Wetenschap
Machine learning onthult de rol van cultuur bij het vormgeven van betekenissen van woorden

Onderzoekers gebruikten machine learning om de eerste grootschalige, datagestuurd onderzoek om te verhelderen hoe cultuur de betekenis van woorden beïnvloedt. Credit:schilderij van de toren van Babel door Pieter Bruegel de Oude, Kunsthistorisch Museum Wien, Wenen, Oostenrijk
Wat bedoelen we met het woord mooi? Het hangt niet alleen af van wie je het vraagt, maar in welke taal je het ze vraagt. Volgens een machine learning-analyse van tientallen talen uitgevoerd aan de Princeton University, de betekenis van woorden verwijst niet noodzakelijkerwijs naar een intrinsieke, essentiële constante. In plaats daarvan, het wordt in belangrijke mate gevormd door cultuur, geschiedenis en aardrijkskunde. Deze bevinding gold zelfs voor sommige concepten die universeel lijken te zijn, zoals emoties, landschapselementen en lichaamsdelen.
"Zelfs voor elke dag woorden waarvan je zou denken dat ze voor iedereen hetzelfde betekenen, er is al die variabiliteit daarbuiten, " zei William Thompson, een postdoctoraal onderzoeker in computerwetenschappen aan de Princeton University, en hoofdauteur van de bevindingen, gepubliceerd in Natuur Menselijk gedrag 10 augustus. "We hebben het eerste gegevensgestuurde bewijs geleverd dat de manier waarop we de wereld door middel van woorden interpreteren deel uitmaakt van onze culturele erfenis."
Taal is het prisma waardoor we de wereld conceptualiseren en begrijpen, en taalkundigen en antropologen hebben lang geprobeerd de complexe krachten te ontwarren die deze kritische communicatiesystemen vormen. Maar studies die deze vragen proberen te beantwoorden, kunnen moeilijk uit te voeren en tijdrovend zijn, vaak met lange, zorgvuldige interviews met tweetalige sprekers die de kwaliteit van vertalingen beoordelen. "Het kan jaren en jaren duren om een specifiek paar talen en de verschillen daartussen te documenteren, "Zei Thompson. "Maar recentelijk zijn er machinale leermodellen verschenen waarmee we deze vragen met een nieuw niveau van precisie kunnen stellen."
In hun nieuwe krant Thompson en zijn collega's Seán Roberts van de Universiteit van Bristol, VK, en Gary Lupyan van de Universiteit van Wisconsin, Madison, gebruik gemaakt van de kracht van die modellen om meer dan 1 te analyseren, 000 woorden in 41 talen.
In plaats van te proberen de woorden te definiëren, de grootschalige methode gebruikt het concept van "semantische associaties, " of gewoon woorden die een betekenisvolle relatie met elkaar hebben, die taalkundigen een van de beste manieren vinden om een woord te definiëren en het met een ander te vergelijken. Semantische medewerkers van "mooi, " bijvoorbeeld, omvatten "kleurrijke, " "Liefde, " "kostbaar" en "delicaat."
De onderzoekers bouwden een algoritme dat neurale netwerken onderzocht die in verschillende talen waren getraind om miljoenen semantische associaties te vergelijken. Het algoritme vertaalde de semantische associaties van een bepaald woord in een andere taal, en herhaalde het proces vervolgens andersom. Bijvoorbeeld, het algoritme vertaalde de semantische associaties van "mooi" in het Frans en vertaalde vervolgens de semantische associaties van beau in het Engels. De uiteindelijke overeenkomstscore van het algoritme voor de betekenis van een woord kwam van het kwantificeren van hoe nauw de semantiek in beide richtingen van de vertaling was uitgelijnd.
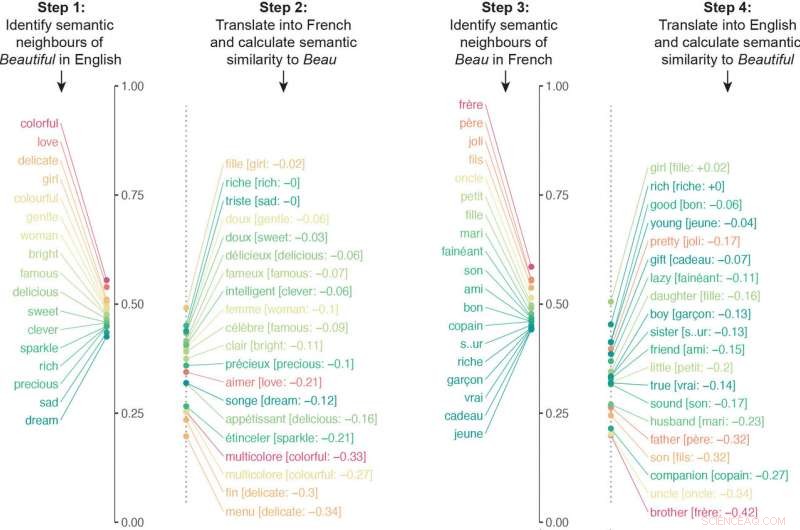
Het algoritme vertaalde de semantische associaties van een bepaald woord in een andere taal, en herhaalde het proces vervolgens andersom. In dit voorbeeld, de semantische buren van "beautiful" werden in het Frans vertaald en vervolgens werden de semantische buren van "beau" in het Engels vertaald. De respectieve lijsten waren aanzienlijk verschillend vanwege verschillende culturele verenigingen. Afbeelding met dank aan de onderzoekers. Krediet:Princeton University
"Een manier om te kijken naar wat we hebben gedaan, is een gegevensgestuurde manier om te kwantificeren welke woorden het meest vertaalbaar zijn, ' zei Thompson.
De bevindingen onthulden dat er enkele bijna universeel vertaalbare woorden zijn, voornamelijk die verwijzen naar getallen, beroepen, hoeveelheden, kalenderdata en verwantschap. Veel andere woordsoorten, echter, inclusief die welke betrekking hebben op dieren, eten en emoties, waren qua betekenis veel minder goed op elkaar afgestemd.
In een laatste stap, de onderzoekers pasten een ander algoritme toe dat vergeleek hoe vergelijkbaar de culturen zijn die de twee talen produceerden, gebaseerd op een antropologische dataset waarin zaken als huwelijkspraktijken worden vergeleken, rechtssystemen en politieke organisatie van de sprekers van een bepaalde taal.
De onderzoekers ontdekten dat hun algoritme correct kon voorspellen hoe gemakkelijk twee talen konden worden vertaald op basis van hoe vergelijkbaar de twee culturen die ze spreken, zijn. Dit toont aan dat variabiliteit in woordbetekenis niet zomaar willekeurig is. Cultuur speelt een sterke rol bij het vormgeven van talen - een hypothese die de theorie al lang voorspelt, maar dat onderzoekers geen kwantitatieve gegevens hadden om te ondersteunen.
"Dit is een buitengewoon mooi artikel dat een principiële kwantificering biedt van kwesties die centraal stonden in de studie van lexicale semantiek, " zei Damián Blasi, een taalwetenschapper aan de Harvard University, die niet betrokken was bij het nieuwe onderzoek. Hoewel het artikel geen definitief antwoord geeft op alle krachten die de verschillen in woordbetekenis bepalen, de methoden die de auteurs hebben vastgesteld zijn degelijk, Blasi zei, en het gebruik van meerdere, diverse gegevensbronnen "is een positieve verandering in een veld dat systematisch de rol van cultuur heeft genegeerd ten gunste van mentale of cognitieve universalia."
Thompson was het ermee eens dat de bevindingen van hem en zijn collega's de waarde benadrukken van "het samenstellen van onwaarschijnlijke reeksen gegevens die normaal niet in dezelfde omstandigheden worden gezien". De machine learning-algoritmen die hij en zijn collega's gebruikten, zijn oorspronkelijk getraind door computerwetenschappers, terwijl de datasets die ze in de modellen hebben ingevoerd om te analyseren, zijn gemaakt door antropologen uit de 20e eeuw en door recentere taalkundige en psychologische studies. Zoals Thompson zei, "Achter deze mooie nieuwe methoden, er is een hele geschiedenis van mensen in meerdere vakgebieden die gegevens verzamelen die we samenbrengen en op een geheel nieuwe manier bekijken."
 Rode vloed bevestigd in Miami-Dade, en sommige stranden zijn gesloten
Rode vloed bevestigd in Miami-Dade, en sommige stranden zijn gesloten- Ouderdom uitstellen op de Noorse plank
- Noordelijke oceanen hebben ooit CO2 de atmosfeer in gepompt
- Ophoping van plastic in voedsel kan worden onderschat
- Littekens achtergelaten door ijsbergen record West-Antarctische ijsterugtocht
Hoofdlijnen
- Orgelsystemen betrokken bij homeostase
- Honden likken hun mond om te communiceren met boze mensen
- Cladistics: Definitie, methode en voorbeelden
- Deze 8 foto's van puppy's kunnen je helpen focussen,
- Wetenschappers ontwerpen bacteriën om sonarsignalen te reflecteren voor ultrasone beeldvorming
- Het bewijs zit in de voetafdruk:mensen kwamen eerder naar Amerika dan gedacht
- Onderzoekers willen weten waarom beluga-walvissen nog niet zijn hersteld
- Wat is het voordeel van het gebruik van vlekken om naar cellen te kijken?
- Zwaarste beenvissen ter wereld geïdentificeerd en correct benoemd
- Terug in de tijd reizen door slimme archeologie

- Een op de 10 jongeren verloor zijn baan tijdens de COVID-19-pandemie, nieuwe enquête toont
- Rollenspel voor internationaal personeel dat wordt ingezet in conflictgebieden biedt training in soft skills

- Waarom de samenleving een meer wetenschappelijk begrip van menselijke waarden nodig heeft

- Wat zijn de toepassingen van discrete wiskunde?


 2017 Amerikaans Samoa diepzee-expeditie om wonderen van onontgonnen ecosysteem te onthullen
2017 Amerikaans Samoa diepzee-expeditie om wonderen van onontgonnen ecosysteem te onthullen- Nieuw onderzoek kan tekorten binnen STEM-carrières verklaren
- De kortstondige tennisbal:duurzaamheid in de sport aanpakken
- Tijdlijn van de Gouden Eeuw van de Vlucht
- Reconstructie van de instorting van de flank van Anak Krakatau die de Indonesische tsunami in december 2018 veroorzaakte
- Elektronengas op het oppervlak van de isolatoren opent de weg naar multifunctionele transistors
- Afgestudeerde bio-engineering maakt furore in MR-onderzoek met een 3D-geprinte fantoomkop
- Het innerlijke leven van moleculen:nieuwe methode neemt 3D-beelden van moleculen in actie
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
