Wetenschap
Een hiërarchisch op RNN gebaseerd model om scènegrafieken voor afbeeldingen te voorspellen
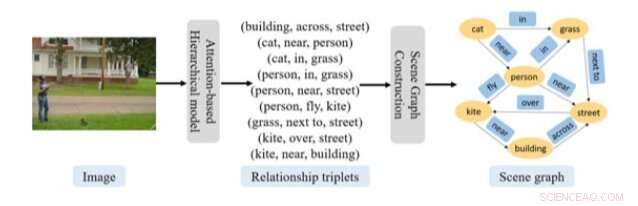
Algemene procedure van voorspelling van scènegrafieken voorgesteld in de recente paper. Krediet:Gao et al.
Onderzoekers van de Universiteit van Shanghai hebben onlangs een nieuwe aanpak ontwikkeld op basis van terugkerende neurale netwerken (RNN's) om scènegrafieken uit afbeeldingen te voorspellen. Hun aanpak omvat een model dat bestaat uit twee op aandacht gebaseerde RNN's, evenals een entiteitslokalisatiecomponent.
In de afgelopen tien jaar of zo, onderzoekers op het gebied van kunstmatige intelligentie (AI) hebben een verscheidenheid aan automatische tools ontwikkeld voor het beheren, analyseren en ophalen van digitale beelden. Om de inhoud van afbeeldingen weer te geven, traditionele benaderingen gebruiken doorgaans trefwoorden of functies voor meerdere weergaven. Echter, vertrouwen op functies of trefwoorden leidt vaak tot een beperkt begrip van afbeeldingen, het niet verstrekken van uitgebreide kennis over hen.
Om deze tekortkomingen aan te pakken, een paar jaar geleden, een team van onderzoekers aan de Stanford University, Max Planck Instituut voor Informatica, Yahoo Labs en Snapchat stelden het gebruik van een 'scènegrafiek, ' een soort datastructuur voor het beschrijven van visuele concepten in een afbeelding. Scènegrafieken kunnen de beschrijving van een in afbeeldingen weergegeven scène opslaan als een gestructureerde grafiek waarin knooppunten objectinformatie vertegenwoordigen en randen voorspellingen bieden tussen twee knooppunten.
Deze gestructureerde weergaven kunnen gebruikers helpen bij het beheren van digitale afbeeldingen. Echter, het voorspellen van een scènegrafiek is vaak een uitdaging, omdat het effectieve hulpmiddelen vereist om objecten te herkennen, evenals hun attributen en interacties tussen hen.
Hoewel er verschillende bestaande benaderingen zijn om scènegrafieken te voorspellen, de meeste hiervan hebben aanzienlijke beperkingen. In hun studie hebben de onderzoekers van Shanghai University wilden een neuraal netwerkgebaseerd model ontwikkelen om scènegrafieken te voorspellen vanuit een visueel aandachtsgericht perspectief.
"Een scènegrafiek biedt een krachtige tussenliggende kennisstructuur voor verschillende visuele taken, inclusief het ophalen van semantische afbeeldingen, ondertiteling van afbeeldingen, en visuele vragen beantwoorden, " schreven de onderzoekers in hun paper, die werd gepubliceerd op Wiley Online Library. "In deze krant, de taak van het voorspellen van een scènegrafiek voor een afbeelding wordt geformuleerd als twee met elkaar verbonden problemen, d.w.z. het herkennen van de relatiedrieling, gestructureerd als, en het construeren van de scènegrafiek van de herkende relatiedrielingen."
De aanpak die door dit team van onderzoekers is bedacht, heeft twee belangrijke componenten:de ene was gericht op het herkennen van wat zij 'relatie-tripletten' noemen en de andere op het construeren van een scènegrafiek. Om relatiedrielingen te herkennen, de onderzoekers gebruikten een model dat bestaat uit twee op aandacht gebaseerde RNN's in een hiërarchische organisatie.
"Het eerste netwerk genereert een onderwerpvector voor elk relatietriplet, terwijl het tweede netwerk elk woord in die relatietriplet voorspelt gezien de onderwerpvector, " legden de onderzoekers uit in hun paper. "Deze aanpak legt met succes de compositorische structuur en contextuele afhankelijkheid van een afbeelding vast en de relatiedrietallen die de scène beschrijven."
Zodra dit op RNN gebaseerde model relevante informatie uit een afbeelding heeft gehaald, het tweede onderdeel van hun aanpak gebruikt deze gegevens om scènegrafieken te construeren. Voor deze stap, de onderzoekers gebruikten een entiteitslokalisatiebenadering, die de structuur van de grafiek kan bepalen met behulp van de beschikbare aandachtsinformatie. Naast deze twee componenten, de onderzoekers gebruikten een algoritme om het proces te verduidelijken waarmee hun aanpak de gegenereerde relatie-triplet-informatie omzet in een scènegrafiek.
Hun aanpak werd geëvalueerd met behulp van de populaire visuele genoom (VG) dataset en de visuele relatie dataset (VRD). Voor hun studie hebben de onderzoekers annoteerden de afbeeldingen in deze datasets met een set drielingen, elk onderwerp en objectpaar labelen met locatie-informatie.
"De resultaten van experimenten met twee populaire datasets tonen aan dat de hiërarchische terugkerende benadering vanuit het op visuele aandacht gerichte perspectief binnen ons model een duidelijke verbetering in de resultaten heeft ten opzichte van basismodellen, " schreven de onderzoekers. "In toekomstig werk, we zijn van plan de scènegrafiek te verrijken met semantiek op hoog niveau en meer gediversifieerde attributen."
© 2019 Wetenschap X Netwerk
 Forensisch chemicus gebruikt zweet om personen op plaats delict te onderscheiden
Forensisch chemicus gebruikt zweet om personen op plaats delict te onderscheiden- Doorbraak in elektrolyse van zuur water via katalysatoren op basis van ruthenium
- Ingenieurs maken transistors en elektronische apparaten volledig van draad
- Een voorbeeld van plasmonen die rechtstreeks invloed hebben op moleculen
- Creativiteit bij onderzoekers stimuleren:hoe automatisering een revolutie teweeg kan brengen in materiaalonderzoek
- Praying Mantis Feiten voor kinderen
- Studie onthult nieuwe aanwijzingen over dodelijkste lawine van Mount Everest
- Inentingstheorie:het vaccin tegen klimaatdesinformatie
- The Scream:Wat waren die kleurrijke, golvende wolken in het beroemde schilderij van Edvard Munch?
- Verschillen tussen ecocentrisch en biocentrisch
Hoofdlijnen
- Wilde zwijnengif veldtesten in Texas, Alabama in 2018
- Scented Cleaning Products: The New Smoking?
- Celgroei en -deling: een overzicht van mitose en meiose
- Gebruik van DNA-extractie
- Graafwespen en hun chemie
- Voorkeuren voor het eten van insecten voorspellen na ontbossing
- Officiële vishandel onderschat wereldwijde vangsten enorm
- Politieke instabiliteit en zwak bestuur leiden tot verlies van soorten, studie vondsten
- Australische honden getraind om bedreigde diersoorten op te sporen
- VS lanceert onderzoek naar Frances geplande belasting voor techreuzen

- Zonnepanelen ter grootte van een vlo ingebed in kleding kunnen een mobiele telefoon opladen

- Argonne past machine learning toe op cyberbeveiligingsbedreigingen

- Duizenden Zwitsers protesteren tegen draadloze 5G vanwege gezondheidsproblemen

- Dubai gaat kapitaal injecteren in aan de grond gehouden Emirates Airline


 Meerderheid GOS-economieën stopt groei
Meerderheid GOS-economieën stopt groei- Facebook zegt dat videoshows 720 miljoen kijkers bereiken
- Uit eten gaan was een zeer sociale aangelegenheid voor de vroege mens
- Warmteverlies van de aarde zorgt ervoor dat de ijskap naar de zee schuift
- Enzyme Model Science Projects
- Een 3D-plantencel maken met huishoudelijke materialen
- Energy Dept. biedt $ 2 miljard lening aan La. koolstofopslagproject
- Nieuwe opmars kan soldaten helpen, atleten, anderen herstellen van traumatisch hersenletsel
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
