Wetenschap
Onderzoekers gebruiken machine learning om wetenschappelijke gegevens te doorzoeken
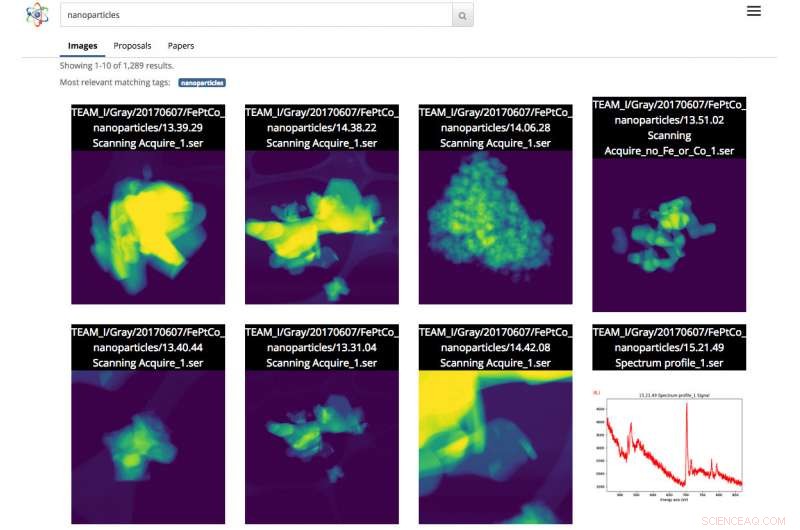
Screenshot van de Science Search-interface. In dit geval, de gebruiker deed een zoekopdracht naar afbeeldingen van nanodeeltjes. Krediet:Gonzalo Rodrigo, Berkeley Lab
Naarmate wetenschappelijke datasets zowel in omvang als complexiteit toenemen, het vermogen om te labelen, filteren en doorzoeken is deze stortvloed aan informatie een moeizaam, tijdrovende en soms onmogelijke taak, zonder de hulp van geautomatiseerde tools.
Met dit in gedachten, een team van onderzoekers van het Lawrence Berkeley National Laboratory (Berkeley Lab) en UC Berkeley ontwikkelt innovatieve tools voor machine learning om contextuele informatie uit wetenschappelijke datasets te halen en automatisch metadatatags voor elk bestand te genereren. Wetenschappers kunnen deze bestanden vervolgens doorzoeken via een webgebaseerde zoekmachine voor wetenschappelijke gegevens, genaamd Science Search, dat het Berkeley-team aan het bouwen is.
Als proof-of-concept, het team werkt samen met medewerkers van de Molecular Foundry van het Department of Energy (DOE), gevestigd in Berkeley Lab, om de concepten van Science Search te demonstreren op de beelden die zijn vastgelegd door de instrumenten van de faciliteit. Een bètaversie van het platform is beschikbaar gesteld aan Foundry-onderzoekers.
"Een tool als Science Search heeft het potentieel om ons onderzoek te revolutioneren, " zegt Colin Ophus, een onderzoeker in Molecular Foundry binnen het National Center for Electron Microscopy (NCEM) en Science Search Collaborator. "We zijn een door de belastingbetaler gefinancierde National User Facility, en we willen alle gegevens op grote schaal beschikbaar maken, in plaats van het kleine aantal afbeeldingen dat voor publicatie is gekozen. Echter, vandaag, de meeste gegevens die hier worden verzameld, worden slechts door een handvol mensen bekeken:de gegevensproducenten, inclusief de PI (hoofdonderzoeker), hun postdocs of afgestudeerde studenten, omdat er momenteel geen gemakkelijke manier is om de gegevens te doorzoeken en te delen. Door deze ruwe data gemakkelijk doorzoekbaar en deelbaar te maken, via het internet, Science Search zou dit reservoir van 'dark data' voor alle wetenschappers kunnen openen en de wetenschappelijke impact van onze faciliteit kunnen maximaliseren."
De uitdagingen van het zoeken naar wetenschappelijke gegevens
Vandaag, zoekmachines worden alom gebruikt om informatie op internet te vinden, maar het zoeken naar wetenschappelijke gegevens brengt een andere reeks uitdagingen met zich mee. Bijvoorbeeld, Het algoritme van Google vertrouwt op meer dan 200 aanwijzingen om tot een effectieve zoekopdracht te komen. Deze aanwijzingen kunnen komen in de vorm van trefwoorden op een webpagina, metadata in afbeeldingen of feedback van het publiek van miljarden mensen wanneer ze klikken op de informatie waarnaar ze op zoek zijn. In tegenstelling tot, wetenschappelijke gegevens komen in vele vormen die radicaal anders zijn dan een gemiddelde webpagina, vereist context die specifiek is voor de wetenschap en mist vaak ook de metadata om context te bieden die nodig is voor effectief zoeken.
Bij nationale gebruikersfaciliteiten zoals de Molecular Foundry, onderzoekers van over de hele wereld vragen tijd aan en reizen vervolgens naar Berkeley om gratis uiterst gespecialiseerde instrumenten te gebruiken. Ophus merkt op dat de huidige camera's op microscopen in de Foundry in minder dan 10 minuten tot een terabyte aan gegevens kunnen verzamelen. Gebruikers moeten vervolgens handmatig door deze gegevens bladeren om kwaliteitsafbeeldingen met een "goede resolutie" te vinden en die informatie op een veilig gedeeld bestandssysteem op te slaan, zoals Dropbox, of op een externe harde schijf die ze uiteindelijk mee naar huis nemen om te analyseren.
Vaak, de onderzoekers die naar de Molecular Foundry komen, hebben maar een paar dagen om hun data te verzamelen. Omdat het erg vervelend en tijdrovend is om handmatig notities toe te voegen aan terabytes aan wetenschappelijke gegevens en er geen standaard is om dit te doen, de meeste onderzoekers typen gewoon korte beschrijvingen in de bestandsnaam. Dit kan logisch zijn voor de persoon die het bestand opslaat, maar voor anderen heeft het vaak weinig zin.
"Het ontbreken van echte metadatalabels veroorzaakt uiteindelijk problemen wanneer de wetenschapper de gegevens later probeert te vinden of probeert te delen met anderen, " zegt Lavanya Ramakrishnan, een stafwetenschapper in de Computational Research Division (CRD) van Berkeley Lab en co-hoofdonderzoeker van het Science Search-project. "Maar met machine learning-technieken, we kunnen computers laten helpen met wat omslachtig is voor de gebruikers, inclusief het toevoegen van tags aan de gegevens. Dan kunnen we die tags gebruiken om de gegevens effectief te doorzoeken."
Om het probleem met metadata aan te pakken, het Berkeley Lab-team gebruikt machine learning-technieken om het 'wetenschappelijke ecosysteem' te ontginnen, inclusief tijdstempels van instrumenten, faciliteit gebruikerslogboeken, wetenschappelijke voorstellen, publicaties en bestandssysteemstructuren—voor contextuele informatie. De collectieve informatie uit deze bronnen, inclusief tijdstempel van het experiment, opmerkingen over de gebruikte resolutie en filter en het verzoek van de gebruiker om tijd, alle bieden kritische contextuele informatie. Het Berkeley-labteam heeft een innovatieve softwarestack samengesteld die gebruikmaakt van machinale leertechnieken, waaronder natuurlijke taalverwerking, om contextuele trefwoorden over het wetenschappelijke experiment te trekken en automatisch metadatatags voor de gegevens te creëren.
Voor de proof-of-concept, Ophus deelde gegevens van de TEAM 1-elektronenmicroscoop van de Molecular Foundry bij NCEM die onlangs werden verzameld door het personeel van de faciliteit, met het Wetenschapszoekteam. Hij bood zich ook aan om een paar duizend afbeeldingen te labelen om de machine learning-tools een aantal labels te geven om van te leren. Hoewel dit een goed begin is, Gunther Weber, co-hoofdonderzoeker van Science Search, merkt op dat de meeste succesvolle machine learning-toepassingen doorgaans aanzienlijk meer gegevens en feedback nodig hebben om betere resultaten te leveren. Bijvoorbeeld, in het geval van zoekmachines zoals Google, Weber merkt op dat trainingsdatasets worden gemaakt en machine learning-technieken worden gevalideerd wanneer miljarden mensen over de hele wereld hun identiteit verifiëren door op alle afbeeldingen met straatnaamborden of winkelpuien te klikken nadat ze hun wachtwoord hebben ingetypt. of op Facebook wanneer ze hun vrienden taggen in een afbeelding.
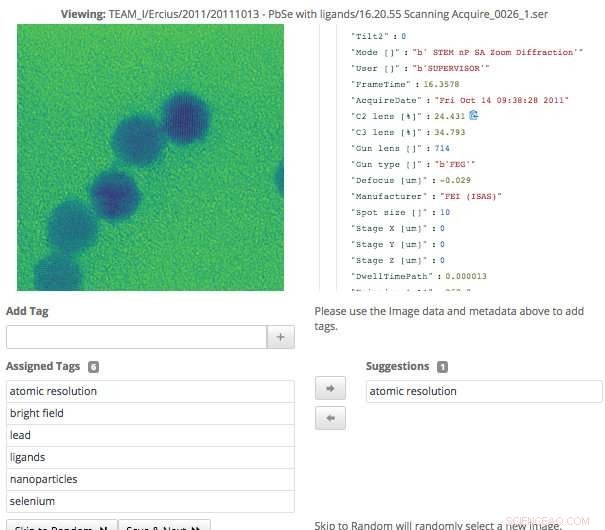
Deze schermopname van de Science Search-interface laat zien hoe gebruikers eenvoudig metadatatags kunnen valideren die zijn gegenereerd via machine learning, of voeg informatie toe die nog niet is vastgelegd. Krediet:Gonzalo Rodrigo, Berkeley Lab
"In het geval van wetenschappelijke gegevens kan slechts een handvol domeinexperts trainingssets maken en machine learning-technieken valideren, dus een van de grote problemen waarmee we worden geconfronteerd, is een extreem klein aantal trainingssets, " zegt Weber, die ook een stafwetenschapper is in het CRD van Berkeley Lab.
Om deze uitdaging te overwinnen, de onderzoekers van Berkeley Lab gebruikten transfer learning om de vrijheidsgraden te beperken, of parametertellingen, op hun convolutionele neurale netwerken (CNN's). Transfer learning is een machinale leermethode waarbij een voor een taak ontwikkeld model wordt hergebruikt als uitgangspunt voor een model voor een tweede taak, waardoor de gebruiker nauwkeurigere resultaten kan behalen met een kleinere trainingsset. In het geval van de TEAM I-microscoop, de geproduceerde gegevens bevatten informatie over de bedrijfsmodus van het instrument op het moment van verzamelen. Met die informatie, Weber was in staat om het neurale netwerk op die classificatie te trainen, zodat het dat bedrijfsmoduslabel automatisch kon genereren. Hij bevroor toen die convolutionele laag van het netwerk, wat betekende dat hij alleen de dicht aaneengesloten lagen opnieuw hoefde te trainen. Deze aanpak vermindert effectief het aantal parameters op de CNN, waardoor het team zinvolle resultaten kan behalen uit hun beperkte trainingsgegevens.
Machine Learning om het wetenschappelijke ecosysteem te ontginnen
Naast het genereren van metadatatags via trainingsdatasets, het Berkeley Lab-team ontwikkelde ook tools die machine learning-technieken gebruiken voor het ontginnen van het wetenschappelijke ecosysteem voor datacontext. Bijvoorbeeld, de module voor gegevensopname kan een groot aantal informatiebronnen uit het wetenschappelijke ecosysteem bekijken, waaronder tijdstempels van instrumenten, gebruikerslogboeken, voorstellen en publicaties - en identificeer overeenkomsten. Tools ontwikkeld door Berkeley Lab die natuurlijke taalverwerkingsmethoden gebruiken, kunnen vervolgens woorden identificeren en rangschikken die context geven aan de gegevens en later zinvolle resultaten voor gebruikers mogelijk maken. De gebruiker ziet iets dat lijkt op de resultatenpagina van een zoekopdracht op internet, waar inhoud met de meeste tekst die overeenkomt met de zoekwoorden van de gebruiker hoger op de pagina wordt weergegeven. Het systeem leert ook van gebruikersvragen en de zoekresultaten waarop ze klikken.
Omdat wetenschappelijke instrumenten een steeds groter wordende hoeveelheid gegevens genereren, alle aspecten van de wetenschappelijke zoekmachine van het Berkeley-team moesten schaalbaar zijn om gelijke tred te houden met de snelheid en schaal van de datavolumes die worden geproduceerd. Het team bereikte dit door hun systeem op te zetten in een Spin-instantie op de Cori-supercomputer van het National Energy Research Scientific Computing Center (NERSC). Spin is een op Docker gebaseerde edge-servicetechnologie die is ontwikkeld bij NERSC en die toegang heeft tot de krachtige computersystemen en opslag van de faciliteit aan de achterkant.
"Een van de redenen waarom het voor ons mogelijk is om een tool als Science Search te bouwen, is onze toegang tot bronnen bij NERSC, " zegt Gonzalo Rodrigo, een postdoctoraal onderzoeker van Berkeley Lab die werkt aan de uitdagingen op het gebied van natuurlijke taalverwerking en infrastructuur in Science Search. "We moeten opbergen, echt grote datasets analyseren en ophalen, en het is handig om toegang te hebben tot een supercomputerfaciliteit om het zware werk voor deze taken te doen. NERSC's Spin is een geweldig platform om onze zoekmachine te laten draaien, een gebruikersgerichte applicatie die toegang vereist tot grote datasets en analytische data die alleen kunnen worden opgeslagen op grote supercomputing-opslagsystemen."
Een interface voor het valideren en doorzoeken van gegevens
Toen het Berkeley Lab-team de interface ontwikkelde waarmee gebruikers met hun systeem kunnen communiceren, ze wisten dat het een aantal doelen moest bereiken, inclusief effectief zoeken en het toestaan van menselijke input voor de machine learning-modellen. Omdat het systeem afhankelijk is van domeinexperts om de trainingsgegevens te helpen genereren en de output van het machine learning-model te valideren, de interface die nodig is om dat te vergemakkelijken.
"De tagging-interface die we hebben ontwikkeld, geeft de oorspronkelijke beschikbare gegevens en metagegevens weer, evenals alle door machines gegenereerde tags die we tot nu toe hebben. Deskundige gebruikers kunnen vervolgens door de gegevens bladeren en nieuwe tags maken en eventuele door de machine gegenereerde tags op nauwkeurigheid controleren, " zegt Matt Henderson, die een Computer Systems Engineer is in CRD en leiding geeft aan de ontwikkeling van de gebruikersinterface.
Om een effectieve zoektocht naar gebruikers te vergemakkelijken op basis van beschikbare informatie, de zoekinterface van het team biedt een zoekmechanisme voor beschikbare bestanden, voorstellen en artikelen waaruit de door Berkeley ontwikkelde machine-learningtools tags hebben geparseerd en geëxtraheerd. Elk item in de lijst met zoekresultaten vertegenwoordigt een samenvatting van die gegevens, met een meer gedetailleerde secundaire weergave beschikbaar, inclusief informatie over tags die overeenkomen met dit item. Het team onderzoekt momenteel hoe gebruikersfeedback het beste kan worden verwerkt om de modellen en tags te verbeteren.
"Het vermogen om datasets te verkennen is belangrijk voor wetenschappelijke doorbraken, en dit is de eerste keer dat zoiets als Science Search is geprobeerd, " zegt Ramakrishnan. "Onze uiteindelijke visie is om de basis te bouwen die uiteindelijk een 'Google' voor wetenschappelijke gegevens zal ondersteunen, waar onderzoekers zelfs gedistribueerde datasets kunnen doorzoeken. Ons huidige werk biedt de basis die nodig is om tot die ambitieuze visie te komen."
"Berkeley Lab is echt een ideale plek om een tool als Science Search te bouwen, omdat we een aantal gebruikersfaciliteiten hebben, zoals de Moleculaire Gieterij, die tientallen jaren aan gegevens hebben die nog meer waarde zouden hebben voor de wetenschappelijke gemeenschap als de gegevens zouden kunnen worden doorzocht en gedeeld, " voegt Katie Antypas toe, die de hoofdonderzoeker is van Science Search en hoofd van de gegevensafdeling van NERSC. "Bovendien hebben we uitstekende toegang tot machine learning-expertise in het Berkeley Lab Computing Sciences Area, evenals HPC-bronnen bij NERSC om deze mogelijkheden te bouwen."
 W.African farm bootcamp brengt groene ondernemers in vorm
W.African farm bootcamp brengt groene ondernemers in vorm- Hawaï-onderzoekers ontvangen geld om koraalziekte in de Stille Oceaan te voorspellen
- De toekomst van hazelnoten:de economische waarde van subseizoensvoorspellingen
- Grondwaterpompen kunnen riviersystemen verwoesten
- Hoe de aardmantel is als een schilderij van Jackson Pollock
Hoofdlijnen
- Hebben alle mensen een uniek genotype en fenotype?
- Dissectie van één molecuul van ontwikkelingsgencontrole
- Dierentuin Praag viert gezondheid zeldzame Maleise tijgerwelpen
- Zeldzame olifanten redden met toeristische kiekjes
- Een enzym dat de vorming van het DNA katalyseert Molecuul
- Vier klassen Macromoleculen die belangrijk zijn voor levende wezens
- Hoe genenbanken werken
- Een modelhart maken met materialen uit uw huis
- Wat is een prehistorische toolkit en hoe zou het de menselijke geschiedenis kunnen herschrijven?
- Opkoopbod Tesla CEO doet wenkbrauwen fronsen juridische zorgen

- Facebook gaat regels voor politieke advertenties aanscherpen voor verkiezingen van 2019

- Mitsubishi Motors ontkent fraude met emissietests na Duitse invallen

- Studenten ontwikkelen gratis robotprogrammeersimulator

- Facebook-verkiezingsoorlogskamer wordt stil - voorlopig


 Bottom-up is de weg vooruit voor stikstofreductie bij instellingen
Bottom-up is de weg vooruit voor stikstofreductie bij instellingen- Eerste symbiotische ster gedetecteerd door Gaia-satelliet
- Eerste uitrol van Ariane 6 mobiele portaal
- Bacteriën kunnen reizen tussen aarde en Mars overleven bij het vormen van aggregaten
- Stamboom is niet het lot als het gaat om wetenschappelijk succes
- Verschillen tussen LNB en LNBF
- Radicalen splitsen
- Mangroven kunnen het tij keren op de koolstofproductie
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
