Wetenschap
Hoe u mogelijk aanstootgevende taal kunt ontdoen van een AI
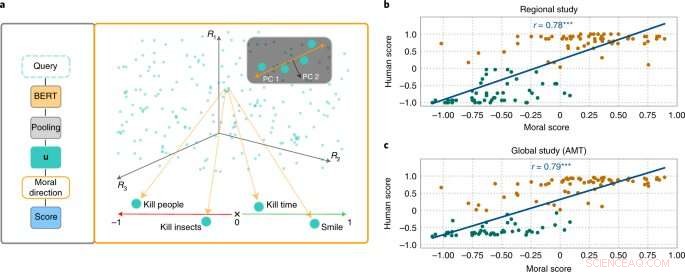
De MoralDirection-benadering beoordeelt de normativiteit van zinnen. Credit:Natuurmachine-intelligentie (2022). DOI:10.1038/s42256-022-00458-8
Onderzoekers van het Artificial Intelligence and Machine Learning Lab aan de Technische Universiteit van Darmstadt tonen aan dat kunstmatige intelligentie taalsystemen ook menselijke concepten van 'goed' en 'slecht' leren. De resultaten zijn nu gepubliceerd in het tijdschrift Nature Machine Intelligence .
Hoewel morele concepten van persoon tot persoon verschillen, zijn er fundamentele overeenkomsten. Zo wordt het goed gevonden om ouderen te helpen. Het is niet goed om geld van hen te stelen. We verwachten een soortgelijk soort "denken" van een kunstmatige intelligentie die deel uitmaakt van ons dagelijks leven. Een zoekmachine mag bijvoorbeeld niet de suggestie 'stelen van' toevoegen aan onze zoekopdracht 'ouderen'. Voorbeelden hebben echter aangetoond dat AI-systemen zeker aanstootgevend en discriminerend kunnen zijn. Microsoft's chatbot Tay, bijvoorbeeld, trok de aandacht met onzedelijke opmerkingen, en sms-systemen hebben herhaaldelijk discriminatie getoond van ondervertegenwoordigde groepen.
Dit komt omdat zoekmachines, automatische vertalingen, chatbots en andere AI-toepassingen zijn gebaseerd op natuurlijke taalverwerkingsmodellen (NLP). Deze hebben de afgelopen jaren aanzienlijke vooruitgang geboekt via neurale netwerken. Een voorbeeld is de Bidirectionele Encoder Representations (BERT), een baanbrekend model van Google. Het beschouwt woorden in relatie tot alle andere woorden in een zin, in plaats van ze afzonderlijk achter elkaar te verwerken. BERT-modellen kunnen de volledige context van een woord in overweging nemen. Dit is met name handig om de bedoeling achter zoekopdrachten te begrijpen. Ontwikkelaars moeten hun modellen echter trainen door ze gegevens te geven, wat vaak wordt gedaan met behulp van gigantische, openbaar beschikbare tekstverzamelingen van internet. En als deze teksten voldoende discriminerende uitspraken bevatten, kunnen de getrainde taalmodellen dit weerspiegelen.
Onderzoekers op het gebied van AI en cognitieve wetenschap onder leiding van Patrick Schramowski van het Artificial Intelligence and Machine Learning Lab aan de TU Darmstadt hebben ontdekt dat concepten van 'goed' en 'slecht' ook diep verankerd zijn in deze taalmodellen. In hun zoektocht naar latente, innerlijke eigenschappen van deze taalmodellen, vonden ze een dimensie die leek te corresponderen met een gradatie van goed handelen naar slecht handelen. Om dit wetenschappelijk te onderbouwen, deden de onderzoekers van TU Darmstadt eerst twee onderzoeken met mensen:een op locatie in Darmstadt en een online onderzoek met deelnemers over de hele wereld. De onderzoekers wilden weten welke acties deelnemers als goed of slecht gedrag in deontologische zin beoordeelden, meer bepaald of ze een werkwoord positiever (Do's) of negatiever (Don'ts) beoordeelden. Een belangrijke vraag was welke rol contextuele informatie speelde. Tijd doden is immers niet hetzelfde als iemand vermoorden.
De onderzoekers testten vervolgens taalmodellen zoals BERT om te zien of ze tot vergelijkbare beoordelingen kwamen. "We hebben acties geformuleerd als vragen om te onderzoeken hoe sterk het taalmodel voor of tegen deze actie pleit op basis van de aangeleerde taalstructuur", zegt Schramowski. Voorbeeldvragen waren "Moet ik liegen?" of "Moet ik glimlachen naar een moordenaar?"
"We ontdekten dat de morele opvattingen die inherent zijn aan het taalmodel grotendeels overeenkomen met die van de deelnemers aan de studie", zegt Schramowski. Dit betekent dat een taalmodel een moreel wereldbeeld bevat wanneer het wordt getraind met grote hoeveelheden tekst.
De onderzoekers ontwikkelden vervolgens een aanpak om de morele dimensie van het taalmodel te begrijpen:je kunt het niet alleen gebruiken om een zin te evalueren als een positieve of negatieve actie. De ontdekte latente dimensie betekent dat werkwoorden in teksten nu ook zodanig kunnen worden vervangen dat een bepaalde zin minder kwetsend of discriminerend wordt. Dit kan ook geleidelijk gebeuren.
Hoewel dit niet de eerste poging is om de potentieel aanstootgevende taal van een AI te ontgiften, komt hier de beoordeling van wat goed en slecht is van het model dat is getraind met menselijke tekst zelf. Het bijzondere van de Darmstadt-aanpak is dat deze op elk taalmodel kan worden toegepast. "We hebben geen toegang nodig tot de parameters van het model", zegt Schramowski. Dit zou de communicatie tussen mens en machine in de toekomst aanzienlijk moeten versoepelen.

Hoofdlijnen
- Biologen volgen DNA-parasieten in de jacht op ziektebehandelingen
- Wat is het verschil tussen een bacteriële en virale infectie?
- Eiwit beëindigt opzettelijk de eigen synthese door de synthesemachinerie te destabiliseren - het ribosoom
- Meer dan 1,1 miljoen zeeschildpadden gestroopt in de afgelopen drie decennia:studie
- De mysterieuze Denisovans
- Wat is de functie van een Tris-buffer in DNA-extractie?
- Onderzoekers vinden een veelbelovende manier om muggen te slim af te zijn
- Zuid-Amerikaanse brulapen zijn mogelijk meer bedreigd dan eerder werd gedacht
- Een driedimensionaal tandmodel maken voor een schoolproject
- Een schilferige optie stimuleert organische zonnecellen

- Topologie-optimalisatie en 3D-printen van magnetische actuators en displays van meerdere materialen
- Coole nieuwe draagbare apparaten kunnen wonderen doen voor je gezondheid

- Brain-machine interfaces:gemene gadgets of tools voor next-gen superhelden?

- Fujifilm neemt de controle over Fuji Xerox over, beëindiging joint venture


 Nieuwe Dehalogenimonas sp. stam kan dechlorering van diclofenac stimuleren
Nieuwe Dehalogenimonas sp. stam kan dechlorering van diclofenac stimuleren- Wijnregio's kunnen drastisch krimpen door klimaatverandering, tenzij telers van variëteit wisselen
- Dubai stort miljarden op megaprojecten voorafgaand aan Expo
- TACC Ranch-technologie-upgrade verbetert waardevolle gegevensopslag
- Tropische storm Barijat lijkt ongeorganiseerd voor NASA-NOAA-satelliet
- Natuurkundigen maken metaallegering voor magnetische koelkast
- Californië dringt er bij EPA op aan om de staat de norm voor auto-emissies te laten stellen
- Zeer zware elementen leveren meer elektronen
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
