Wetenschap
Onderzoekers stellen een nieuw en effectiever model voor automatische spraakherkenning voor
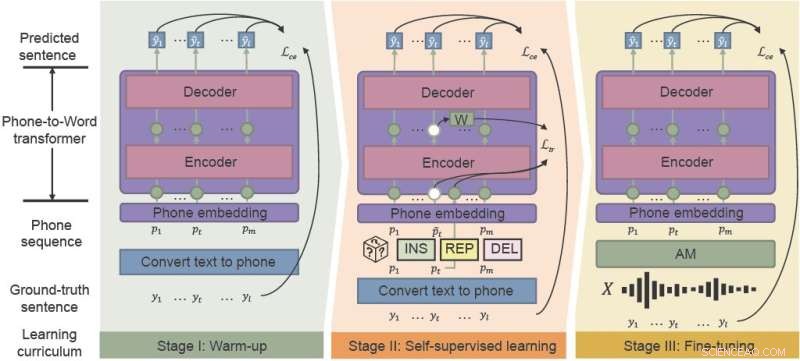
Het fonetisch-semantische pre-trainingskader (PSP) maakt gebruik van 'geluidsbewust curriculum' om de prestaties van ASR in lawaaierige omgevingen effectief te verbeteren. integratie van warming-up, zelf-gesuperviseerd leren, en fine-tuning. Credit:CAAI onderzoek naar kunstmatige intelligentie , Tsinghua University Press
Populaire stemassistenten zoals Siri en Amazon Alexa hebben automatische spraakherkenning (ASR) geïntroduceerd bij het grote publiek. Hoewel tientallen jaren in de maak, worstelen ASR-modellen met consistentie en betrouwbaarheid, vooral in lawaaierige omgevingen. Chinese onderzoekers ontwikkelden een raamwerk dat de prestaties van ASR effectief verbetert voor de chaos van alledaagse akoestische omgevingen.
Onderzoekers van de Hong Kong University of Science and Technology en WeBank stelden een nieuw raamwerk voor:fonetisch-semantische pre-training (PSP) en demonstreerden de robuustheid van hun nieuwe model tegen synthetische spraakdatasets met veel ruis.
Hun studie werd gepubliceerd in CAAI Artificial Intelligence Research op 28 aug.
"Robuustheid is een langdurige uitdaging voor ASR", zegt Xueyang Wu van de Hong Kong University of Science and Technology Department of Computer Science and Engineering. "We willen de robuustheid van het Chinese ASR-systeem vergroten tegen lage kosten."
ASR gebruikt machine learning en andere kunstmatige-intelligentietechnieken om spraak automatisch in tekst te vertalen voor toepassingen zoals spraakgestuurde systemen en transcriptiesoftware. Maar nieuwe, op de consument gerichte toepassingen vragen steeds vaker om spraakherkenning om beter te werken:meer talen en accenten aan te kunnen en betrouwbaarder te presteren in levensechte situaties zoals videoconferenties en live-interviews.
Traditioneel vereist het trainen van de akoestische en taalmodellen waaruit ASR bestaat, grote hoeveelheden geluidsspecifieke gegevens, wat tijdrovend en kostbaar kan zijn.
Het akoestische model (AM) verandert woorden in 'telefoons', opeenvolgingen van basisgeluiden. Het taalmodel (LM) decodeert telefoons in zinnen in natuurlijke taal, meestal met een proces in twee stappen:een snelle maar relatief zwakke LM genereert een reeks zinkandidaten en een krachtige maar rekenkundig dure LM selecteert de beste zin uit de kandidaten.
"Traditionele leermodellen zijn niet bestand tegen luidruchtige akoestische modeluitgangen, vooral voor Chinese polyfone woorden met identieke uitspraak," zei Wu. "Als de eerste passage van de decodering van het leermodel onjuist is, is het buitengewoon moeilijk om de tweede passage in te halen."
Het nieuw voorgestelde raamwerk PSP maakt het gemakkelijker om verkeerd geclassificeerde woorden te herstellen. Door een model voor te trainen dat de AM-uitgangen direct vertaalt naar een zin, samen met de volledige contextinformatie, kunnen onderzoekers de LM helpen efficiënt te herstellen van de luidruchtige uitgangen van de AM.
Dankzij het PSP-framework kan het model worden verbeterd door middel van een pre-trainingsregime dat noise-aware curriculum wordt genoemd en dat geleidelijk nieuwe vaardigheden introduceert, gemakkelijk begint en geleidelijk overgaat in complexere taken.
"Het meest cruciale onderdeel van onze voorgestelde methode, Noise-aware Curriculum Learning, simuleert het mechanisme van hoe mensen een zin herkennen aan luidruchtige spraak," zei Wu.
Opwarmen is de eerste fase, waarbij onderzoekers een telefoon-naar-woord-transducer vooraf trainen op een schone telefoonreeks, die alleen wordt vertaald uit niet-gelabelde tekstgegevens, om de annotatietijd te verkorten. Deze fase "warmt" het model op, waarbij de basisparameters worden geïnitialiseerd om telefoonreeksen aan woorden toe te wijzen.
In de tweede fase, zelf-gesuperviseerd leren, leert de transducer van complexere gegevens die worden gegenereerd door zelf-gesuperviseerde trainingstechnieken en -functies. Ten slotte wordt de resulterende telefoon-naar-woord-transducer nauwkeurig afgesteld met spraakgegevens uit de echte wereld.
De onderzoekers hebben experimenteel de effectiviteit van hun raamwerk aangetoond op twee real-life datasets verzameld uit industriële scenario's en synthetische ruis. De resultaten toonden aan dat het PSP-framework de traditionele ASR-pijplijn effectief verbetert, door de relatieve karakterfoutpercentages te verminderen met 28,63% voor de eerste dataset en 26,38% voor de tweede.
In de volgende stappen zullen onderzoekers effectievere PSP-pre-trainingsmethoden onderzoeken met grotere ongepaarde datasets, om de effectiviteit van pre-training voor ruis-robuuste LM te maximaliseren. + Verder verkennen
Multi-task learning gebruiken voor spraakvertaling met lage latentie
 Een nieuw potentieel alternatief voor muggenbestrijding ontdekt
Een nieuw potentieel alternatief voor muggenbestrijding ontdekt- Chemische reacties die kleurverandering veroorzaken
- Nieuwe slimme sensor kan een revolutie teweegbrengen in de preventie van misdaad en terrorisme
- Mechanisme achter platinakatalysator gevangen
- Levende sensor kan mogelijk milieurampen door brandstofverspilling voorkomen
- Een beter beheer van plastic afval in een handvol rivieren kan plastic in de oceaan tegengaan
- De meerderheid van de Amerikaanse volwassenen gelooft dat klimaatverandering vandaag de dag het belangrijkste probleem is
- Acht landen zijn nu uitgerust om de beschaving te beëindigen
- Wetenschappers krijgen vroeg inzicht in orkaanschade aan Caribische koraalriffen
- Klimaatverandering en extreem weer die migratie stimuleren
Hoofdlijnen
- De kracht van compost:van afval een klimaatkampioen maken
- Manukahoning kan helpen om dodelijke medicijnresistente longinfectie te genezen, suggereert onderzoek
- De snelheid van verval berekenen
- Planten worden toleranter als ze in symbiose met schimmels leven
- Wat is het verschil in de cellen van een menselijke baby en een volwassen mens?
Nieuwe baby's zijn allebei erg op elkaar en lijken erg op volwassenen. De meeste celontwikkeling en -differentiatie vinden plaats voorafgaand aan de geboorte van een ba
- Mieren offeren hun koloniegenoten op als onderdeel van een dodelijke desinfectie
- Kikker en menselijke bloedcellen vergelijken en identificeren
- Bereken de percentages van adenine in een DNA-streng
- Wat is de chemische vergelijking voor aërobe ademhaling?
- Amazon Go-managers delen inzichten in winkelgedrag

- Moet het beter doen:Japan kijkt naar AI-robots in de klas om Engels een boost te geven

- De groei van het aantal abonnees van Netflix in de VS vertraagt naarmate de concurrentie opdoemt

- Sociale media stimuleren de verspreiding van COVID-19-informatie – en verkeerde informatie

- Onderzoekers leggen eerste beelden vast van kooldioxide-emissies door motoren van commerciële vliegtuigen


 Ford onthult nieuwste Mustang, waarmee de levensduur van benzinemotoren wordt verlengd
Ford onthult nieuwste Mustang, waarmee de levensduur van benzinemotoren wordt verlengd- Studie werpt licht op hoe het rechtssysteem fysieke, mentale gezondheid
- Hongerigste zwarte gaten onder de meest massieve in het universum
- Voor de juiste medewerkers zelfs standaard informatietechnologie kan creativiteit stimuleren
- Verbluffende Webb-afbeeldingen tonen de duidelijkste kijk op Cosmos ooit
- Beschermende factoren tegen suïcidaal gedrag onder zwarte studenten
- De waterkwaliteit testen voor een wetenschapsproject
- Prehistorische microben verwaarden koolstofdioxide onder hoge druk tot groen gas
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
