Wetenschap
Hoe een wetenschapper een tweetraps waarschuwingssysteem voor zonnevlammen heeft opgezet
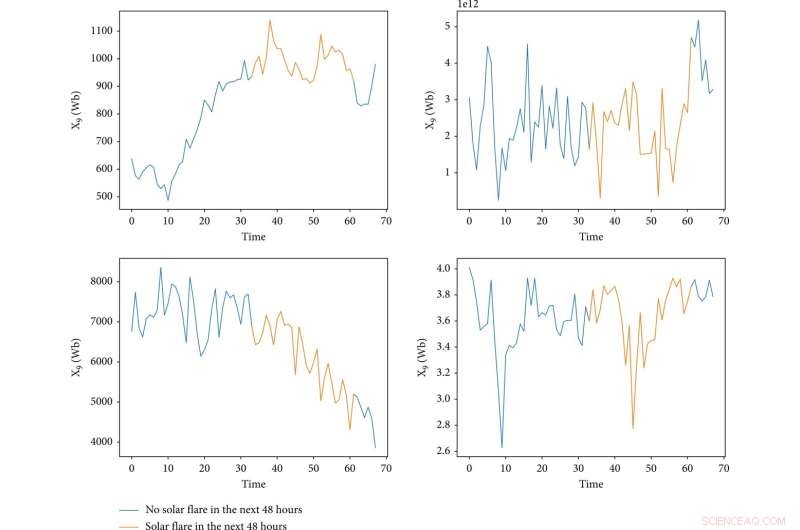
De visualisatie van vier kenmerken tijdens het bestaan van een actieve regio. De x-as vertegenwoordigt tijd en de eenheid ervan is een steekproef, waarbij "0" de starttijd van een actief gebied vertegenwoordigt en het tijdsverschil tussen aangrenzende tijden 1,5 h is. De y-as vertegenwoordigt de waarde van een kenmerk. De blauwe lijnen geven aan dat er de komende 48 uur geen zonnevlam is, en de gele lijnen zijn het tegenovergestelde. Credit:Ruimte:wetenschap en technologie
Zonnevlammen zijn zonnestormen die worden aangedreven door een magnetisch veld in het zonneactiviteitsgebied. Wanneer deze flare-straling in de buurt van de aarde komt, verhoogt de foto-ionisatie de elektronendichtheid in de D-laag van de ionosfeer, wat absorptie van hoogfrequente radiocommunicatie, scintillatie van satellietcommunicatie en versterkte interferentie van achtergrondgeluid met radar veroorzaakt.
Statistieken en ervaring tonen aan dat hoe groter de uitbarsting, hoe waarschijnlijker het is dat deze gepaard gaat met andere zonne-uitbarstingen zoals een zonne-protongebeurtenis, en hoe ernstiger de effecten op de aarde, waardoor ruimtevlucht, communicatie, navigatie, krachtoverbrenging en andere technologische systemen.
Het verstrekken van voorspellingsinformatie over de waarschijnlijkheid en intensiteit van uitbraken van fakkels is een belangrijk element aan het begin van operationele ruimteweersvoorspellingen. De modelleringsstudie van het voorspellen van zonnevlammen is een noodzakelijk onderdeel van nauwkeurige fakkelvoorspelling en heeft een belangrijke toepassingswaarde. In een onderzoekspaper dat onlangs is gepubliceerd in Space:Science &Technology , Hong Chen van College of Science, Huazhong Agricultural University, combineerde het k-means clustering-algoritme en verschillende CNN-modellen om een waarschuwingssysteem te bouwen dat kan voorspellen of er in de komende 48 uur een zonnevlam zal plaatsvinden.
Eerst introduceerde de auteur de gegevens die in het artikel werden gebruikt en analyseerde ze vanuit statistisch oogpunt om een basis te leggen voor het ontwerp van het waarschuwingssysteem voor zonnevlammen. Om het projectie-effect te verminderen, werd het midden van het actieve gebied binnen ± 30° van het centrum van de zonneschijf geselecteerd. Daarna labelde de auteur de gegevens volgens de zonnevlamgegevens van NOAA, inclusief de begin- en eindtijden van de fakkels, het nummer van het actieve gebied, de omvang van de fakkels, enz.
Er was een ernstige onbalans tussen het aantal positieve en negatieve monsters in de dataset. Om de onbalans van positieve en negatieve monsters te verminderen, werd een principe gevonden om de gebeurtenissen met positieve monsters zoveel mogelijk te selecteren. De auteur visualiseerde de kansdichtheidsverdeling van elk kenmerk in alle negatieve monsters en alle positieve monsters. Het kon gemakkelijk worden gevonden dat de kansdichtheidsverdelingen van de negatieve steekproeven allemaal negatief scheve verdelingen waren en dat de kenmerken van positieve steekproeven over het algemeen groter waren dan die van negatieve steekproeven. Het was dus mogelijk om gebeurtenissen met positieve steekproeven eruit te filteren op de kenmerkwaarden van elke gebeurtenis.
Daarna bouwde de auteur de hele pijplijn met een methode die de volgende twee stappen bevat:gegevensvoorverwerking en modeltraining. Om gegevens voorverwerking uit te voeren, werd K-means, een niet-gesuperviseerde clustermethode, gebruikt om gebeurtenissen te clusteren om gebeurtenissen die alleen negatieve monsters bevatten zoveel mogelijk te verminderen.
Na clustering van k-means werden alle gebeurtenissen verdeeld in drie categorieën, namelijk categorie A, categorie B en categorie C. De auteur ontdekte dat de verhouding van positieve monsters in categorie C 0,340633 is, wat veel groter is dan die van de hele dataset. Daarom werden alleen de gegevens in categorie C gekozen als invoergegevens voor de volgende fase van het algoritme.
In de 2e fase waren de neurale netwerken die de auteur gebruikte Resnet18, Resnet34 en Xception, die vaak worden gebruikt bij deep learning. Driekwart van de monsters in categorie C werd willekeurig gekozen. In elk geval waren trainingsgegevens voor de neurale netwerkmodellen en de rest van de monsters werden beschouwd als validatiegegevens in het proces van het trainingsmodel.
Om de invloed van dimensie te vermijden, heeft de auteur ook de originele gegevens gestandaardiseerd. De standaardisatiemethode was anders dan de gebruikelijke. Volgens de standaardisatieberekeningsformule, als het label van een monster werd voorspeld als 1 door het neurale netwerk, werd dit monster beschouwd als een signaal van zonnevlam die in de komende 48 uur zou optreden. Maar als wordt voorspeld dat het 0 is, zou de kans op zonnevlammen in de komende 48 uur zo klein zijn dat het genegeerd zou kunnen worden.
Vervolgens voerde de auteur experimenten uit en besprak hij de resultaten. De auteur gaf eerst een introductie van de experimentele setting en voerde vervolgens verschillende ablatie-experimenten en vergelijkingen met verschillende modellen uit om de verbetering van het k-means-clusteralgoritme en de booststrategie te verifiëren. Bovendien maakte de auteur ook vergelijkingen tussen de methode die in het experiment werd gebruikt en andere 13 binaire classificatie-algoritmen die gewoonlijk worden gebruikt om de voorspellingsprestaties te presenteren.
De experimentele resultaten toonden aan dat de voorspellingsprestaties van het model waarin verschillende neurale netwerken waren geïntegreerd, beter waren dan die van een enkel convolutief neuraal netwerk. Ten slotte werden de voorspellingsresultaten van Resnet18, Resnet34 en Xception gecombineerd door de strategie te versterken. Voor alle netwerken kan de recall na clustering onveranderd of zelfs sterk verminderd zijn. De precisie zou echter aanzienlijk toenemen.
Na clustering zou, hoewel de positieve bemonsteringsfrequentie sterk zou worden verbeterd, van 5% naar 34%, ook bijna 40% van de informatie van positieve monsters verloren gaan. De auteur dacht dat dit de belangrijkste reden was waarom de herinnering gelijk bleef of zelfs daalde. Het betekende ook dat het aantal voorspelde positieve monsters in het experiment kleiner was dan het aantal zonder clustering, maar de kans dat een voorspeld positief monster echt positief was, was groter.
In contrast with the phenomenon that the prediction performance of other binary classification methods was decreasing or even very poor after clustering, the performance of the author's method improved by more than 9% after clustering. In conclusion, the two-stage solar flare early warning system consisted of an unsupervised clustering algorithm (k-means) and several CNN models, where the former was to increase the positive sample rate, and the latter integrated the prediction results of the CNN models to improve the prediction performance.
The results of the experiment proved the effectiveness of the method. + Verder verkennen
How scientist applied the recommendation algorithm to anticipate CMEs' arrival times
 Detectie van antilichamen met gloeiende eiwitten, draad en een smartphone
Detectie van antilichamen met gloeiende eiwitten, draad en een smartphone- Zelfassemblerende moleculen kunnen helpen bij kankertherapie
- Voor lithiummetaal, kleiner is sterker
- Patroonherkenning van chemische golven in de chemische reactie van Belousov-Zhabotinsky
- Oplossing voor raadselachtig fenomeen kan de deur openen naar verbeterde koude sproei-efficiëntie
Hoofdlijnen
- Ogen in de lucht gebruiken om zeehonden te lokaliseren in een snel veranderend noordpoolgebied
- Welke stadia zijn er in de mitochondriën?
- Onderzoekers rapporteren tandeloze bevindingen in odontode-dragende meervalstudie
- Ontdekking van eiwit dat de celwandmechanica van planten regelt
- Polygene eigenschappen: definitie, voorbeeld en feiten
- Koloniekenmerken van E.Coli
- Cowpea beschermd tegen een verwoestende plaag, gratis voor kleine Afrikaanse boeren
- Hoe te metaboliseren glucose om ATP te maken
Energie opgeslagen in de chemische bindingen van de koolhydraat-, vet- en eiwitmoleculen in levensmiddelen. Het proces van spijsvertering breekt koolhydraatmoleculen af in glucosemoleculen. Glucose die
- Welke organellen bevinden zich in een prokaryote cel?
- NASA voedt voor de eerste keer maanraket tijdens aftelrepetitie

- NASA's mixtape voor buitenaardse beschavingen

- ESA-astronaut Samantha Cristoforetti wordt eerste Europese vrouwelijke ISS-commandant

- NASA-wetenschappers zien asteroïde door de ogen van een robot

- Wil je meedoen aan de uitdaging om de maan te verkennen?

 Waarom smelt het poolijs 50 jaar te snel?
Waarom smelt het poolijs 50 jaar te snel? - Onderzoekers creëren een gebruiksvriendelijke, rekenkundige zoekinterface
- NASA's Maven observeert de nachtelijke hemel op Mars die pulseert in ultraviolet licht
- Onderzoekers modelleren hoe veranderingen in het klimaat, sociaaleconomische status zal waarschijnlijk van invloed zijn op de gezondheidsresultaten in Afrika bezuiden de Sahara
- Wat is een ionische verbinding?
- Astrofysici bestuderen asteroïde 3200 Phaethon
- Begrafenispraktijken wijzen op een onderling verbonden vroegmiddeleeuws Europa
- Afbeelding:Tenoumer Crater, Mauritanië
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
