Wetenschap
Verduidelijken hoe kunstmatige-intelligentiesystemen keuzes maken
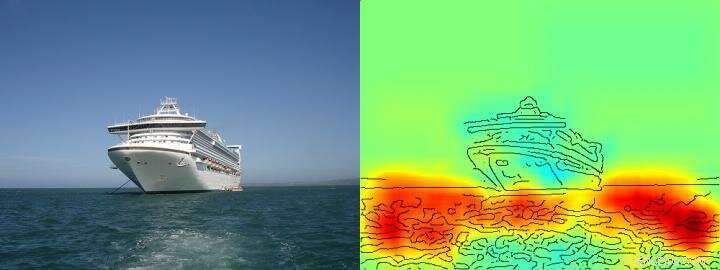
De heatmap laat heel duidelijk zien dat het algoritme zijn schip/niet-schipbeslissing neemt op basis van pixels die water voorstellen en niet op basis van pixels die het schip vertegenwoordigen. Credit: Natuurcommunicatie , CC BY Lizenz
Artificiële intelligentie (AI) en machine learning-architecturen zoals deep learning zijn een integraal onderdeel geworden van ons dagelijks leven - ze maken digitale spraakassistenten of vertaaldiensten mogelijk, medische diagnostiek verbeteren en een onmisbaar onderdeel vormen van toekomstige technologieën zoals autonoom rijden. Gebaseerd op een steeds toenemende hoeveelheid gegevens en krachtige nieuwe computerarchitecturen, leeralgoritmen lijken de menselijke capaciteiten te benaderen, soms zelfs overtreffen. Tot dusver, echter, het blijft vaak onbekend voor gebruikers hoe AI-systemen precies tot hun conclusies komen. Daarom, het kan vaak onduidelijk blijven of het besluitvormingsgedrag van de AI echt intelligent is of dat de procedures slechts gemiddeld succesvol zijn.
Onderzoekers van de TU Berlijn, Fraunhofer Heinrich Hertz Institute HHI en Singapore University of Technology and Design (SUTD) hebben deze vraag aangepakt en hebben een kijkje gegeven in het diverse "intelligentie" -spectrum dat wordt waargenomen in huidige AI-systemen, specifiek deze AI-systemen analyseren met een nieuwe technologie die geautomatiseerde analyse en kwantificering mogelijk maakt.
De belangrijkste voorwaarde voor deze nieuwe technologie is een methode die eerder is ontwikkeld door de TU Berlijn en Fraunhofer HHI, het zogenaamde Layer-wise Relevance Propagation (LRP) algoritme dat visualiseert op basis van welke inputvariabelen AI-systemen hun beslissingen nemen. LRP verlengen, de nieuwe Spectrale relevantieanalyse (SpRAy) kan een breed spectrum van aangeleerd beslissingsgedrag identificeren en kwantificeren. Op deze manier is het nu mogelijk geworden om zelfs in zeer grote datasets ongewenste besluitvorming te detecteren.
Deze zogenaamde 'verklaarbare AI' is een van de belangrijkste stappen geweest naar een praktische toepassing van AI, volgens Dr. Klaus-Robert Müller, professor voor machine learning aan de TU Berlijn. "Met name in medische diagnose of in veiligheidskritieke systemen, er mogen geen AI-systemen worden gebruikt die schilferige of zelfs vals spelende probleemoplossende strategieën gebruiken."
Door gebruik te maken van hun nieuw ontwikkelde algoritmen, onderzoekers zijn eindelijk in staat om elk bestaand AI-systeem op de proef te stellen en er ook kwantitatieve informatie over af te leiden:een heel spectrum beginnend bij naïef probleemoplossend gedrag, van fraudestrategieën tot zeer uitgebreide "intelligente" strategische oplossingen wordt waargenomen.
Dr. Wojciech Samek, groepsleider bij Fraunhofer HHI zei:"We waren zeer verrast door het brede scala aan geleerde probleemoplossende strategieën. Zelfs moderne AI-systemen hebben niet altijd een oplossing gevonden die vanuit menselijk perspectief zinvol lijkt, maar gebruikte soms zogenaamde Clever Hans Strategies."
Slimme Hans was een paard dat zogenaamd kon tellen en werd in de jaren 1900 als een wetenschappelijke sensatie beschouwd. Zoals later werd ontdekt, Hans beheerste wiskunde niet, maar in ongeveer 90 procent van de gevallen hij was in staat om het juiste antwoord af te leiden uit de reactie van de vraagsteller.
Het team rond Klaus-Robert Müller en Wojciech Samek ontdekte ook vergelijkbare "Clever Hans"-strategieën in verschillende AI-systemen. Bijvoorbeeld, een AI-systeem dat enkele jaren geleden verschillende internationale competities voor beeldclassificatie won, volgde een strategie die vanuit menselijk oogpunt als naïef kan worden beschouwd. Het classificeerde afbeeldingen voornamelijk op basis van context. Beelden werden toegewezen aan de categorie "schip" toen er veel water in beeld was. Andere afbeeldingen werden geclassificeerd als "trein" als er rails aanwezig waren. Weer andere foto's kregen de juiste categorie toegewezen door hun copyright-watermerk. De echte taak, namelijk om de concepten van schepen of treinen te detecteren, werd daarom niet opgelost door dit AI-systeem, zelfs als het inderdaad de meeste afbeeldingen correct classificeerde.
De onderzoekers waren ook in staat om dit soort foutieve probleemoplossende strategieën te vinden in enkele van de ultramoderne AI-algoritmen, de zogenaamde diepe neurale netwerken - algoritmen die als immuun werden beschouwd tegen dergelijke fouten. Deze netwerken baseerden hun classificatiebeslissingen deels op artefacten die werden gecreëerd tijdens de voorbereiding van de afbeeldingen en hebben niets te maken met de daadwerkelijke beeldinhoud.
"Dergelijke AI-systemen zijn in de praktijk niet bruikbaar. Het gebruik ervan in medische diagnostiek of op veiligheidskritieke gebieden zou zelfs enorme gevaren met zich meebrengen, ", aldus Klaus-Robert Müller. "Het is goed denkbaar dat ongeveer de helft van de AI-systemen die momenteel in gebruik zijn, impliciet of expliciet vertrouwt op dergelijke slimme Hans-strategieën. Het is tijd om dat systematisch te controleren, zodat er veilige AI-systemen kunnen worden ontwikkeld."
Met hun nieuwe technologie, de onderzoekers identificeerden ook AI-systemen die onverwacht "slimme" strategieën hebben geleerd. Voorbeelden zijn systemen die de Atari-spellen Breakout en Pinball hebben leren spelen. "Hier, de AI begreep het concept van het spel duidelijk, en een intelligente manier gevonden om op een gerichte en risicoarme manier veel punten te verzamelen. Het systeem grijpt soms zelfs in op manieren die een echte speler niet zou doen, ' zei Wojciech Samek.
"Meer dan het begrijpen van AI-strategieën, ons werk stelt de bruikbaarheid vast van verklaarbare AI voor iteratief datasetontwerp, namelijk voor het verwijderen van artefacten in een dataset waardoor een AI gebrekkige strategieën zou leren, en helpen om te beslissen welke niet-gelabelde voorbeelden moeten worden geannoteerd en toegevoegd zodat storingen van een AI-systeem kunnen worden verminderd, " zei SUTD-assistent-professor Alexander Binder.
"Onze geautomatiseerde technologie is open source en beschikbaar voor alle wetenschappers. We zien ons werk als een belangrijke eerste stap om AI-systemen robuuster te maken, verklaarbaar en veilig in de toekomst, en er zullen er nog meer moeten volgen. Dit is een essentiële voorwaarde voor algemeen gebruik van AI, zei Klaus-Robert Müller.
 Gemanipuleerde microben kunnen biologisch afbreekbare kunststoffen produceren tegen lagere kosten en milieu-impact dan plantaardige kunststoffen
Gemanipuleerde microben kunnen biologisch afbreekbare kunststoffen produceren tegen lagere kosten en milieu-impact dan plantaardige kunststoffen- Het veel voorkomende gebruik van wijnsteenzuur
- Hoe vergelijk ik 4140 & 4150 staal?
- Kathodedefecten verbeteren de batterijprestaties
- Een verstevigde gebruinde huid verzachten
- Milieuvriendelijke programma's moeten rekening houden met de factoren die elk geslacht motiveren
- Hydraulisch breken heeft een negatieve invloed op de gezondheid van baby's
- Stijgend methaan kan inspanningen om catastrofale klimaatverandering te voorkomen dwarsbomen
- Algen bloeien irk Canarische strandgangers
- Brand in Spanje bij Werelderfgoed onder controle
Hoofdlijnen
- Beeldstabilisatie bij gewervelde dieren hangt af van contrast tussen objecten
- Welke drie omstandigheden zijn ideaal voor bacteriën om te groeien?
- Het belang van DNA-moleculen
- Studie onthult hoe de adelborst zijn paar uur lang in stand houdt
- Vijf soorten aseksuele reproductie
- Celsignalen die wondgenezing in gang zetten zijn verrassend complex
- Menselijke evolutie: tijdlijn, stadia, theorieën en bewijsmateriaal
- De rol van ribosomen in Homeostasis
- Hoe een onbekende bacterie in de microbiologie te identificeren
- Online technologie verandert de dynamiek van het geven van geschenken

- Franse autofabrikant PSA versnelt verkoop bij overname Opel

- Beweeg over Tupac! Levensgrote hologrammen die videoconferenties revolutionair gaan veranderen

- Air France zegt de capaciteit de komende twee maanden tussen 70 en 90% te verminderen

- Hoe bouw je een slimme stad:innovatiediplomatie, transparantie, vertrouwen en... conflict?


 Tweens en TV:UCLA's 50-jarig onderzoek onthult de waarden die kinderen leren van populaire shows
Tweens en TV:UCLA's 50-jarig onderzoek onthult de waarden die kinderen leren van populaire shows- Meer dan de helft van de rivieren ter wereld stopt gemiddeld minstens één dag per jaar met stromen
- Lijst met dieren die te zien zijn in zwart-wit
- 10 niet-geïdentificeerde geluiden waar wetenschappers serieus naar kijken
- Antarctica:de oceaan koelt af aan de oppervlakte, maar warmt op op diepte
- Camera legt innovatieve inzet van sleepzeilen in de ruimte vast
- Amerikaanse politieke partijen meer gepolariseerd dan kiezers
- US West bereidt zich voor op mogelijke eerste verklaring van watertekort
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
