Wetenschap
Een gebruiksvriendelijke aanpak voor actief belonen van leren in robots
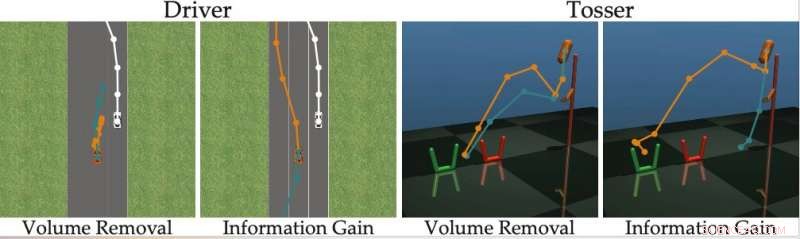
Krediet:Bıyık et al.
In recente jaren, onderzoekers hebben geprobeerd methoden te ontwikkelen waarmee robots nieuwe vaardigheden kunnen leren. Een optie is dat een robot deze nieuwe vaardigheden van mensen leert, vragen stellen wanneer hij niet zeker is hoe hij zich moet gedragen, en leren van de reacties van de menselijke gebruiker.
Een onderzoeksteam van Stanford University heeft onlangs een gebruiksvriendelijke benadering van actief belonend leren ontwikkeld waarmee robots kunnen worden getraind door menselijke gebruikers hun vragen te laten beantwoorden. Deze nieuwe aanpak, gepresenteerd in een paper dat vooraf is gepubliceerd op arXiv, traint robots om vragen te stellen die voor een menselijke gebruiker gemakkelijk te beantwoorden zijn en die niet overbodig of onnodig zijn.
"Onze groep is geïnteresseerd in hoe robots kunnen leren wat mensen willen, " vertelden de onderzoekers TechXplore via e-mail. "Een intuïtieve manier om te leren is door vragen te stellen. Bijvoorbeeld, rijd je liever in een zelfrijdende auto voorzichtig of agressief? Moet deze zelfrijdende auto voor of achter een door mensen bestuurde auto invoegen?"
De belangrijkste veronderstelling achter de recente studie is dat idealiter, robots moeten informatieve vragen stellen die zoveel mogelijk informatie van menselijke gebruikers losmaken. Met andere woorden, een robot moet kunnen begrijpen wat een mens nodig heeft of wil doen door zo min mogelijk vragen te stellen.
In werkelijkheid, echter, de meeste bestaande trainingsbenaderingen op basis van het beantwoorden van vragen houden er geen rekening mee hoe gemakkelijk het voor menselijke gebruikers zal zijn om specifieke vragen te beantwoorden die door de robot zijn geformuleerd. Dit leidt er vaak toe dat gebruikers hun tijd verspillen met het beantwoorden van onnodige vragen of niet in staat zijn om met zekerheid te antwoorden.
"We ontdekten dat de meeste state-of-the-art algoritmen de menselijke alternatieven laten zien die (bijna) niet te onderscheiden zijn, voorkomen dat de persoon de vragen van de robot correct beantwoordt, " zeiden de onderzoekers. "Terugkerend naar ons voorbeeld, deze benaderingen zouden kunnen vragen:"Zou je liever invoegen voor de door mensen aangedreven auto met een snelheid van 49 mph, of een snelheid van 50 mph?" Dit kan informatief zijn voor de robot om te beslissen of de mens sneller dan 50 mph wil gaan of niet, maar de opties zijn zo dichtbij dat mensen niet betrouwbaar kunnen reageren."
Om de beperkingen van bestaande actieve leermethoden te overwinnen, de onderzoekers ontwikkelden een algoritme dat effectievere vragen kan selecteren om menselijke gebruikers te stellen. Het algoritme identificeert vragen die de onzekerheid van de robot over de voorkeuren van een menselijke gebruiker het meest verminderen (d.w.z. die de informatiewinst maximaliseren), terwijl u ook bedenkt hoe gemakkelijk het voor een menselijke gebruiker zal zijn om ze te beantwoorden.

Krediet:Bıyık et al.
"Geïnspireerd door de tekortkomingen van eerdere werken, toen we dit algoritme ontwikkelden, we hebben ons gericht op het verklaren van het vermogen van de mens om daadwerkelijk de vragen te beantwoorden die de robot stelt, " zeiden de onderzoekers. "Dit is gebaseerd op het idee dat alleen robots die verantwoordelijk zijn voor het vermogen van de mens om te antwoorden, nauwkeurig en efficiënt kunnen leren wat mensen willen."
De onderzoekers berekenden de informatiewinst door de afname in entropie te meten (d.w.z. een mate van onzekerheid) over de voorkeuren van de menselijke gebruiker als functie van de vraag die door de robot wordt gesteld. Met andere woorden, een vraag die de informatiewinst maximaliseert, zal de onzekerheid van de robot over wat de voorkeuren van de menselijke gebruiker zijn het meest verminderen. Dit geeft robots een formeel doel dat ze kunnen gebruiken om vragen te selecteren die het meest informatief zijn.
"Een mooie eigenschap van informatiewinst is dat het inherent de onzekerheid van de robot maximaliseert (zodat de robot veel leert van de vraag) en tegelijkertijd de onzekerheid van de mens minimaliseert (zodat de vraag voor de mens gemakkelijk te beantwoorden is), " legden de onderzoekers uit. "Het genereren van de vragen met behulp van informatievergaring verbetert dus actief leren, niet alleen omdat de vragen maximaal informatief zijn, maar ook omdat de mens minder foutieve antwoorden geeft."
De door de onderzoekers bedachte aanpak kiest gretig de vraag die de informatiewinst bij elke tijdstap maximaliseert. Eigenlijk, de robot handhaaft een overtuiging (d.w.z. een kansverdeling) over de voorkeuren van de gebruiker waarmee het interageert en steekproeven uit zowel deze overtuiging als de ruimte van mogelijke vragen.
uiteindelijk, de robot kiest de vraag die de meeste informatie oplevert over de huidige verdeling van mogelijke menselijke voorkeuren. Vervolgens, het actualiseert zijn overtuigingen over wat de gebruiker wil op basis van het antwoord dat het ontvangt. Dit proces wordt continu herhaald, waardoor de robot zijn prestaties geleidelijk kan verbeteren door te leren over de voorkeuren van de gebruiker.
"We hebben een rekenkundig hanteerbare methode ontwikkeld waarmee we snel menselijke voorkeuren kunnen ontdekken voor echte robottaken, beter presteren dan eerdere methoden, " zeiden de onderzoekers. "In onze studie, gebruikers gaven de voorkeur aan onze methode boven andere state-of-the-art technieken."
In hun studie hebben het op Stanford gebaseerde team toonde aan dat het trainen van een robot om vragen te stellen die de informatiewinst maximaliseren, dezelfde rekenkundige complexiteit heeft als state-of-the-art methoden. Met andere woorden, het is niet moeilijker voor de robot om deze informatieve vragen te vinden, vergeleken met die van andere benaderingen.
"We wijzen er ook op dat onze aanpak verschillende wenselijke wiskundige eigenschappen heeft, zoals submodulariteit, waardoor we de uitbreidingen en theoretische grenzen die voor eerdere benaderingen zijn ontwikkeld, kunnen gebruiken en ook met onze methode kunnen gebruiken, " zeiden de onderzoekers. "Bijvoorbeeld, we kunnen eerdere werken gebruiken om verschillende informatieve vragen tegelijk te vinden, in plaats van naar één vraag tegelijk te zoeken."
Het team evalueerde hun actieve beloningsleerbenadering in een reeks simulaties en ontdekte dat robots hierdoor sneller en nauwkeuriger menselijke voorkeuren kunnen begrijpen dan andere geavanceerde methoden. Dit bleek ook het geval te zijn in situaties waarin mensen moeilijke vragen correct kunnen beantwoorden of wanneer hun antwoord "ik weet het niet" is.
De onderzoekers voerden ook een gebruikersonderzoek uit waarin ze menselijke deelnemers vroegen om vragen te beantwoorden die door hun methode waren gegenereerd en anderen die werden gegenereerd met behulp van andere state-of-the-art benaderingen. De feedback die ze hebben verzameld, suggereert dat mensen vragen die door hun aanpak worden gegenereerd, veel gemakkelijker te beantwoorden vinden. In aanvulling, gebruikers waren vaak van mening dat robots die de nieuwe methode gebruikten, een nauwkeuriger weergave van hun voorkeuren hadden gekregen dan met eerder voorgestelde benaderingen.
"Gezien al onze bijdragen samen, we hebben een stap gezet om robots in staat te stellen menselijke voorkeuren te bepalen, " zeiden de onderzoekers. "We hebben aangetoond dat het echte doel dat we oorspronkelijk wilden dat de robot zou maximaliseren - vragen stellen om zoveel mogelijk informatie te krijgen - eigenlijk kan worden opgelost met dezelfde rekenkundige complexiteit als bestaande methoden."
In de toekomst, de actieve beloningsleertechniek die door dit team van onderzoekers is ontwikkeld, zou kunnen helpen om robots effectiever te trainen, waardoor ze beter zijn afgestemd op de voorkeuren van de gebruiker. In aanvulling, it could be used to teach robots to ask questions that humans can easily understand and answer. In hun toekomstige studies, the researchers would also like to investigate methods for training robots to give useful explanations for their actions.
"We are excited about robots that not only ask good questions, but can also explain why they are asking those questions, " the researchers said. "We imagine a scenario where a self-driving car visualizes two different merging options for the human, and then clarifies that it is asking about these options because it is rush hour, and it wants to determine whether it should behave more or less aggressively."
© 2019 Wetenschap X Netwerk
 Oppervlakte-oxygenaatsoorten verbeteren de door kobalt gekatalyseerde Fischer-Tropsch-synthese
Oppervlakte-oxygenaatsoorten verbeteren de door kobalt gekatalyseerde Fischer-Tropsch-synthese- Studie is gericht op het stimuleren van de antitumorale activiteit van een verbinding die is geëxtraheerd uit een Amazone-plant
- Nieuwe chemische methode maakt het gemakkelijker om vervuilende pesticiden uit water te halen
- Lager nikkelgehalte en verbeterde stabiliteit en prestaties in keramische brandstofcellen
- Een mogelijk einde aan eeuwigdurende chemicaliën
Hoofdlijnen
- Nieuwe strategie zou bestaande medicijnen in staat kunnen stellen bacteriën te doden die chronische infecties veroorzaken
- Hoe kunnen nieuwe cellen iemands gezichtsvermogen herstellen?
- Hoe te lezen Proteïne elektroforese
- Opkomende ziekte brengt Noord-Amerikaanse kikkers verder in gevaar
- Een biologische oplossing voor het afvangen en recyclen van koolstof?
- Wetenschappers ontwikkelen aardnoot die resistent is tegen aflatoxine
- Wat zijn de drie belangrijkste verschillen tussen een plantencel en een dierencel?
- Zangvogelpopulaties kunnen wijzen op problemen in noordwestelijke bossen
- Cheerleaders helpen bij het ontdekken van bacteriën die beter groeien zonder zwaartekracht
- Dating-app Tinder verlaat ouderlijk huis

- American Airlines bestelt 47 Boeing 787's, annuleert A350 bestelling

- Hoe Google een robothond leert te bewegen als een echte hond

- Een klein implanteerbaar apparaat kan het zuurstofgehalte in het weefsel in het lichaam meten

- 5G:een revolutie niet zonder risico's


 Graafwespen en hun chemie
Graafwespen en hun chemie- Wat zijn verschillende soorten blizzards?
- Google-medewerkers willen plug-in voor plan voor zoeken in China
- Nieuwe combinaties van nanomaterialen zorgen voor een sprong in infraroodtechnologie
- Onderzoekers vinden een nieuwe manier om autonome kwantumfouten te corrigeren
- Przybylskis-ster is een extreem langzame rotator, studie vondsten
- Hoe tarwe te oogsten met een Case IH 2588 Combineer
- Onderbewerkte slachtoffers van moderne slavernij ondergaan extra uitbuiting
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
