Wetenschap
Nieuwe algoritmen trainen AI om specifiek slecht gedrag te voorkomen

als robots, zelfrijdende auto's en andere intelligente machines weven AI in het dagelijks leven, een nieuwe manier om algoritmen te ontwerpen, kan ontwikkelaars van machine learning helpen om beveiligingen in te bouwen tegen specifieke, ongewenste uitkomsten zoals raciale en gendervooroordelen. Krediet:Deboki Chakravarti
Kunstmatige intelligentie is de commerciële mainstream geworden dankzij de groeiende bekwaamheid van machine learning-algoritmen waarmee computers zichzelf kunnen trainen om dingen te doen zoals autorijden, robots aansturen of besluitvorming automatiseren.
Maar naarmate AI gevoelige taken begint af te handelen, zoals helpen kiezen welke gevangenen borgtocht krijgen, beleidsmakers dringen erop aan dat computerwetenschappers garanties bieden dat geautomatiseerde systemen zijn ontworpen om, zo niet volledig vermijden, ongewenste uitkomsten zoals buitensporig risico of raciale en gendervooroordelen.
Een team onder leiding van onderzoekers van Stanford en de Universiteit van Massachusetts Amherst publiceerde op 22 november een paper Wetenschap voorstellen hoe dergelijke garanties kunnen worden gegeven. Het artikel schetst een nieuwe techniek die een vaag doel vertaalt, zoals het vermijden van gendervooroordelen, in de precieze wiskundige criteria waarmee een machine learning-algoritme een AI-toepassing zou kunnen trainen om dat gedrag te vermijden.
"We willen AI bevorderen die de waarden van zijn menselijke gebruikers respecteert en het vertrouwen rechtvaardigt dat we in autonome systemen stellen, " zei Emma Brunskill, een assistent-professor computerwetenschappen aan Stanford en senior auteur van het artikel.
wangedrag vermijden
Het werk is gebaseerd op het idee dat als "onveilige" of "oneerlijke" uitkomsten of gedrag wiskundig kunnen worden gedefinieerd, dan moet het mogelijk zijn om algoritmen te maken die kunnen leren van gegevens over hoe deze ongewenste resultaten met veel vertrouwen kunnen worden vermeden. De onderzoekers wilden ook een reeks technieken ontwikkelen waarmee gebruikers gemakkelijk kunnen specificeren welk soort ongewenst gedrag ze willen beperken en waarmee ontwerpers van machine learning met vertrouwen kunnen voorspellen dat een systeem dat is getraind met behulp van gegevens uit het verleden, kan worden vertrouwd wanneer het wordt toegepast in reële omstandigheden.
"We laten zien hoe de ontwerpers van machine learning-algoritmen het gemakkelijker kunnen maken voor mensen die AI in hun producten en diensten willen inbouwen om ongewenste resultaten of gedragingen te beschrijven die het AI-systeem met grote waarschijnlijkheid zal vermijden, " zei Philip Thomas, een assistent-professor computerwetenschappen aan de Universiteit van Massachusetts Amherst en eerste auteur van het artikel.
Eerlijkheid en veiligheid
De onderzoekers testten hun aanpak door te proberen de eerlijkheid te verbeteren van algoritmen die GPA's van universiteitsstudenten voorspellen op basis van examenresultaten, een gangbare praktijk die kan leiden tot gendervooroordelen. Met behulp van een experimentele dataset, ze gaven hun algoritme wiskundige instructies om te voorkomen dat ze een voorspellende methode ontwikkelden die GPA's voor één geslacht systematisch overschat of onderschat. Met deze instructies, het algoritme identificeerde een betere manier om GPA's van studenten te voorspellen met veel minder systematische gendervooroordelen dan bestaande methoden. Eerdere methoden worstelden in dit opzicht omdat ze geen ingebouwd eerlijkheidsfilter hadden of omdat de algoritmen die waren ontwikkeld om eerlijkheid te bereiken, te beperkt van omvang waren.
De groep ontwikkelde een ander algoritme en gebruikte het om veiligheid en prestaties in een geautomatiseerde insulinepomp in evenwicht te brengen. Dergelijke pompen moeten beslissen hoe groot of klein een dosis insuline aan een patiënt moet worden toegediend tijdens de maaltijden. Ideaal, de pomp levert net genoeg insuline om de bloedsuikerspiegel stabiel te houden. Te weinig insuline zorgt ervoor dat de bloedsuikerspiegel stijgt, leiden tot kortdurende ongemakken zoals misselijkheid, en een verhoogd risico op complicaties op de lange termijn, waaronder hart- en vaatziekten. Te veel en de bloedsuikerspiegel crasht - een potentieel dodelijke afloop.
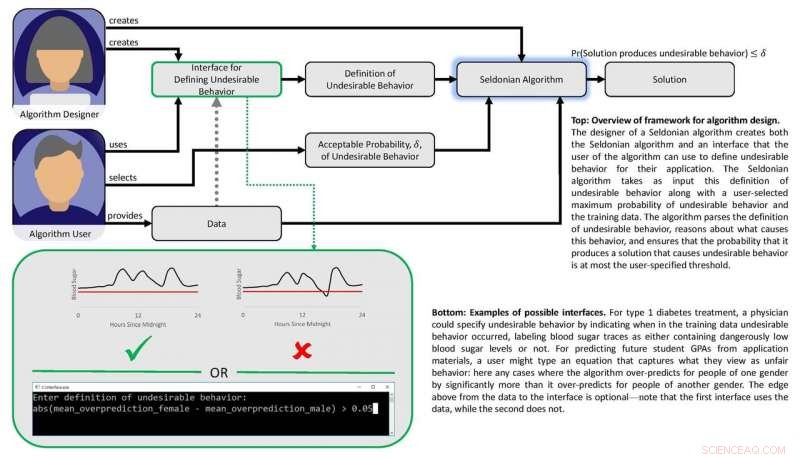
Diagram met het kader van papier. Krediet:Philip Thomas
Machine learning kan helpen door subtiele patronen te identificeren in de bloedsuikerreacties van een persoon op doses, maar bestaande methoden maken het niet gemakkelijk voor artsen om uitkomsten te specificeren die geautomatiseerde doseringsalgoritmen zouden moeten vermijden, zoals een crash met een lage bloedsuikerspiegel. Met behulp van een bloedglucosesimulator, Brunskill en Thomas lieten zien hoe pompen kunnen worden getraind om doseringen te identificeren die op die persoon zijn afgestemd, waardoor complicaties door over- of onderdosering worden voorkomen. Hoewel de groep niet klaar is om dit algoritme op echte mensen te testen, het wijst op een AI-benadering die uiteindelijk de kwaliteit van leven van diabetici zou kunnen verbeteren.
in hun Wetenschap papier, Brunskill en Thomas gebruiken de term "Seldonisch algoritme" om hun aanpak te definiëren, een verwijzing naar Hari Seldon, een personage uitgevonden door sciencefictionauteur Isaac Asimov, die eens drie wetten van robotica afkondigde, te beginnen met het bevel dat "een robot geen mens mag verwonden of, door passiviteit, laat een mens schade toebrengen."
Hoewel wordt erkend dat het veld nog lang niet de drie wetten garandeert, Thomas zei dat dit Seldonische raamwerk het voor machine learning-ontwerpers gemakkelijker zal maken om instructies voor het vermijden van gedrag in allerlei algoritmen in te bouwen. op een manier die hen in staat stelt de waarschijnlijkheid in te schatten dat getrainde systemen in de echte wereld goed zullen functioneren.
Brunskill zei dat dit voorgestelde raamwerk voortbouwt op de inspanningen die veel computerwetenschappers leveren om een evenwicht te vinden tussen het creëren van krachtige algoritmen en het ontwikkelen van methoden om hun betrouwbaarheid te waarborgen.
"Nadenken over hoe we algoritmen kunnen maken die waarden als veiligheid en eerlijkheid het best respecteren, is essentieel omdat de samenleving steeds meer afhankelijk is van AI, ' zei Brunskill.
 Onderzoekers lossen op hoe schimmels verbindingen produceren met potentiële farmaceutische toepassingen
Onderzoekers lossen op hoe schimmels verbindingen produceren met potentiële farmaceutische toepassingen- Nieuwe kooldioxide-adsorberende kristallen voor biomedische materialen die afhankelijk zijn van vormgeheugeneffect
- Eiwitporiën verpakt in polymeren maken superefficiënte filtratiemembranen
- 3D-geprinte Biomesh minimaliseert hernia-reparatiecomplicaties
- Bacteriën kunnen een toekomstige bron van elektriciteit zijn
- Hoe reproduceren regenwormen?
- Dit is het seizoen om ons afval opnieuw te ontwerpen en te verminderen
- Verstedelijking stimuleert antibioticaresistentie tegen microplastics in Chinese rivier
- Brandende zomers worden het nieuwe normaal in Europa:studeren
- Bossen kunnen tegen 2050 van CO2-put naar bron veranderen
Hoofdlijnen
- Plankton is de kleinste onbezongen held op aarde
- Afwijkende hyfen veroorzaakt door immuunreacties van de gastheer op plantpathogene schimmel
- Welke is eencellig: Prokaryoten of eukaryoten?
- De primaire primaire productiviteit berekenen
- Warmteminnende Australische mieren geloven in diversiteit, hint 74 soorten nieuw voor de wetenschap
- Antibiotica ontdekking in de afgrond
- Levensduur verlengd door remming van gemeenschappelijk enzym
- Kan een hersenscan je vertellen of je een crimineel gaat worden?
- Een benadering van het hele lichaam om chemosensorische cellen te begrijpen
- Rechtbank in Tokio wijst verzoek om borgtocht ex-Nissan-chef Ghosn af

- Franse Renault-werknemers onaangedaan als CEO Ghosn wordt berecht in Japan

- Nieuw AI-systeem bootst na hoe mensen objecten visualiseren en identificeren

- Zeer riskante onderneming:de voor- en nadelen van verzekeringsmaatschappijen die kunstmatige intelligentie omarmen

- Blockchain biedt belofte voor het veiligstellen van de wereldwijde toeleveringsketen


 Drugsrechtbank verkleint kans op recidive op lange termijn, nieuwe onderzoeksresultaten
Drugsrechtbank verkleint kans op recidive op lange termijn, nieuwe onderzoeksresultaten- Woedende bosbrand treft Duitse dorpen
- De elektrische eigenschappen van grafenen op atomair niveau begrijpen
- Gammastraling-telescopen kunnen ruimteschepen detecteren die worden aangedreven door een zwart gat
- Grootschalig onderzoek op wereldschaal onthult de mogelijke toekomstige impact van oceaanverzuring op de verspreiding van soorten
- Eerste schaalbare grafeengarens voor draagbaar textiel geproduceerd
- Waarom is biodiversiteit belangrijk?
- Bayer zet door met integratie van Monsanto terwijl aandelen lijden
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
