Wetenschap
Vloeistofmenging optimaliseren met machine learning
Credit:Tokyo University of Science
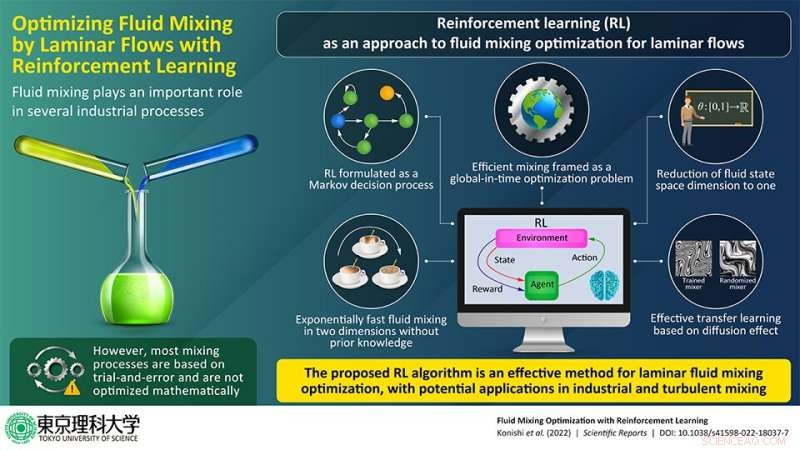
Vloeistofmenging is een belangrijk onderdeel van verschillende industriële processen en chemische reacties. Het proces is echter vaak gebaseerd op proefondervindelijke experimenten in plaats van wiskundige optimalisatie. Hoewel turbulent mengen effectief is, kan het niet altijd worden volgehouden en kunnen de betrokken materialen worden beschadigd. Om dit probleem aan te pakken, hebben onderzoekers uit Japan nu een optimalisatiebenadering van vloeistofmenging voor laminaire stromingen voorgesteld met behulp van machine learning, die ook kan worden uitgebreid tot turbulente menging.
Het mengen van vloeistoffen is een kritische component in veel industriële en chemische processen. Farmaceutische menging en chemische reacties kunnen bijvoorbeeld homogene vloeistofmenging vereisen. Door deze menging sneller en met minder energie te realiseren, zouden de bijbehorende kosten sterk dalen. In werkelijkheid zijn de meeste mengprocessen echter niet wiskundig geoptimaliseerd en vertrouwen ze in plaats daarvan op op trial-and-error gebaseerde empirische methoden. Turbulente menging, waarbij turbulentie wordt gebruikt om vloeistoffen te mengen, is een optie, maar is problematisch omdat het ofwel moeilijk vol te houden is (zoals in micromixers) of de materialen die worden gemengd beschadigt (zoals in bioreactoren en voedselmixers).
Kan in plaats daarvan een geoptimaliseerde menging worden bereikt voor laminaire stromingen? Om deze vraag te beantwoorden, richtte een team van onderzoekers uit Japan zich in een nieuwe studie op machine learning. In hun studie gepubliceerd in Scientific Reports , nam het team zijn toevlucht tot een benadering genaamd "reinforcement learning" (RL), waarbij intelligente agenten acties ondernemen in een omgeving om de cumulatieve beloning te maximaliseren (in tegenstelling tot een onmiddellijke beloning).
"Aangezien RL de cumulatieve beloning maximaliseert, die globaal in de tijd is, kan worden verwacht dat het geschikt is om het probleem van efficiënte vloeistofmenging aan te pakken, wat ook een globaal-in-tijd optimalisatieprobleem is", legt universitair hoofddocent Masanobu Inubushi uit. , de corresponderende auteur van de studie. "Persoonlijk ben ik ervan overtuigd dat het belangrijk is om het juiste algoritme voor het juiste probleem te vinden in plaats van blindelings een machine learning-algoritme toe te passen. Gelukkig zijn we er in dit onderzoek in geslaagd om de twee velden (vloeistofmenging en versterkingsleren) te verbinden na gezien hun fysieke en wiskundige kenmerken." Het werk omvatte bijdragen van Mikito Konishi, een afgestudeerde student, en prof. Susumu Goto, beide van de universiteit van Osaka.
Er wachtte het team echter een grote wegversperring. Hoewel RL geschikt is voor globale optimalisatieproblemen, is het niet bijzonder geschikt voor systemen met hoogdimensionale toestandsruimten, d.w.z. systemen die een groot aantal variabelen vereisen voor hun beschrijving. Helaas was het mengen van vloeistoffen zo'n systeem.
Om dit probleem aan te pakken, koos het team voor een benadering die werd gebruikt bij de formulering van een ander optimalisatieprobleem, waardoor ze de dimensie van de toestandsruimte voor vloeistofstroom tot één konden terugbrengen. Simpel gezegd, de vloeiende beweging kan nu worden beschreven met slechts één enkele parameter.
Het RL-algoritme wordt meestal geformuleerd in termen van een Markov-beslissingsproces (MDP), een wiskundig raamwerk voor besluitvorming in situaties waarin de uitkomsten deels willekeurig zijn en deels worden gecontroleerd door de beslisser. Met behulp van deze aanpak toonde het team aan dat RL effectief was in het optimaliseren van vloeistofmenging.
"We hebben ons RL-gebaseerde algoritme getest voor het tweedimensionale vloeistofmengprobleem en ontdekten dat het algoritme een effectieve stroomregeling identificeerde, wat culmineerde in een exponentieel snelle vermenging zonder enige voorkennis", zegt Dr. Inubushi. "Het mechanisme dat aan deze efficiënte menging ten grondslag ligt, werd verklaard door te kijken naar de stroming rond de vaste punten vanuit een dynamisch systeemtheoretisch perspectief."
Een ander belangrijk voordeel van de RL-methode was een effectief transferleren (het toepassen van de opgedane kennis op een ander, maar gerelateerd probleem) van de getrainde mixer. In de context van vloeistofmenging hield dit in dat een menger die getraind was op een bepaald Péclet-getal (de verhouding van de advectiesnelheid tot de diffusiesnelheid in het mengproces) zou kunnen worden gebruikt om een mengprobleem bij een ander Péclet-getal op te lossen. Dit verminderde de tijd en kosten van het trainen van het RL-algoritme aanzienlijk.
Hoewel deze resultaten bemoedigend zijn, wijst Dr. Inubishi erop dat dit nog steeds de eerste stap is. "Er zijn nog veel problemen die moeten worden opgelost, zoals de toepassing van de methode op meer realistische vloeistofmengproblemen en de verbetering van RL-algoritmen en hun implementatiemethoden", zegt hij.
Hoewel het zeker waar is dat tweedimensionale vloeistofmenging niet representatief is voor de werkelijke mengproblemen in de echte wereld, biedt deze studie een bruikbaar uitgangspunt. Bovendien, terwijl het zich richt op het mengen in laminaire stromen, kan de methode ook worden uitgebreid tot turbulente menging. Het is daarom veelzijdig en heeft potentieel voor grote toepassingen in verschillende industrieën die vloeistofmenging toepassen. + Verder verkennen
Een supercomputer gebruiken om de beste manier te vinden om twee vloeistoffen te mengen
 Broom tegen chloorbinding Energie
Broom tegen chloorbinding Energie - Biomimetische vezelversterkte composieten op micro-/nanoschaal
- Op zoek naar de meest effectieve polymeren voor persoonlijke beschermingsmiddelen
- Bio-geïnspireerde moleculaire kleurstoffen voor biomedische fluorescerende beeldvorming
- Nieuw inzicht in celmembranen kan het testen en ontwerpen van geneesmiddelen verbeteren
Hoofdlijnen
- Overeenkomsten tussen huidcellen en zenuwen
- Hoe de immuunrespons bijdraagt aan Homeostasis
- De verschillen tussen fotosynthese en ademhaling
- Zich in het volle zicht verbergen - Ontdekking roept vragen op over de schaal van de over het hoofd geziene biodiversiteit
- Op de maat blijven is gekoppeld aan reproductief succes bij mannelijke rotsklipdassen
- Combinatie van warmer water, blootstelling aan chemicaliën versterkt schadelijke effecten bij een kustvis
- Probiotica (vriendelijke bacteriën): wat is het en hoe helpt het ons?
- Hoe krijgen mensen stikstof in hun lichaam?
- Zijn religies ontstaan uit ons verkeerde begrip van het menselijk bewustzijn?
- De magie van geheime eilanden creëert een veilige haven voor literaire klassiekers op Minecraft.edu

- Nieuwe studie verkent een onaangeboorde voorraad olie- en gasbronnen

- Tesla-aandelen stijgen als aandelen short-seller long gaat

- Rapport richt zich op onbenutte arbeidskrachten voor Israëls groeiende hightechsector

- Uitgehongerd Air India zet bemanningen op vetarm dieet


 Bosbranden in Australië leiden tot ongekende klimaatdesinformatie
Bosbranden in Australië leiden tot ongekende klimaatdesinformatie- Gedetailleerd overzicht van oude Britse vogels onthult potentiële kandidaten voor herwildering
- Eerste slimme luidsprekersysteem dat witte ruis gebruikt om de ademhaling van baby's te volgen
- Onderzoekers verhogen de hitte op gesmolten metalen om toekomstige technologieën te smeden
- Een boek oppakken voor de lol heeft een positieve invloed op de verbale vaardigheden:studeren
- Hoe 20% korting berekenen
- Maart Madness Tournament Preview: Brian Truongs Data-Driven Picks
- Natuurkundigen maken grote sprongen in het uitlezen van qubits met laserlicht
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
