Wetenschap
Door machinaal leren ondersteund moleculair ontwerp voor hoogwaardige organische fotovoltaïsche materialen
Machine learning gebruiken om moleculair ontwerp te ondersteunen. Krediet:Wenbo Sun, wetenschappelijke vooruitgang, doi:10.1126/sciadv.aay4275
Om hoogwaardige materialen te synthetiseren voor organische fotovoltaïsche systemen (OPV's) die zonnestraling omzetten in gelijkstroom, materiaalwetenschappers moeten op een zinvolle manier de relatie tussen chemische structuren en hun fotovoltaïsche eigenschappen vaststellen. In een nieuwe studie over wetenschappelijke vooruitgang , Wenbo Sun en een team met onderzoekers van de School of Energy and Power Engineering, School voor automatisering, Computertechnologie, Elektrotechniek en Groene en Intelligente Technologie, een nieuwe database opgezet van meer dan 1, 700 donormaterialen met behulp van bestaande literatuurrapporten. Ze gebruikten gesuperviseerd leren met machine learning-modellen om structuur-eigenschaprelaties op te bouwen en OPV-materialen snel te screenen met behulp van een verscheidenheid aan invoer voor verschillende ML-algoritmen.
Het gebruik van moleculaire vingerafdrukken (codering van een structuur van een molecuul in binaire bits) met een lengte van meer dan 1000 bits Sun et al. behaalde een hoge ML-voorspellingsnauwkeurigheid. Ze verifieerden de betrouwbaarheid van de aanpak door 10 nieuw ontworpen donormaterialen te screenen op consistentie tussen modelvoorspellingen en experimentele resultaten. De ML-resultaten presenteerden een krachtig hulpmiddel om nieuwe OPV-materialen vooraf te screenen en de ontwikkeling van OPV's in materiaaltechnologie te versnellen.
Organische fotovoltaïsche (OPV) cellen kunnen directe en kosteneffectieve omzetting van zonne-energie in elektriciteit vergemakkelijken, met een snelle recente groei om de snelheid van de stroomconversie-efficiëntie (PCE) te overtreffen. Het reguliere OPV-onderzoek heeft zich gericht op het leggen van een verband tussen nieuwe moleculaire structuren van OPV en hun fotovoltaïsche eigenschappen. Het traditionele proces omvat typisch het ontwerp en de synthese van fotovoltaïsche materialen voor de assemblage/optimalisatie van fotovoltaïsche cellen. Dergelijke benaderingen resulteren in tijdrovende onderzoekscycli die delicate controle van chemische synthese en fabricage van apparaten vereisen, experimentele stappen en zuivering. Het bestaande OPV-ontwikkelingsproces is traag en inefficiënt met tot nu toe minder dan 2000 OPV-donormoleculen die zijn gesynthetiseerd en getest. Echter, de gegevens die zijn verzameld uit tientallen jaren van onderzoekswerk zijn van onschatbare waarde, met potentiële waarden die nog volledig moeten worden onderzocht om hoogwaardige OPV-materialen te genereren.
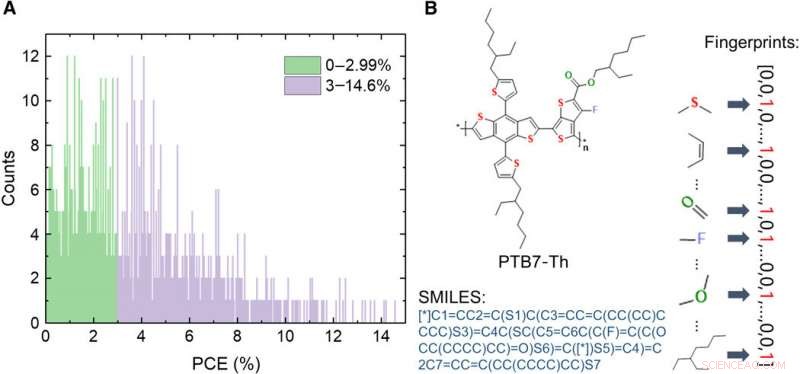
Informatie over de database van OPV donormaterialen. (A) Verdeling van PCE-waarden van de 1719 moleculen in de database. (B) Schema's van uitdrukkingen van een molecuul, inclusief afbeelding, vereenvoudigd line-entry-systeem met moleculaire invoer (SMILES), en vingerafdrukken. Krediet:wetenschappelijke vooruitgang, doi:10.1126/sciadv.aay4275
Om nuttige informatie uit de gegevens te halen, Zon et al. vereist een geavanceerd programma om door een grote dataset te scannen en relaties uit de functies te halen. Aangezien machine learning (ML) computationele hulpmiddelen biedt om patronen en relaties te leren en te herkennen met behulp van een trainingsdataset, het team gebruikte een datagestuurde aanpak om ML mogelijk te maken en diverse materiaaleigenschappen te voorspellen. Het ML-algoritme hoefde de chemie of fysica achter de materiaaleigenschappen niet te begrijpen om de taken te volbrengen. Vergelijkbare methoden hebben onlangs de activiteit/eigenschappen van materialen met succes voorspeld tijdens het ontdekken van materialen, medicijnontwikkeling en materiaalontwerp. Voorafgaand aan ML-toepassingen, wetenschappers hadden cheminformatica ontwikkeld om een bruikbare toolbox op te zetten.
Materiaalwetenschappers hebben pas onlangs de toepassingen van ML op het gebied van OPV onderzocht. In het huidige werk, Zon et al. een database opgezet met 1719 experimenteel geteste donor-OPV-materialen verzameld uit de literatuur. Ze bestudeerden eerst het belang van programmeertaalexpressie van de moleculen om ML-prestaties te begrijpen. Vervolgens testten ze verschillende soorten uitdrukkingen, waaronder afbeeldingen, ASCII-snaren, twee soorten descriptoren en zeven soorten moleculaire vingerafdrukken. Ze zagen dat de modelvoorspellingen goed overeenkwamen met de experimentele resultaten. De wetenschappers verwachten dat de nieuwe aanpak de ontwikkeling van nieuwe en zeer efficiënte organische halfgeleidermaterialen voor OPV-onderzoekstoepassingen aanzienlijk zal versnellen.
Het onderzoeksteam heeft de ruwe data eerst omgezet in een machineleesbare weergave. Er bestaat een verscheidenheid aan uitdrukkingen voor hetzelfde molecuul die enorm verschillende chemische informatie bevatten die op verschillende abstracte niveaus wordt gepresenteerd. Met behulp van een reeks ML-modellen, Zon et al. verschillende expressies van een molecuul verkend door hun voorspelde nauwkeurigheid voor stroomconversie-efficiëntie (PCE) te vergelijken om een diepgaande modelnauwkeurigheid van 69,41 procent te verkrijgen. De relatief onbevredigende prestatie was te wijten aan de kleine omvang van de database. Bijvoorbeeld, eerder toen dezelfde groep een groter aantal moleculen tot 50 gebruikte, 000, de nauwkeurigheid van het deep-learningmodel overschreed 90 procent. Om een deep learning-model volledig te trainen, onderzoekers moeten een grotere database implementeren met miljoenen monsters.
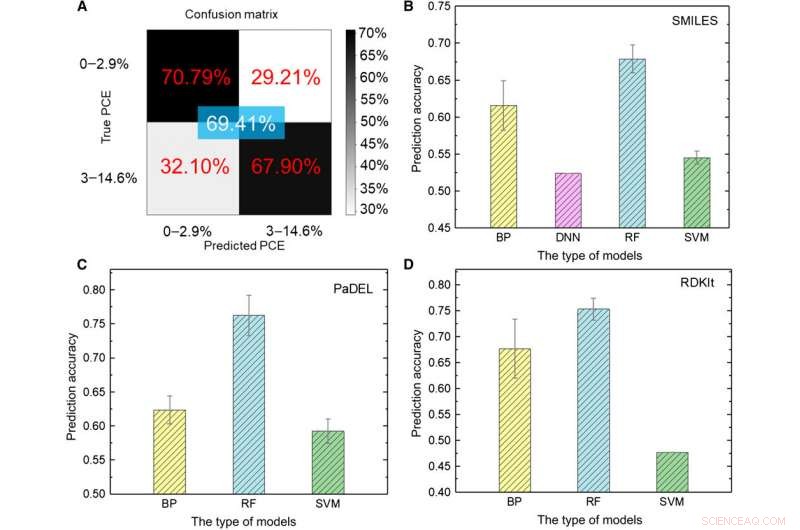
Testresultaten van ML-modellen. (A) Testen van het deep learning-model met afbeeldingen als invoer. (B tot D) Testresultaten van verschillende ML-modellen met (B) SMILES, (C) PADEL, en (D) RDKIt-descriptoren als invoer. Krediet:wetenschappelijke vooruitgang, doi:10.1126/sciadv.aay4275
Zon et al. had op dit moment slechts honderden moleculen in elke categorie, waardoor het voor het model moeilijk is om voldoende informatie te extraheren voor een hogere nauwkeurigheid. Hoewel het mogelijk is om een vooraf getraind model te verfijnen om de benodigde hoeveelheid gegevens te verminderen, duizenden monsters zijn nog steeds nodig om een voldoende aantal functies te bereiken. Dit leidde tot de mogelijkheid om de database te vergroten bij het gebruik van afbeeldingen om moleculen tot expressie te brengen.
De wetenschappers gebruikten vijf soorten gesuperviseerde ML-algoritmen in het onderzoek, inclusief (1) terugpropagatie (BP) neuraal netwerk (BPNN), (2) diep neuraal netwerk (DNN), (3) diep leren, (4) support vector machine (SVM) en (5) random forest (RF). Dit waren geavanceerde algoritmen, waar BPNN, DNN en deep learning waren gebaseerd op het kunstmatige neutrale netwerk (ANN). De SMILES-code (vereenvoudigd moleculaire invoerregelinvoersysteem) zorgde voor een andere originele uitdrukking van een molecuul, die Sun et al. gebruikt als invoer voor vier modellen. Op basis van de resultaten, de hoogste nauwkeurigheid bedroeg 67,84 procent voor het RF-model. Zoals eerder, in tegenstelling tot diep leren, de vier klassieke methoden konden geen verborgen kenmerken extraheren. Als geheel, SMILES presteerde slechter dan afbeeldingen als descriptoren van moleculen om de PCE-klasse (stroomconversie-efficiëntie) in de gegevens te voorspellen.
De onderzoekers gebruikten vervolgens moleculaire descriptoren die de eigenschappen van een molecuul kunnen beschrijven met behulp van een reeks getallen in plaats van de directe uitdrukking van een chemische structuur. Het onderzoeksteam gebruikte twee soorten descriptoren PaDEL en RDKIt in het onderzoek. Na uitgebreide analyses van alle ML-modellen, een grote gegevensomvang impliceerde meer descriptoren die niet relevant waren voor PCE en die de ANN-prestaties beïnvloeden. Ter vergelijking, een kleine gegevensomvang impliceerde inefficiënte chemische informatie om ML-modellen effectief te trainen, bij het gebruik van moleculaire descriptoren als input in ML-benaderingen, de sleutel was gebaseerd op het vinden van geschikte descriptors die direct verband hielden met het doelobject.
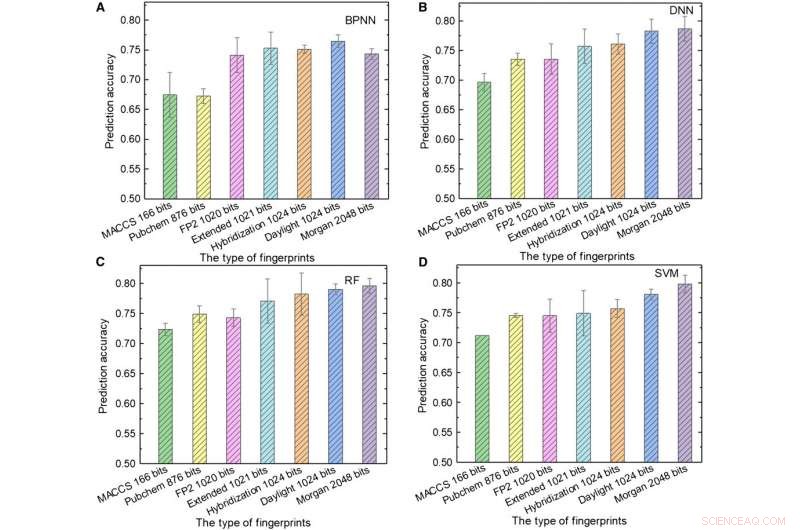
Prestaties van ML-modellen. (A t/m D) De testresultaten van (A) BPNN, (B)DNN, (C) RF, en (D) SVM gebruikt verschillende soorten vingerafdrukken als invoer. Krediet:wetenschappelijke vooruitgang, doi:10.1126/sciadv.aay4275.
Het team gebruikte vervolgens moleculaire vingerafdrukken; meestal ontworpen om moleculen weer te geven als wiskundige objecten en oorspronkelijk gemaakt om isomeren te identificeren. Tijdens grootschalige databasescreening het concept wordt weergegeven als een array van bits die "1" en "0" s bevatten om de aan- of afwezigheid van specifieke substructuren of patronen in de moleculen te beschrijven. Zon et al. gebruikte zeven soorten vingerafdrukken als invoer om de ML-modellen te trainen en hield rekening met de invloed van de lengte van de vingerafdruk op de voorspellingsprestaties van verschillende modellen om verschillende vingerafdrukken te verkrijgen. Bijvoorbeeld, vingerafdrukken van het moleculair toegangssysteem (MACCS) bevatten 166 bits en waren de kortste invoer en de resultaten waren onbevredigend vanwege hun beperkte informatie.
Zon et al. toonde de beste combinatie van programmeertaal en ML-algoritme verkregen met behulp van hybridisatievingerafdrukken van 1024 bits en RF, een voorspellingsnauwkeurigheid van 81,76 procent behalen; waarbij hybridisatie-vingerafdrukken SP2-hybridisatietoestanden van moleculen vertegenwoordigden. Toen de lengte van de vingerafdruk toenam van 166 naar 1024 bits, de prestaties van alle ML-modellen verbeterden omdat langere vingerafdrukken meer chemische informatie bevatten.
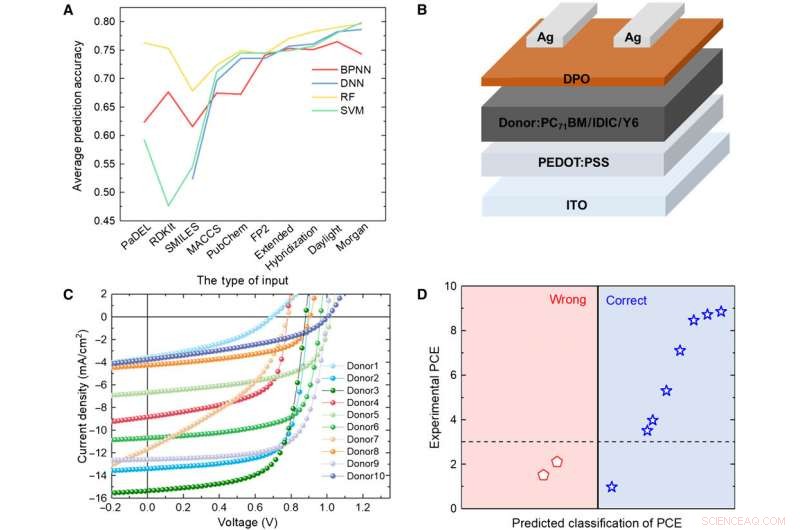
Verificatie van ML-modellen met experiment. (A) vergelijking van de resultaten van vier verschillende modellen. (B) Schematisch diagram van de celarchitectuur die in deze studie wordt gebruikt. (C) J-V-curve van de zonnecel met de actieve laag met behulp van het voorspelde donormateriaal. (D) Voorspellingsresultaten versus experimentele gegevens voor de voorspelde donormaterialen met het RF-algoritme en daglichtvingerafdrukken. Krediet:wetenschappelijke vooruitgang, doi:10.1126/sciadv.aay4275.
Om de betrouwbaarheid van de ML-modellen te testen, Zon et al. 10 nieuwe OPV-donormoleculen gesynthetiseerd. Gebruikte vervolgens drie representatieve vingerafdrukken om de chemische structuur van de nieuwe moleculen uit te drukken en vergeleek de resultaten voorspeld door het RF-model en de experimentele PCE-waarden. Het systeem classificeerde acht van de 10 moleculen. De resultaten wezen op het potentieel van de synthetische materialen voor OPV-toepassingen met aanvullende experimentele optimalisatie voor twee van de nieuwe materialen. Een kleine wijziging in de structuur kan een groot verschil in PCE-waarden veroorzaken. bemoedigend, de ML-modellen identificeerden dergelijke kleine wijzigingen om gunstige voorspellingsresultaten te vergemakkelijken.
Op deze manier, Wenbo Sun en collega's gebruikten een literatuurdatabase over OPV-donormaterialen en een verscheidenheid aan programmeertaaluitdrukkingen (afbeeldingen, ASCII-snaren, descriptoren en moleculaire vingerafdrukken) om ML-modellen te bouwen en de bijbehorende OPV PCE-klasse te voorspellen. Het team demonstreerde een schema om OPV-donormaterialen te ontwerpen met behulp van ML-benaderingen en experimentele analyse. Ze hebben een groot aantal donormaterialen vooraf gescreend met behulp van het ML-model om toonaangevende kandidaten voor synthese en verdere experimenten te identificeren. Het nieuwe werk kan het ontwerp van nieuw donormateriaal versnellen om de ontwikkeling van hoge PCE OPV's te versnellen. Het gebruik van ML in combinatie met experimenten zal de ontdekking van materialen bevorderen.
© 2019 Wetenschap X Netwerk
 Omkeerbare chemie maakt pad vrij voor veiligere batterijen
Omkeerbare chemie maakt pad vrij voor veiligere batterijen- In levende kleur:cellen van buiten het lichaam zien met synthetische bioluminescentie
- Antibioticaresistentie verlichten:onderzoekers zetten stappen in de richting van een nieuwe behandeling voor E. coli
- Het belang van Boyles Gas Law in het dagelijks leven
- Het pad verlichten naar het recyclen van koolstofdioxide
- Onbedoeld vrijkomen van methaan uit Britse schaliegaslocatie gelijk aan 142 trans-Atlantische vluchten
- Onderzoek suggereert drie periodes van vertraging van de opwarming van de aarde sinds 1891 als gevolg van natuurlijke tijdelijke oorzaken
- Hoe regenwormen zichzelf beschermen
- Een gemeenschap in Californië laat zien hoe je afval uit het water haalt
- Een verband leggen tussen luchtvervuiling en dementie
Hoofdlijnen
- 10 verschillende soorten lachen
- Hoe evolueert de mens?
- Nieuwe high-throughput sequencing-technologieën onthullen een wereld van op elkaar inwerkende micro-organismen
- Your Brain On: An All Nighter
- Verander je geliefde in een boom met Bios Urn
- Wat is een endotherme reactie?
- De circadiane klok bepaalt het tempo van de plantengroei
- De rol van GTE in DNA-extractie
- Hoe de immuunrespons bijdraagt aan Homeostasis
- Nieuwe fotoakoestische techniek detecteert gassen op het niveau van deeltjes per quadriljoen

- Voordelen van herstellend plasma voor COVID-19 zijn nog onduidelijk
- Je eten kan helpen om plakkeriger, veiligere lijmen voor laptops, verpakking, meubilair

- Video:Hoe kook je een ei zonder hitte - en andere rare eierwetenschap

- Niet-gechloreerde, met oplosmiddel verwerkte hoogwaardige ambipolaire transistors


 Nieuw metamateriaal verandert in nieuwe vormen, nieuwe panden aannemen
Nieuw metamateriaal verandert in nieuwe vormen, nieuwe panden aannemen- In de cleanroom met baanbrekende GOES-R next-gen weersatelliet
- Franse onderzoeker hackt nieuw e-voting systeem in Moskou
- Stone tool vertelt het verhaal van de jacht op de Neanderthalers
- Tweedimensionaal materiaal lijkt te verdwijnen, maar niet
- Hoe interageert de door de stad veroorzaakte opwarming in Beijing met de luchttemperatuur in de zomer?
- Aboriginal littekens van grensoorlogen
- Mysterieuze kosmische explosie verrast astronomen die het verre röntgenuniversum bestuderen
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
