Wetenschap
Onderzoeker ontwikkelt een chatbot met expertise in nanomaterialen

Een onderzoeker heeft zojuist een wetenschappelijk artikel geschreven. Ze weet dat haar werk baat zou kunnen hebben bij een ander perspectief. Heeft ze iets over het hoofd gezien? Of misschien is er een toepassing van haar onderzoek waar ze nog niet aan had gedacht. Een tweede paar ogen zou geweldig zijn, maar zelfs de vriendelijkste medewerkers kunnen misschien niet de tijd vrijmaken om alle benodigde achtergrondpublicaties te lezen om bij te praten.
Kevin Yager – leider van de elektronische nanomaterialengroep bij het Center for Functional Nanomaterials (CFN), een Office of Science User Facility van het Amerikaanse Department of Energy (DOE) in het Brookhaven National Laboratory van DOE – heeft zich voorgesteld hoe recente ontwikkelingen op het gebied van kunstmatige intelligentie (AI) en machine learning (ML) kan wetenschappelijke brainstorming en ideevorming ondersteunen. Om dit te bereiken heeft hij een chatbot ontwikkeld met kennis van de soorten wetenschap waarmee hij zich bezighoudt.
De snelle vooruitgang op het gebied van AI en ML heeft plaatsgemaakt voor programma's die creatieve tekst en nuttige softwarecode kunnen genereren. Deze algemene chatbots hebben onlangs tot de publieke verbeelding gesproken. Bestaande chatbots – gebaseerd op grote, diverse taalmodellen – ontberen gedetailleerde kennis van wetenschappelijke subdomeinen.
Door gebruik te maken van een methode voor het ophalen van documenten, heeft de bot van Yager kennis op gebieden van nanomateriaalwetenschap die andere bots niet hebben. De details van dit project en hoe andere wetenschappers deze AI-collega kunnen inzetten voor hun eigen werk zijn onlangs gepubliceerd in Digital Discovery .
Opkomst van de robots
"CFN onderzoekt al lange tijd nieuwe manieren om AI/ML in te zetten om de ontdekking van nanomaterialen te versnellen. Momenteel helpt het ons snel monsters te identificeren, catalogiseren en kiezen, experimenten te automatiseren, apparatuur te controleren en nieuwe materialen te ontdekken. Esther Tsai, een wetenschapper in de elektronische nanomaterialengroep bij CFN, ontwikkelt een AI-metgezel om materiaalonderzoeksexperimenten bij de National Synchrotron Light Source II (NSLS-II) te helpen versnellen." NSLS-II is een andere DOE Office of Science-gebruikersfaciliteit in Brookhaven Lab.
Bij CFN is er veel werk verricht op het gebied van AI/ML, dat kan helpen bij het stimuleren van experimenten door het gebruik van automatisering, besturingselementen, robotica en analyse, maar het hebben van een programma dat bedreven was in wetenschappelijke teksten was iets dat onderzoekers nog niet hadden onderzocht. zo diep. Het snel kunnen documenteren, begrijpen en overbrengen van informatie over een experiment kan op een aantal manieren helpen:van het slechten van taalbarrières tot het besparen van tijd door grotere stukken werk samen te vatten.
Let op je taalgebruik
Om een gespecialiseerde chatbot te bouwen, had het programma domeinspecifieke tekst nodig:taal uit de gebieden waarop de bot zich moet concentreren. In dit geval betreft het wetenschappelijke publicaties. Domeinspecifieke tekst helpt het AI-model nieuwe terminologie en definities te begrijpen en introduceert grensverleggende wetenschappelijke concepten. Het allerbelangrijkste is dat deze samengestelde reeks documenten het AI-model in staat stelt zijn redenering te onderbouwen met behulp van betrouwbare feiten.
Om de natuurlijke menselijke taal na te bootsen, worden AI-modellen getraind op bestaande tekst, waardoor ze de structuur van taal kunnen leren, verschillende feiten kunnen onthouden en een primitief soort redenering kunnen ontwikkelen. In plaats van het AI-model moeizaam te herscholen op basis van nanowetenschapsteksten, gaf Yager het de mogelijkheid om relevante informatie op te zoeken in een samengestelde reeks publicaties. Het voorzien van een bibliotheek met relevante gegevens was slechts de helft van de strijd. Om deze tekst nauwkeurig en effectief te gebruiken, heeft de bot een manier nodig om de juiste context te ontcijferen.
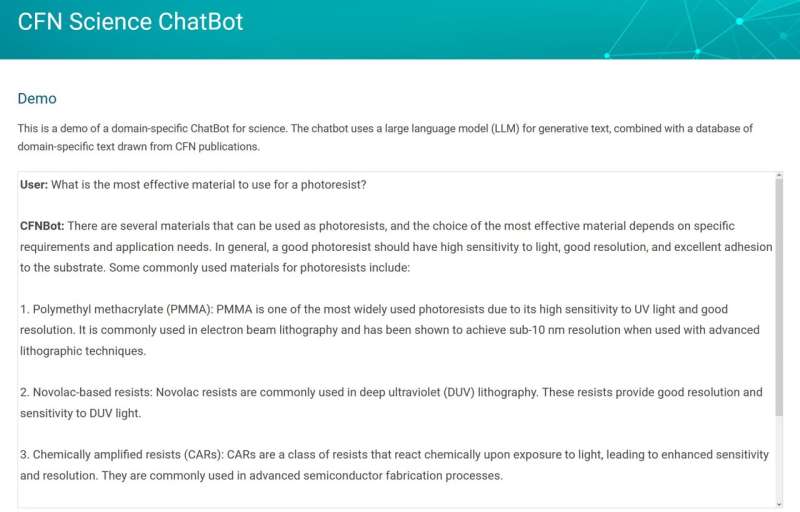
"Een uitdaging die veel voorkomt bij taalmodellen is dat ze soms plausibel klinkende maar onware dingen 'hallucineren'", legt Yager uit. "Dit was een kernprobleem dat moest worden opgelost voor een chatbot die in onderzoek wordt gebruikt, in tegenstelling tot een chatbot die zoiets doet als het schrijven van poëzie. We willen niet dat deze feiten of citaten verzint. Dit moest worden aangepakt. De oplossing hiervoor was iets dat we noemen we 'embedding', een manier om informatie achter de schermen snel te categoriseren en te koppelen."
Inbedding is een proces dat woorden en zinsdelen omzet in numerieke waarden. De resulterende "inbeddingsvector" kwantificeert de betekenis van de tekst. Wanneer een gebruiker de chatbot een vraag stelt, wordt deze ook naar het ML-inbeddingsmodel gestuurd om de vectorwaarde ervan te berekenen. Deze vector wordt gebruikt om te zoeken in een vooraf berekende database met tekstfragmenten uit wetenschappelijke artikelen die op vergelijkbare wijze zijn ingebed. De bot gebruikt vervolgens gevonden tekstfragmenten die semantisch gerelateerd zijn aan de vraag om een vollediger inzicht in de context te krijgen.
De zoekopdracht van de gebruiker en de tekstfragmenten worden gecombineerd tot een "prompt" die naar een groot taalmodel wordt gestuurd, een uitgebreid programma dat tekst creëert die is gemodelleerd naar natuurlijke menselijke taal en dat het uiteindelijke antwoord genereert. De inbedding zorgt ervoor dat de tekst die wordt opgehaald relevant is in de context van de vraag van de gebruiker. Door tekstfragmenten uit de hoofdtekst van vertrouwde documenten aan te bieden, genereert de chatbot antwoorden die feitelijk en afkomstig zijn.
"Het programma moet een soort referentiebibliothecaris zijn", zegt Yager. “Het moet sterk afhankelijk zijn van de documenten om gefundeerde antwoorden te geven. Het moet nauwkeurig kunnen interpreteren wat mensen vragen en in staat zijn om de context van die vragen effectief samen te voegen om de meest relevante informatie te achterhalen. Hoewel de antwoorden dat misschien niet zijn Als het nog niet perfect is, kan het al uitdagende vragen beantwoorden en interessante gedachten opwekken terwijl je nieuwe projecten en onderzoek plant."
Bots die mensen sterker maken
CFN ontwikkelt AI/ML-systemen als hulpmiddelen die menselijke onderzoekers de tijd kunnen geven om aan meer uitdagende en interessante problemen te werken en meer uit hun beperkte tijd te halen, terwijl computers repetitieve taken op de achtergrond automatiseren. Er zijn nog veel onduidelijkheden over deze nieuwe manier van werken, maar deze vragen vormen het begin van belangrijke discussies die wetenschappers momenteel voeren om ervoor te zorgen dat het gebruik van AI/ML veilig en ethisch is.
"Er zijn een aantal taken die een domeinspecifieke chatbot als deze zou kunnen ontnemen aan de werklast van een wetenschapper. Het classificeren en organiseren van documenten, het samenvatten van publicaties, het aanwijzen van relevante informatie en het op de hoogte raken van een nieuw onderwerp zijn slechts enkele mogelijkheden. toepassingen”, merkte Yager op. "Ik ben echter benieuwd waar dit allemaal naartoe zal gaan. Drie jaar geleden hadden we ons nooit kunnen voorstellen waar we nu staan, en ik kijk er naar uit waar we over drie jaar zullen staan."
Voor onderzoekers die deze software zelf willen uitproberen:de broncode voor de chatbot van CFN en de bijbehorende tools is te vinden in deze GitHub-repository.
Meer informatie: Kevin G. Yager, Domeinspecifieke chatbots voor de wetenschap met behulp van insluitingen, Digital Discovery (2023). DOI:10.1039/D3DD00112A
Geleverd door Brookhaven National Laboratory
 Onderzoeker verdiept zich in plaque-veroorzakende eiwitten bij ALS en dementie
Onderzoeker verdiept zich in plaque-veroorzakende eiwitten bij ALS en dementie- De ontdekking van een nieuwe vouw van plantaardige eiwitten kan een startpunt zijn voor geneesmiddelen tegen kanker
- Van hard naar zacht:sponzen maken van mosselschelpen
- Een betere zoutvanger bouwen:wetenschappers synthetiseren een moleculaire kooi om chloride op te vangen
- Hoe maak je een rubber Wishbone met azijn
- Wil je de klimaatverandering aanpakken? Pak eerst je voedselverspilling aan
- Hoe groene mijnbouw de weg kan banen naar netto nul en een duurzame toekomst
- Milieuvriendelijke verzending helpt de vrachtkosten te verlagen
- Radiance Light Trends toont veranderingen in de lichtemissies van de aarde
- Regen helpt tegen monsterbranden in Spanje
Hoofdlijnen
- Een poging om veelvraat terug te halen naar Californië mislukt vanwege begrotingsproblemen
- De levenscyclus van Gymnosperms
- Hoe doodt alcohol bacteriën?
- Wat zijn de voordelen van Ribosomes?
- Video:studenten insectenbiologie leren kunst van op insecten gebaseerde kleurstoffen
- Studie van zeedieren suggereert dat het zenuwstelsel meerdere keren onafhankelijk is geëvolueerd
- Een eiwitduo zorgt ervoor dat de chromosomen in de voortplantingscellen hun significante andere vinden
- Genmutatie: definitie, oorzaken, typen, voorbeelden
- DNA Extraction by Spooling Method
- Flexibele batterijen voeden de toekomst van draagbare technologie

- Nanobuisjes opgebouwd uit eiwitkristallen:doorbraak in biomoleculaire engineering
- Met plakband en laserstralen, onderzoekers maken nieuw materiaal dat led-schermen kan verbeteren

- Onderzoekers transformeren tomaten in fluorescerende koolstofstippen
- Quantum-dot-technologie maakt lcd-tv's kleurrijker, energiezuinig


 Studie onderzoekt productiviteitspotentieel van thuisblijvers
Studie onderzoekt productiviteitspotentieel van thuisblijvers- Natuurkundigen bewijzen dat 2D- en 3D-vloeistoffen fundamenteel verschillend zijn
- Studie onthult nieuw Antarctisch proces dat bijdraagt aan zeespiegelstijging en klimaatverandering
- Rusland onthult klimaatadaptatieplan
- Huiswerk of slapen? Onderzoek zegt dat het afhangt van wanneer je geboren bent
- Lijst met nachtelijke vliegende insecten
- Verborgen donoren spelen belangrijke rol in politieke campagnes
- Centennial van ex-astronaut, Amerikaanse senator John Glenn gemarkeerd als
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
