Wetenschap
Onderzoekers ontwikkelen een methode om computergegenereerde tekst te identificeren

Krediet:Petr Kratochvil/publiek domein
In een wereld van Deep Fakes en veel te menselijke natuurlijke taal AI, onderzoekers van de Harvard John A. Paulson School of Engineering and Applied Sciences (SEAS) en IBM Research vroegen:is er een betere manier om mensen te helpen door AI gegenereerde tekst te detecteren?
Die vraag bracht Sebastian Gehrmann ertoe, een doctoraat kandidaat bij SEAS, en Hendrik Strobelt, een onderzoeker bij IBM, een statistische methode te ontwikkelen, samen met een open access interactieve tool, om AI-gegenereerde tekst te detecteren.
Natuurlijke taalgeneratoren zijn getraind op tientallen miljoenen online teksten en bootsen menselijke taal na door de woorden te voorspellen die het vaakst na elkaar komen. Bijvoorbeeld, de woorden "hebben", "ben" en "was" komen statisch het meest waarschijnlijk na het woord "ik".
Met behulp van dat idee, Gehrmann en Strobelt ontwikkelden een methode die, in plaats van fouten in de tekst te identificeren, identificeert tekst die te voorspelbaar is.
"Het idee dat we hadden was dat naarmate modellen beter en beter worden, ze gaan van absoluut slechter dan mensen, die detecteerbaar is, zo goed als of beter dan de mens, die met conventionele benaderingen moeilijk te detecteren zijn, ’ zei Gehrmann.
"Voordat, je kon aan alle fouten zien dat de tekst machinaal was gegenereerd, "zei Strobelt. "Nu, het zijn niet langer de fouten, maar het gebruik van zeer waarschijnlijke (en enigszins saaie) woorden die door een machine gegenereerde tekst oproepen. Met dit hulpmiddel, mensen en AI kunnen samenwerken om valse tekst te detecteren."
Gehrmann en Strobelt presenteren hun onderzoek, waarvan Alexander Rush co-auteur was, Associate in Computer Science bij SEAS, op de conferentie van de Association for Computational Linguistics (ACL) op 28 juli - 2 augustus.
De methode van Gehrmann en Strobelt, bekend als GLTR, is gebaseerd op een model dat is getraind op 45 miljoen teksten van websites - de openbare versie van het OpenAI-model, GPT-2. Omdat het GPT-2 gebruikt om gegenereerde tekst te detecteren, GLTR werkt het beste tegen GPT-2, maar doet het ook goed tegen andere modellen.
Dit is hoe het werkt:
Als u een tekstpassage in de tool invoert, het markeert de tekst in het groen, geel, rood of paars, elke kleur staat voor de voorspelbaarheid van het woord in de context van het woord ervoor. Groen betekent dat het woord erg voorspelbaar was, geel, redelijk voorspelbaar, rood niet erg voorspelbaar en paars betekent dat het model het woord helemaal niet had voorspeld.
Dus een alinea met tekst gegenereerd door GPT-2 ziet er als volgt uit:

Krediet:Harvard University
om te vergelijken, dit is een echte New York Times artikel:
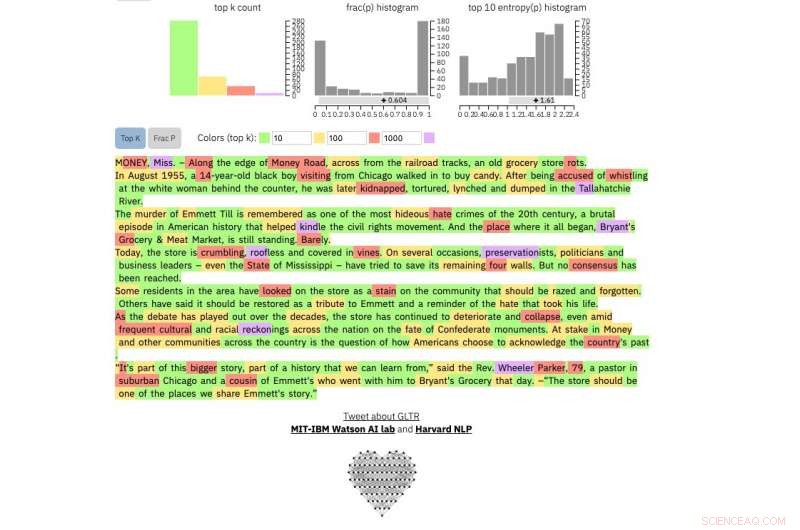
Krediet:Harvard University
En dit is een fragment uit misschien wel de meest onvoorspelbare menselijke tekst ooit geschreven, James Joyce's Finnegans Wake :
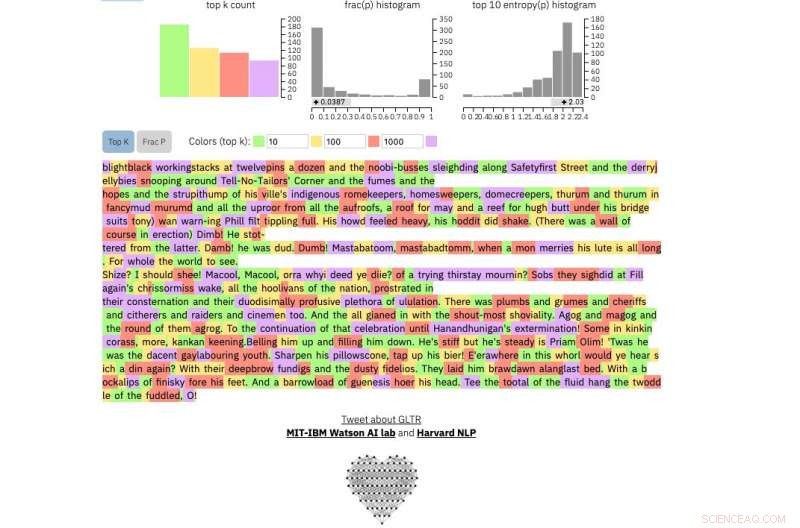
Krediet:Harvard University
De methode is niet bedoeld om mensen te vervangen bij het identificeren van valse teksten, maar om de menselijke intuïtie en begrip te ondersteunen. De onderzoekers testten het model met een groep studenten in een SEAS Computer Science-klas.
Zonder het model, de studenten konden ongeveer 50 procent van de door AI gegenereerde tekst identificeren. Met de kleuroverlay, de studenten konden 72 procent identificeren.
Gehrmann en Strobelt zeggen dat met een beetje training en ervaring met het programma, het aantal zou nog verder kunnen verbeteren.
"Ons doel is om mens- en AI-samenwerkingssystemen te creëren, " zei Gehrmann. "Dit onderzoek is erop gericht mensen meer informatie te geven, zodat ze een weloverwogen beslissing kunnen nemen over wat echt en wat nep is."
 Nutriënten tegen kanker in slabladeren nemen toe tijdens de houdbaarheid na de oogst
Nutriënten tegen kanker in slabladeren nemen toe tijdens de houdbaarheid na de oogst- Wetenschappers ontwikkelen nieuw concept van beperkte katalyse onder 2D-materialen
- Kooldioxide transformeren
- Bio-geïnspireerde katalysatoren die in water werken openen de deur naar groenere chemische processen
- De zich snel ontvouwende toekomst van slimme stoffen
- Gebouwd zand zuigt verontreinigende stoffen in het regenwater op
- Natuurkundigen tonen aan dat interacties tussen rook en wolken een onverwacht verkoelend effect hebben
- Trumps plannen voor offshore olieboringen negeren de lessen van BP Deepwater Horizon
- Wat is de oorzaak van de dag /nachtcyclus op aarde?
- Het geschenk van de delicate dadelpalmdrank uit Tunesië
Hoofdlijnen
- Als je asperges kunt ruiken in de urine,
- DNA versus RNA: wat zijn de overeenkomsten en verschillen? (met diagram)
- Is alle pijn mentaal?
- Nieuwe Peruaanse vogelsoorten ontdekt door zijn gezang
- De meeste zeeschildpadden zijn nu vrouwelijk in het noorden van het Great Barrier Reef
- Schimmelmicroben als biomeststoffen in landbouw en tuinieren:is de beloning groter dan het risico?
- Prokaryotische celstructuur
- Het leefgebied van de panda krimpt, steeds meer gefragmenteerd worden
- Het genoom van Leishmania onthult hoe deze parasiet zich aanpast aan veranderingen in de omgeving
- Kan het verbergen van likes Facebook eerlijker maken en nepnieuws in toom houden? De wetenschap zegt misschien

- Waarom je je handige kaart-app niet altijd kunt vertrouwen

- Een multi-granulariteit redeneringskader voor herkenning van sociale relaties
- Waarom we iWitnessed hebben gemaakt, een app om bewijs te verzamelen

- Kiezers in de woonplaats van Google beslissen over werknemersbelasting


 Ontwerp van een nieuw fluorescerend hybride materiaal dat van kleur verandert afhankelijk van de richting van het licht
Ontwerp van een nieuw fluorescerend hybride materiaal dat van kleur verandert afhankelijk van de richting van het licht- Hoe maak je een platenspeler voor een Kids Science-project
- De vooruitgang van de kwantumtechnologie kan helpen leiden tot verbeteringen in computergebruik, gegevensverwerking
- Wegenloze bossen zien meer branden en grotere hevigheid, maar vuurvastheid is het resultaat
- Hoe werkt een Paper Cup-telefoon?
- Hoe katrollen te gebruiken voor snelheidsvermindering
- Onderzoekers printen zonnecellen op toiletpapier, andere delicate materialen (met video)
- Sneeuw overvalt het Amerikaanse middenwesten terwijl het zich schrap zet voor extreme kou
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
