Wetenschap
Alfabetten DeepMind beheerst Atari-spellen
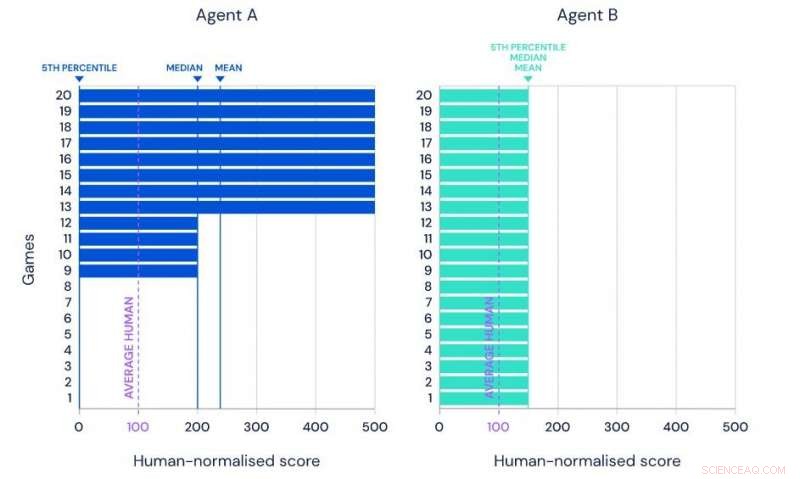
Illustratie van het gemiddelde, mediane en 5e percentielprestaties van twee hypothetische agenten op dezelfde benchmarkset van 20 taken. Krediet:Google
Om complexe uitdagingen aan het begin van het derde decennium van de 21e eeuw beter op te lossen, Alphabet Inc. heeft gebruik gemaakt van relikwieën uit de jaren 80:videogames.
Het moederbedrijf van Google meldde deze week dat zijn DeepMind Technologies Artificial Intelligence-eenheid met succes 57 Atari-videogames heeft leren spelen. En het computersysteem speelt beter dan enig mens.
Atari, schepper van Pong, een van de eerste succesvolle videogames van de jaren 70, ging door met het populair maken van veel van de grote vroege klassieke videogames in de jaren negentig. Videogames worden vaak gebruikt bij AI-projecten omdat ze algoritmen uitdagen om door steeds complexere paden en opties te navigeren, allemaal terwijl ze veranderende scenario's tegenkomen, bedreigingen en beloningen.
Nagesynchroniseerde AGENT57, Het AI-systeem van Alphabet onderzocht 57 toonaangevende Atari-spellen met een enorm scala aan moeilijkheidsgraden en verschillende successtrategieën.
"Games zijn een uitstekende proeftuin voor het bouwen van adaptieve algoritmen, " zeiden de onderzoekers in een rapport op de DeepMind-blogpagina. "Ze bieden een rijke reeks taken die spelers geavanceerde gedragsstrategieën moeten ontwikkelen om onder de knie te krijgen, maar ze bieden ook een gemakkelijke voortgangsstatistiek - gamescore - om tegen te optimaliseren.
"Het uiteindelijke doel is niet om systemen te ontwikkelen die uitblinken in games, maar eerder om games te gebruiken als een springplank voor het ontwikkelen van systemen die leren uitblinken in een breed scala aan uitdagingen, " aldus het rapport.
DeepMind's AlphaGo-systeem kreeg in 2016 brede erkenning toen het wereldkampioen Lee Sedol versloeg in het strategische spel Go.
Onder de huidige oogst van 57 Atari-spellen, vier worden als bijzonder moeilijk beschouwd voor AI-projecten om te beheersen:Montezuma's Revenge, Valkuil, Solaris en skiën. De eerste twee games vormen wat DeepMind het verbijsterende 'exploratie-exploitatieprobleem' noemt.
"Moet men gedrag blijven vertonen waarvan men weet dat het werkt (exploit), of moet je iets nieuws proberen (verkennen) om nieuwe strategieën te ontdekken die misschien nog succesvoller zijn?" vraagt DeepMind. "Bijvoorbeeld, moet men altijd hetzelfde favoriete gerecht bestellen in een lokaal restaurant, of iets nieuws proberen dat de oude favoriet zou kunnen overtreffen? Exploratie omvat het nemen van veel suboptimale acties om de informatie te verzamelen die nodig is om uiteindelijk sterker gedrag te ontdekken."
De andere twee uitdagende spellen zorgen voor lange wachttijden tussen uitdagingen en beloningen, waardoor het moeilijker wordt voor AI-systemen om succesvol te analyseren.
Eerdere pogingen om de vier games onder de knie te krijgen met AI zijn allemaal mislukt.
Volgens het rapport is er nog ruimte voor verbetering. Voor een, lange rekentijden blijven een probleem. Ook, terwijl hij erkent dat "hoe langer hij trainde, hoe hoger de score, " DeepMind-onderzoekers willen dat Agent57 het beter doet. Ze willen dat het meerdere games tegelijk onder de knie heeft; momenteel het kan slechts één spel tegelijk leren en het moet elke keer dat het een spel herstart een training ondergaan.
uiteindelijk, DeepMind-onderzoekers voorzien een programma dat mensachtige besluitvormingskeuzes kan toepassen terwijl ze worden geconfronteerd met steeds veranderende en voorheen onzichtbare uitdagingen.
"Echte veelzijdigheid, die zo gemakkelijk overkomt bij een mensenkind, ligt nog steeds ver buiten het bereik van AI's, ’ concludeerde het rapport.
© 2020 Wetenschap X Netwerk
 Verbetering van de paleotemperatuur-reconstructie - Zwitserse meren als modelsysteem
Verbetering van de paleotemperatuur-reconstructie - Zwitserse meren als modelsysteem- Onderzoekers onderzoeken achteruitgang van Zuid-Afrikaanse bosvogels
- De geheime oorsprong van China's 40-jarenplan om een einde te maken aan de CO2-uitstoot
- Onderzoekers bestuderen de ingewikkelde link tussen klimaat en conflict
- Expert:Geen enkele, one-size-fits-all oplossing voor het probleem van plastic afval
Hoofdlijnen
- zeehonden, vogels en mensen strijden om vis in de Oostzee
- Wetenschappers roepen de VS op om onderzoek naar potmedicijnen voor huisdieren toe te staan
- spijt,
- Plantencellen overleven maar stoppen met delen bij DNA-schade
- Interspecifieke concurrentie versus intraspecifieke concurrentie
- Vissen kunnen ander gedrag gebruiken om zich tegen parasieten te beschermen
- Het co-evoluerende web van het leven als een netwerk begrijpen
- Hoe extremofielen werken
- Hoe worden bacteriën resistent tegen antibiotica?
- Efficiënte waterstofcompressie voor grootschalige mobiliteitstoepassingen

- Gaat Facebook tv opnieuw uitvinden met Facebook Watch? We zullen, het is proberen

- Hackers richten zich op smartphones om cryptocurrencies te minen

- Onderzoekers ontwikkelen technologie die pulsen gebruikt om berichten door de huid te sturen

- Instagram verbiedt fictieve fragmenten met zelfmoord


 Nieuwe designer carbon verbetert de batterijprestaties
Nieuwe designer carbon verbetert de batterijprestaties- Antarctisch zee-ijsverlies uitgelegd in nieuwe studie
- Geneesmiddelenresistentie bestrijden met snelle, kunstmatige verbetering van natuurlijke producten
- een ster, Metaalvrije manier om koolstofnanobuisjes te maken
- Hoe mensen het ecosysteem ontwrichten
- Nano-polycatenaansynthese bereikt met moleculaire zelfassemblage
- Onderzoekers identificeren optimale menselijke landingssysteemarchitecturen om op de maan te landen
- Aluminiumcomplexen geïdentificeerd via vibrationele vingerafdrukken
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
