Wetenschap
Algoritmen zijn overal, maar wat is er voor nodig om ze te vertrouwen?
Een algoritme volgt gewoon regels die direct of indirect door een mens zijn ontworpen. Krediet:Shutterstock/miljard foto's
De rol van algoritmen in ons leven groeit snel, van het simpelweg suggereren van online zoekresultaten of content in onze social media feed, tot meer kritieke zaken, zoals het helpen van artsen om ons kankerrisico te bepalen.
Maar hoe weten we dat we de beslissing van een algoritme kunnen vertrouwen? In juni, bijna 100 chauffeurs in de Verenigde Staten hebben op de harde manier geleerd dat algoritmen het soms heel erg mis kunnen hebben.
Google Maps zorgde ervoor dat ze allemaal vast kwamen te zitten op een modderige privéweg in een mislukte omweg om te ontsnappen aan een verkeersopstopping op weg naar Denver International Airport, in Colorado.
Nu onze samenleving steeds afhankelijker wordt van algoritmen voor advies en besluitvorming, het wordt dringend om de netelige kwestie aan te pakken van hoe we ze kunnen vertrouwen.
Algoritmen worden regelmatig beschuldigd van vooringenomenheid en discriminatie. Ze hebben de bezorgdheid gewekt van Amerikaanse politici, te midden van beweringen dat we blanke mannen hebben die gezichtsherkenningsalgoritmen ontwikkelen die zijn getraind om alleen goed te werken voor blanke mannen.
Maar algoritmen zijn niets meer dan computerprogramma's die beslissingen nemen op basis van regels:ofwel regels die we ze hebben gegeven, of regels die ze zelf bedachten op basis van voorbeelden die we ze gaven.
In beide gevallen, mensen hebben de controle over deze algoritmen en hoe ze zich gedragen. Als een algoritme gebrekkig is, het is ons werk.
Dus voordat we allemaal in een metaforische (of letterlijke!) modderige file belanden, er is een dringende behoefte om opnieuw te bekijken hoe wij mensen ervoor kiezen om die regels te stresstesten en vertrouwen te winnen in algoritmen.
Algoritmes op de proef gesteld, soort van
Mensen zijn van nature verdachte wezens, maar de meesten van ons kunnen door bewijs worden overtuigd.
Als we genoeg testvoorbeelden hebben - met bekende juiste antwoorden - ontwikkelen we vertrouwen als een algoritme consequent het juiste antwoord geeft, en niet alleen voor voor de hand liggende voorbeelden, maar ook voor de uitdagende, realistische en diverse voorbeelden. Dan kunnen we ervan overtuigd zijn dat het algoritme onbevooroordeeld en betrouwbaar is.
Klinkt makkelijk genoeg, Rechtsaf? Maar is dit hoe algoritmen meestal worden getest? Het is moeilijker dan het klinkt om ervoor te zorgen dat testvoorbeelden onbevooroordeeld zijn en representatief zijn voor alle mogelijke scenario's die zich kunnen voordoen.
vaker, goed bestudeerde benchmarkvoorbeelden worden gebruikt omdat ze gemakkelijk op websites te vinden zijn. (Microsoft had een database met gezichten van beroemdheden voor het testen van algoritmen voor gezichtsherkenning, maar deze is onlangs verwijderd vanwege privacykwesties.)
Vergelijking van algoritmen is ook gemakkelijker wanneer ze worden getest op gedeelde benchmarks, maar deze testvoorbeelden worden zelden onderzocht op hun vooroordelen. Nog erger, de prestaties van algoritmen worden doorgaans gemiddeld gerapporteerd over de testvoorbeelden.
Helaas, weten dat een algoritme gemiddeld goed presteert, zegt niets over de vraag of we het in specifieke gevallen kunnen vertrouwen.
Het is niet verwonderlijk om te lezen dat artsen sceptisch zijn over het algoritme van Google voor de diagnose van kanker, die gemiddeld 89% nauwkeurigheid biedt. Hoe weet een arts of zijn patiënt tot de ongelukkige 11% behoort met een verkeerde diagnose?
Met de toenemende vraag naar gepersonaliseerde geneeskunde op maat van het individu (niet alleen de heer/mevrouw Average), en met gemiddelden waarvan bekend is dat ze allerlei soorten zonden verbergen, de gemiddelde resultaten zullen het menselijk vertrouwen niet winnen.
De behoefte aan nieuwe testprotocollen
Het is duidelijk niet streng genoeg om een aantal voorbeelden te testen - goed bestudeerde benchmarks of niet - zonder te bewijzen dat ze onbevooroordeeld zijn. en trek vervolgens conclusies over de betrouwbaarheid van een algoritme gemiddeld.
En toch is dit paradoxaal genoeg de benadering waarvan onderzoekslaboratoria over de hele wereld afhankelijk zijn om hun algoritmische spieren te spannen. Het academische peer-reviewproces versterkt deze overgeërfde en zelden bevraagde testprocedures.
Een nieuw algoritme is publiceerbaar als het gemiddeld beter is dan bestaande algoritmen op goed bestudeerde benchmarkvoorbeelden. Als het op deze manier niet concurrerend is, het is ofwel verborgen voor verder onderzoek door peer-reviews, of er worden nieuwe voorbeelden gepresenteerd waarvoor het algoritme nuttig lijkt.
Op deze manier, een warme, flatterend licht schijnt op elk nieuw gepubliceerd algoritme, met weinig poging om zijn sterke en zwakke punten te stress-testen, en presenteer het met wratten en zo. Het is de computerwetenschappelijke versie van medische onderzoekers die de volledige resultaten van klinische proeven niet publiceren.
Naarmate algoritmisch vertrouwen belangrijker wordt, we moeten deze methodologie dringend actualiseren om te onderzoeken of de gekozen testvoorbeelden geschikt zijn voor het beoogde doel. Tot dusver, onderzoekers zijn weerhouden van een meer rigoureuze analyse door het gebrek aan geschikte hulpmiddelen.
We hebben een betere stresstest gebouwd
Na meer dan tien jaar onderzoek, mijn team heeft een nieuwe online tool voor algoritmeanalyse gelanceerd met de naam MATILDA:Melbourne Algorithm Test Instance Library met Data Analytics.
Het helpt algoritmen strenger te testen door krachtige visualisaties van een probleem te maken, met alle scenario's of voorbeelden die een algoritme in overweging moet nemen voor uitgebreide tests.
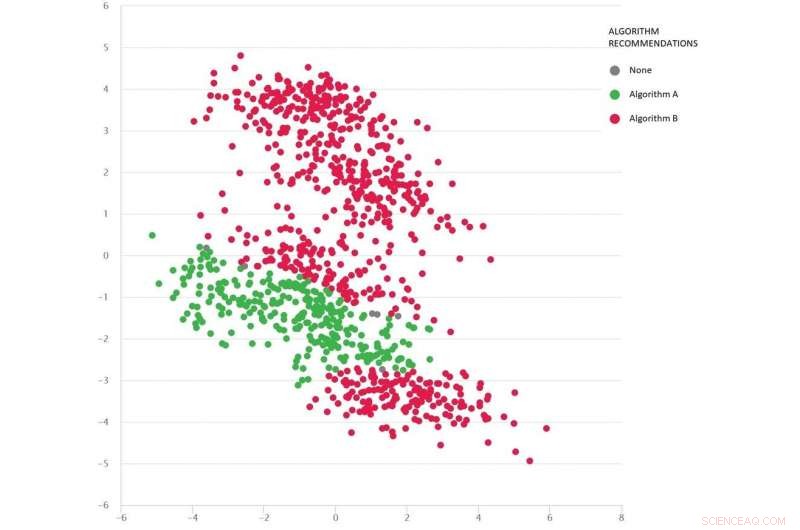
Een Google-maps-achtig probleem met diverse testscenario's als stippen:Algoritme B (rood) is gemiddeld het beste, maar algoritme A (groen) is in veel gevallen beter. Krediet:MATILDA, Auteur verstrekt
MATILDA identificeert de unieke sterke en zwakke punten van elk algoritme, aanbevelen welke van de beschikbare algoritmen in verschillende scenario's moeten worden gebruikt en waarom.
Bijvoorbeeld, als de recente regen onverharde wegen in modder heeft veranderd, sommige "kortste-pad"-algoritmen kunnen onbetrouwbaar zijn, tenzij ze kunnen anticiperen op de waarschijnlijke impact van het weer op de reistijden bij het adviseren van de snelste route. Tenzij ontwikkelaars dergelijke scenario's testen, zullen ze dergelijke zwakheden nooit weten totdat het te laat is en we vastzitten in de modder.
MATILDA helpt ons de diversiteit en volledigheid van benchmarks te zien, en waar nieuwe testvoorbeelden moeten worden ontworpen om alle hoeken en gaten van de mogelijke ruimte te vullen waarin het algoritme zou kunnen worden gevraagd om te werken.
De onderstaande afbeelding toont een gevarieerde reeks scenario's (punten) voor een probleem van het type Google Maps. Elk scenario varieert van omstandigheden, zoals de herkomst- en bestemmingslocaties, het beschikbare wegennet, weersomstandigheden, reistijden op verschillende wegen - en al deze informatie wordt wiskundig vastgelegd en samengevat door de tweedimensionale coördinaten van elk scenario in de ruimte.
Twee algoritmen worden vergeleken (rood en groen) om te zien welke de kortste route kan vinden. Van elk algoritme is bewezen dat het het beste is (of als onbetrouwbaar) in verschillende regio's, afhankelijk van hoe het presteert in deze geteste scenario's.
We kunnen ook goed inschatten welk algoritme waarschijnlijk het beste is voor de ontbrekende scenario's (hiaten) die we nog niet hebben getest.
De wiskunde achter MATILDA helpt bij het creëren van deze visualisatie, door analyse van betrouwbaarheidsgegevens van algoritmen uit testscenario's, en een manier vinden om de patronen gemakkelijk te zien.
Door de inzichten en uitleg kunnen we het beste algoritme kiezen voor het probleem, in plaats van onze vingers te kruisen en te hopen dat we het algoritme kunnen vertrouwen dat gemiddeld het beste presteert.
Door algoritmen op deze manier rigoureus te testen - wratten en al - zouden we het risico op malafide algoritmebeslissingen moeten verminderen, het vertrouwen van de heer/mevrouw Average veiligstellen, en misschien zelfs de meest sceptische mensen.
Dit artikel is opnieuw gepubliceerd vanuit The Conversation onder een Creative Commons-licentie. Lees het originele artikel. 

Hoofdlijnen
- Vergelijking & identificatie van kikkers en menselijke bloedcellen
- Berekening van de tijd voor celverdubbeling
- Waar bevindt het DNA zich in een cel?
- Japanse wetenschappers kweken medicijnen in kippeneieren
- Hoeveelheid water in stamcellen kan zijn lot bepalen als vet of bot
- Hoe hoge bomen suikers verplaatsen
- Wat zijn natuurlijke polymeren?
Enkele van de meest voorkomende voorbeelden van polymeren zijn kunststoffen en eiwitten. Hoewel plastics het resultaat zijn van het industriële proces, zijn eiwitten rijk aan aard en worden ze daarom meestal als een
- Hoe maak je een Paper Mache Cell
- Blade runner benen geven verminkte Thaise hond nieuw leven
- Een evolutionaire robotica-aanpak voor samenwerking tussen robotzwerm

- Wiskunde gebruiken om muzieknoten naadloos te laten samenvloeien

- Amerikaans chipbedrijf zegt dat het sommige items legaal aan Huawei mag verkopen

- Gini Rometty, 1e vrouwelijke CEO bij IBM, in april aftreden

- Toekomst van Airbuss A380 superjumbo twijfelachtig naarmate de vraag afneemt


 Waarom livestreamers hun producten met een pokerface moeten verkopen - niet met een glimlach
Waarom livestreamers hun producten met een pokerface moeten verkopen - niet met een glimlach- Snelheid van kernreactie in exploderende sterren
- Team past virus op nanoschaal aan om peptidegeneesmiddelen aan cellen te leveren, weefsels
- Prehistorische tanden geven hun geheimen prijs
- Veranderingen in suikerachtige moleculen aan het oppervlak helpen kanker uitzaaien
- Sneeuw valt anders op nanoschaal
- Nieuwe katalysator realiseert ongekende activiteiten
- Head Start verlaagt kans op armoede bij volwassenen
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
