosmoFlow-netwerk. CosmoFlow is de eerste grootschalige wetenschappelijke toepassing die het TensorFlow-framework gebruikt op een CPU-gebaseerd high-performance computerplatform met synchrone training. Krediet:Lawrence Berkeley National Laboratory
Een Big Data Center-samenwerking tussen computationele wetenschappers van het Lawrence Berkeley National Laboratory's (Berkeley Lab) National Energy Research Scientific Computing Center (NERSC) en ingenieurs bij Intel en Cray heeft een nieuwe primeur opgeleverd in de zoektocht om deep learning toe te passen op data-intensieve wetenschap:CosmoFlow , de eerste grootschalige wetenschappelijke toepassing die het TensorFlow-framework gebruikt op een CPU-gebaseerd high-performance computerplatform met synchrone training. Het is ook de eerste die driedimensionale (3-D) ruimtelijke gegevensvolumes op deze schaal verwerkt, wetenschappers een geheel nieuw platform bieden om een dieper inzicht in het universum te krijgen.
Kosmologische ''big data''-problemen gaan verder dan de eenvoudige hoeveelheid gegevens die op schijf is opgeslagen. Waarnemingen van het heelal zijn noodzakelijkerwijs eindig, en de uitdaging waarmee onderzoekers worden geconfronteerd, is hoe ze de meeste informatie uit de beschikbare observaties en simulaties kunnen halen. Wat het probleem nog ingewikkelder maakt, is dat kosmologen typisch de verdeling van materie in het universum karakteriseren met behulp van statistische metingen van de structuur van materie in de vorm van twee- of driepuntsfuncties of andere gereduceerde statistieken. Methoden zoals deep learning die alle kenmerken van de verdeling van materie kunnen vastleggen, zouden meer inzicht verschaffen in de aard van donkere energie. Siamak Ravanbakhsh en zijn collega's realiseerden zich als eerste dat deep learning op dit probleem kon worden toegepast. zoals waarnaar wordt verwezen in de procedures van The 33rd International Conference on Machine Learning. Echter, computationele knelpunten bij het opschalen van het netwerk en de dataset beperkten de omvang van het probleem dat kon worden aangepakt.
Gemotiveerd om deze uitdagingen aan te gaan, CosmoFlow is ontworpen om zeer schaalbaar te zijn; verwerken van grote, 3D kosmologie datasets; en om de prestaties van deep learning-training op moderne HPC-supercomputers te verbeteren, zoals de op Intel-processor gebaseerde Cray XC40 Cori-supercomputer bij NERSC. CosmoFlow is gebouwd bovenop het populaire TensorFlow-framework voor machine learning en gebruikt Python als front-end. De applicatie maakt gebruik van de Cray PE Machine Learning-plug-in om een ongekende schaalbaarheid van het TensorFlow Deep Learning-framework tot meer dan 8, 000 knooppunten. Het profiteert ook van Cray's DataWarp I/O-versnellertechnologie, die de I/O-doorvoer biedt die nodig is om dit schaalbaarheidsniveau te bereiken.
In een technische paper die in november op SC18 zal worden gepresenteerd, het CosmoFlow-team beschrijft de toepassing en de eerste experimenten met behulp van N-body-simulaties van donkere materie die zijn geproduceerd met behulp van de MUSIC- en pycola-pakketten op de Cori-supercomputer bij NERSC. In een reeks schaalexperimenten met één en meerdere knooppunten, het team was in staat om volledig synchrone data-parallelle training te demonstreren op 8, 192 van Cori met 77% parallelle efficiëntie en 3,5 Pflop/s aanhoudende prestaties.
"Ons doel was om aan te tonen dat TensorFlow efficiënt op meerdere knooppunten kan draaien, " zei Deborah Bard, een big data-architect bij NERSC en een co-auteur van de technische paper. "Voor zover wij weten, dit is de grootste implementatie ooit van TensorFlow op CPU's, en we denken dat het de grootste poging is om TensorFlow uit te voeren op het grootste aantal CPU-knooppunten."
Vroegtijdig, het CosmoFlow-team heeft drie hoofddoelen voor dit project opgesteld:wetenschap, optimalisatie en schaling met één knooppunt. Het wetenschappelijke doel was om aan te tonen dat deep learning kan worden gebruikt op 3D-volumes om de fysica van het universum te leren. Het team wilde er ook voor zorgen dat TensorFlow efficiënt en effectief zou werken op één Intel Xeon Phi-processorknooppunt met 3D-volumes, die gebruikelijk zijn in de wetenschap, maar niet zozeer in de industrie, waar de meeste deep learning-toepassingen omgaan met 2D-beeldgegevenssets. En tenslotte, hoge efficiëntie en prestaties te garanderen wanneer ze worden geschaald over duizenden knooppunten op het Cori-supercomputersysteem.
Als Joe Curley, Sr. directeur van de Code Modernization Organization in Intel's Data Center Group, dat is genoteerd, "De Big Data Center-samenwerking heeft verbluffende resultaten opgeleverd in de informatica door de combinatie van Intel-technologie en toegewijde software-optimalisatie-inspanningen. Tijdens het CosmoFlow-project, we identificeerden kader, kernel- en communicatie-optimalisatie die leidden tot meer dan 750x prestatieverbetering voor een enkel knooppunt. Even indrukwekkend, het team loste problemen op die het schalen van deep learning-technieken beperkten tot 128 tot 256 nodes, zodat de CosmoFlow-toepassing nu efficiënt kan worden geschaald naar de 8, 192 knooppunten van de Cori-supercomputer bij NERSC."
"We zijn enthousiast over de resultaten en de doorbraken in kunstmatige-intelligentietoepassingen van dit samenwerkingsproject met NERSC en Intel, " zei Per Nyberg, vice-president van marktontwikkeling, kunstmatige intelligentie en cloud bij Cray. "Het is opwindend om te zien dat het CosmoFlow-team profiteert van de unieke Cray-technologie en de kracht van de Cray-supercomputer gebruikt om deep learning-modellen effectief te schalen. Het is een geweldig voorbeeld van waar veel van onze klanten naar streven bij het convergeren van traditionele modellering en simulatie met nieuwe deep learning- en analysealgoritmen, allemaal op een enkele schaalbaar platform."
Prabhat, Groepsleider Data &Analytics Services bij NERSC, toegevoegd, "Van mijn perspectief, CosmoFlow is een voorbeeldproject voor de Big Data Center-samenwerking. We hebben echt gebruik gemaakt van competenties van verschillende instellingen om een moeilijk wetenschappelijk probleem op te lossen en onze productiestapel te verbeteren, wat de bredere NERSC-gebruikersgemeenschap ten goede kan komen."
Naast Bard en Prabhat, co-auteurs van de SC18-paper zijn onder meer Amrita Mathuriya, Laurens Weiden, Lei Shao, Tuomas Karna, John Pennycook, Jason Sewall, Nalini Kumar en Victor Lee van Intel; Peter Mendygral, Diana Moise, Kristyn Maschhoff en Michael Ringenburg uit Cray; Siyu He en Shirley Ho van het Flatiron Institute; en James Arnemann van UC Berkeley.
 Spingif sleutel tot pijnverlichting zonder bijwerkingen
Spingif sleutel tot pijnverlichting zonder bijwerkingen- Sproeidrogen - perfecte dosering dankzij medicijncapsules
- Een venster voor traploos ladingtransport in organische halfgeleiders
- Wanneer werkzame stof en doeleiwit elkaar omarmen
- Chemische synthese toont aan dat antibioticum uit de menselijke neus werkt door protontranslocatie
- Sneeuw boven Antarctica bufferde zeespiegelstijging vorige eeuw
- Aardbevingsrisico verhoogd met detectie van spontane tektonische tremor in Anza Gap
- De stijgende kosten van natuurbrandbestrijding vallen grotendeels buiten de controle van Forest Services
- Libellen kweken en grootbrengen in een huis Box
- Klimaatverandering zal miljoenen mensen verdrijven. Waar zullen ze heen gaan?
Hoofdlijnen
- Zijn mannen of vrouwen betere navigators?
- Parasieten van huisdieren die dieren in het wild wereldwijd aantasten
- Hoe werkt een DP-cel?
- Hoe een jetlag werkt
- Infectieziekten:CTRL + ALT + Delete
- Mariene wetenschappers leiden een uitgebreide beoordeling van soorten reuzenschelpdieren wereldwijd
- Vergelijking van klonen met mitose
- Onderzoekers richten zich op invasieve, verderfelijke gevlekte lantaarnvlieg
- Hoeveel mogelijke combinaties van eiwitten zijn mogelijk met 20 verschillende aminozuren?
- De punten verbinden tussen stem en een menselijk gezicht

- Ford voorspelt verlies van $ 112 miljoen in Q4 te midden van herstructureringskosten

- Een kijkje in de inrichting van de woonkamer laat zien hoe decoraties over de hele wereld variëren

- Gepompte opslag waterkracht een game-changer

- Walmart, Microsoft werkt samen om Amazon te verslaan


 Nieuwe techniek die gebruik maakt van bestaande technologieën maakt ongekende weergaven van cellen en andere zachte materialen mogelijk
Nieuwe techniek die gebruik maakt van bestaande technologieën maakt ongekende weergaven van cellen en andere zachte materialen mogelijk- China zegt lancering van belangrijke nieuwe ruimteraket succesvol
- VS willen dat vrouw beschuldigd van Capital One-hack opgesloten blijft
- Transistors zijn gemaakt van natuurlijke katoenvezels
- Hoe te neutraliseren Muriatic Acid
- Hoe de Accuplacer-wiskundetest te doorstaan
- Deep Space Antenne 1
- Wetenschappers presenteren nieuwe metingen van β-vertraagd twee-protonverval van 27S
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
