Wetenschap
Visuele semantiek maakt hoogwaardige plaatsherkenning mogelijk vanuit tegengestelde gezichtspunten

Krediet:Queensland University of Technology
QUT-onderzoekers hebben een nieuwe manier ontwikkeld voor robots om de wereld vanuit een meer menselijk perspectief te bekijken, die het potentieel heeft om de manier waarop technologie, zoals auto's zonder bestuurder en industriële en mobiele robots, werkt en communiceert met mensen.
In wat wordt beschouwd als een wereldprimeur, doctoraat student Sourav Garg, Dr. Niko Suenderhauf en professor Michael Milford van QUT's Science and Engineering Faculty en Australian Centre for Robotic Vision, hebben visuele semantiek gebruikt om hoogwaardige plaatsherkenning vanuit tegengestelde gezichtspunten mogelijk te maken.
De heer Garg zei:terwijl mensen een opmerkelijk vermogen hadden om een plaats te herkennen wanneer ze deze vanuit de tegenovergestelde richting binnenkwamen, ook in omstandigheden waar er extreme variaties zijn in het uiterlijk, de taak had uitdagingen opgeleverd voor robots en autonome voertuigen.
"Bijvoorbeeld, als een persoon op een weg rijdt en ze een u-bocht maken en teruggaan op dezelfde weg, in tegengestelde richting, ze hebben het vermogen om te weten waar ze zijn, op basis van die eerdere ervaring, omdat ze belangrijke aspecten van de omgeving herkennen. Dat kunnen mensen ook doen als ze 's nachts over dezelfde weg rijden, en dan weer overdag, of tijdens verschillende seizoenen, ' zei meneer Garg.
"Helaas, het is niet zo eenvoudig voor robots. Huidige technische oplossingen, zoals die worden gebruikt door zelfrijdende auto's, grotendeels afhankelijk zijn van panoramische camera's of 360 graden lichtdetectie en -bereik (LIDAR)-detectie. Hoewel dit effectief is, het is heel anders dan hoe mensen van nature navigeren.

Krediet:neyro2008 / Alexander Zelnitskiy / 123rf.com / auteurs
Professor Michael Milford zei dat het door het QUT-team van onderzoekers voorgestelde systeem een ultramodern semantisch segmentatienetwerk gebruikte, genaamd RefineNet, getraind op de Cityscapes-dataset, om een Local Semantic Tensor (LoST) descriptor van afbeeldingen te vormen. Dit werd vervolgens gebruikt om plaatsherkenning uit te voeren, samen met aanvullende robotvisietechnieken op basis van ruimtelijke lay-outverificatiecontroles en gewogen keypoint-matching.
"We wilden het proces repliceren dat door mensen wordt gebruikt. Visuele semantiek werkt niet alleen door te voelen, maar begrijpen waar de belangrijkste objecten zich in de omgeving bevinden, en dit zorgt voor een grotere voorspelbaarheid in de acties die volgen, ' zei professor Milford.
"Onze aanpak stelt ons in staat om plaatsen te matchen vanuit tegengestelde gezichtspunten met weinig gemeenschappelijke visuele overlap en over dag-nacht cycli. We breiden dit werk nu uit om zowel tegengestelde gezichtspunten als laterale gezichtspuntveranderingen aan te kunnen, die zich voordoet, bijvoorbeeld, wanneer een voertuig van rijstrook verandert. Dit voegt een extra moeilijkheidsgraad toe."

Tegoed:1 jaar, 1000 km:de Oxford RobotCar-gegevensset
Het artikel van het onderzoeksteam is geaccepteerd voor publicatie in Robotica:wetenschap en systemen , de meest selectieve internationale roboticaconferentie, die deze maand wordt gehouden aan de Carnegie Mellon University in Pittsburgh.
 Biomolecuul metaal-organische hybriden met hoge bioactiviteit
Biomolecuul metaal-organische hybriden met hoge bioactiviteit- Wetenschappers ontwikkelen eerste medicijnachtige verbindingen om ongrijpbare, aan kanker gerelateerde enzymen te remmen
- At Home Science: Naked Egg Experiment
- Bacteriën produceren goud door giftige metalen te verteren
- Ingenieurs vinden dat antioxidanten de visualisatie van polymeren op nanoschaal verbeteren
- Een primeur voor een uniek instrument
- Professor spoort wetenschappers aan om zich uit te spreken over klimaatverandering
- Bomen met grasvelden verzachten de zomerhitte
- Door de mens veroorzaakte aerosolen geïdentificeerd als drijvende kracht achter veranderende wereldwijde regenvalpatronen
- Nieuwe techniek voor simulatie van extreme weersomstandigheden
Hoofdlijnen
- Onderzoekers testen intelligentie van Afrikaanse grijze papegaai
- Overeenkomsten van mitose en meiose
- Bijen gebruiken onzichtbare warmtepatronen om bloemen te kiezen
- Ons begrip vergroten van de impact van verbindingen geproduceerd door bepaalde visparasieten
- Ja,
- Abiogenese: definitie, theorie, bewijs & voorbeelden
- Hoe een DNA-model te labelen
- Gen-experts gaan ongediertebestrijding aanpakken
- De nadelen van gelelektroforese
- Activisten dringen aan op verbod op moordende robots voordat het te laat is

- Fossielen achterlaten voor de toekomst van transport

- Een cyborg-kakkerlak kan ooit je leven redden

- Vierdimensionale microbouwstenen:afdrukbaar, tijd gerelateerd, programmeerbare tools
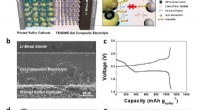
- Nieuwe studie presenteert volledig bedrukte bipolaire Li-S-batterijen in vaste toestand

 Meer vrouwen die zich kandidaat stellen voor een politiek ambt kunnen de kansen van kandidaten voor de ondergang schaden
Meer vrouwen die zich kandidaat stellen voor een politiek ambt kunnen de kansen van kandidaten voor de ondergang schaden- Apple biedt 2,5 miljard dollar om de huisvestingscrisis in Californië aan te pakken
- Hoe lateraal gebied te berekenen
- Expeditie haalt tonnen plastic uit afgelegen Hawaï-atollen
- Voormalig astronaut helpt bij verbreken vluchtrecord over palen
- Als landen de toezeggingen van Parijs met bezuinigingen op spuitbussen uitvoeren, miljoenen levens kunnen worden gered, onderzoekers zeggen:
- Ondanks de negatieve gevolgen, welwillend seksisme helpt bij het zoeken naar partner
- Nieuw algoritme vindt efficiënt antibioticakandidaten
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
