Wetenschap
Een nieuwe benadering om het vergeten van meerdere modellen in diepe neurale netwerken te voorkomen
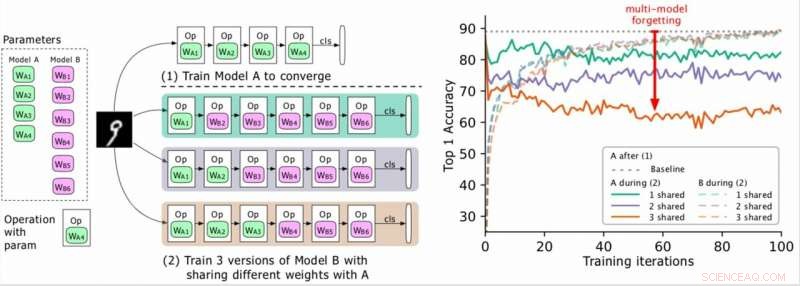
(Links) Twee te trainen modellen (A, B), waarbij de parameters van A groen zijn en die van B paars, en B deelt enkele parameters met A (groen aangegeven tijdens fase 2). De onderzoekers trainen A eerst naar convergentie en trainen vervolgens B. (Rechts) Nauwkeurigheid van model A naarmate de training van B vordert. De verschillende kleuren komen overeen met verschillende aantallen gedeelde lagen. De nauwkeurigheid van A neemt drastisch af, vooral wanneer er meer lagen worden gedeeld, en de onderzoekers noemen de druppel (de rode pijl) het vergeten van meerdere modellen. Krediet:Benyahia, Yu et al.
In recente jaren, onderzoekers hebben diepe neurale netwerken ontwikkeld die verschillende taken kunnen uitvoeren, inclusief visuele herkenning en natuurlijke taalverwerking (NLP) taken. Hoewel veel van deze modellen opmerkelijke resultaten behaalden, ze presteren meestal alleen goed op één bepaalde taak vanwege wat wordt aangeduid als 'catastrofaal vergeten'.
Eigenlijk, catastrofaal vergeten betekent dat wanneer een model dat aanvankelijk is getraind op taak A, later wordt getraind op taak B, zijn prestaties op taak A zullen aanzienlijk afnemen. In een paper dat vooraf is gepubliceerd op arXiv, onderzoekers van Swisscom en EPFL identificeerden een nieuw soort vergeten en stelden een nieuwe benadering voor die zou kunnen helpen om dit te overwinnen via een statistisch verantwoord gewichtsplasticiteitsverlies.
"Toen we voor het eerst aan ons project begonnen te werken, het automatisch ontwerpen van neurale architecturen was rekenkundig duur en onhaalbaar voor de meeste bedrijven, " Yassine Benyahia en Kaicheng Yu, de hoofdonderzoekers van het onderzoek, vertelde TechXplore via e-mail. "Het oorspronkelijke doel van onze studie was om nieuwe methoden te identificeren om deze kosten te verminderen. Toen het project begon, een paper van Google beweerde de tijd en middelen die nodig zijn om neurale architecturen te bouwen drastisch te hebben verminderd met behulp van een nieuwe methode die weight-sharing wordt genoemd. Dit maakte autoML haalbaar voor onderzoekers zonder enorme GPU-clusters, moedigt ons aan om dit onderwerp dieper te bestuderen."
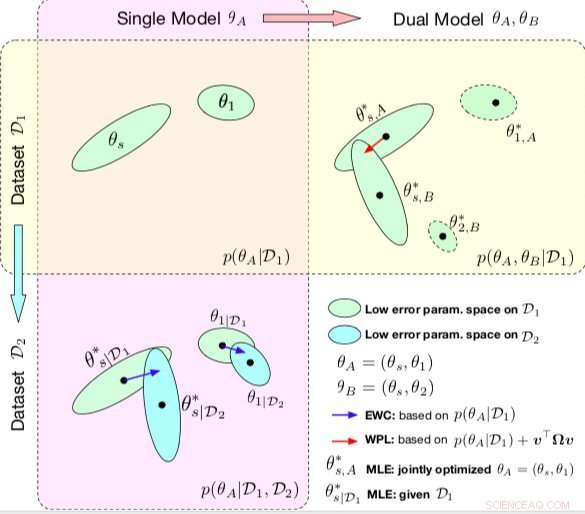
Vergelijking tussen EOR en WPL. De ellipsen in elk subplot vertegenwoordigen parametergebieden die overeenkomen met een lage fout. (Linksboven) Beide methoden beginnen met een enkel model, met parameters θA ={θs, θ1}, getraind op een enkele dataset D1. (Linksonder) EWC regulariseert alle parameters op basis van p(θA|D1) om hetzelfde initiële model te trainen op een nieuwe dataset D2. (Rechtsboven) Daarentegen WPL maakt gebruik van de initiële dataset D1 en regulariseert alleen de gedeelde parameters θs op basis van zowel p(θA|D1) als v>Ωv, terwijl de parameters θ2 vrij kunnen bewegen. Krediet:Benyahia, Yu et al.
Tijdens hun onderzoek naar op neurale netwerken gebaseerde modellen, Benjaja, Yu en hun collega's merkten een probleem op met het delen van gewicht. Toen ze twee modellen (bijvoorbeeld A en B) achter elkaar trainden, de prestaties van model A daalden, terwijl de prestaties van model B verbeterden, of vice versa. Ze toonden aan dat dit fenomeen, die ze 'het vergeten van meerdere modellen' noemden, " kan de prestaties van verschillende auto-mL-benaderingen belemmeren, inclusief Google's efficiënte neurale architectuurzoekopdracht (ENAS).
"We realiseerden ons dat het delen van gewicht ervoor zorgde dat modellen elkaar negatief beïnvloedden, waardoor het architectuurzoekproces dichter bij willekeurig kwam, " Benyahia en Yu legden uit. "We hadden ook onze bedenkingen bij het zoeken naar architectuur, waar alleen de definitieve resultaten aan het licht komen en waar er geen goed kader is om de kwaliteit van de architectuurzoektocht op een eerlijke manier te beoordelen. Onze aanpak kan helpen om dit vergeetprobleem op te lossen, omdat het gerelateerd is aan een kernmethode waar bijna alle recente autoML-papers op vertrouwen, en we beschouwen een dergelijke impact als enorm voor de gemeenschap."
In hun studie hebben de onderzoekers modelleerden multi-model vergeten wiskundig en leidden een nieuw verlies af, gewichtsplasticiteitsverlies genoemd. Dit verlies zou het vergeten van meerdere modellen aanzienlijk kunnen verminderen door het leren van de gedeelde parameters van een model te regulariseren op basis van hun belang voor eerdere modellen.
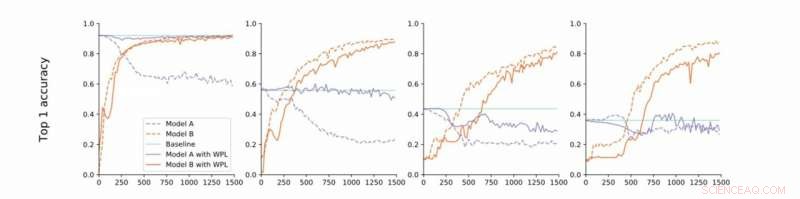
Van strikte naar losse convergentie. De onderzoekers voeren experimenten uit op MNIST met modellen A en B met gedeelde parameters en rapporteren de nauwkeurigheid van Model A voordat ze Model B trainen (baseline, groen) en de nauwkeurigheid van Model A en B tijdens het trainen van Model B met (oranje) of zonder (blauw) WPL. In (a) tonen ze de resultaten voor strikte convergentie:A wordt aanvankelijk getraind tot convergentie. Vervolgens versoepelen ze deze aanname en trainen A tot ongeveer 55% (b), 43% (c), en 38% (d) van zijn optimale nauwkeurigheid. WPL is zeer effectief wanneer A is getraind tot ten minste 40% van de optimaliteit; onderstaand, de Fisher-informatie wordt te onnauwkeurig om betrouwbare belangrijkheidsgewichten te geven. Zo helpt WPL het vergeten van meerdere modellen te verminderen, ook als de gewichten niet optimaal zijn. WPL verminderde vergeten tot 99,99% voor (a) en (b), en tot 2% voor (c). Krediet:Benyahia, Yu et al.
"In principe, door de over-parametrering van neurale netwerken, ons verlies verlaagt eerst parameters die 'minder belangrijk' zijn voor het uiteindelijke verlies, en houdt de belangrijkste ongewijzigd, " zeiden Benyahia en Yu. "De prestaties van Model A zijn dus onaangetast, terwijl de prestaties van model B blijven toenemen. Op kleine datasets, ons model kan vergeten tot 99 procent verminderen, en op autoML-methoden, tot 80 procent in het midden van de training."
In een reeks testen, de onderzoekers demonstreerden de effectiviteit van hun aanpak voor het verminderen van het vergeten van meerdere modellen, zowel in gevallen waarin twee modellen opeenvolgend worden getraind als voor het zoeken naar neurale architectuur. Hun bevindingen suggereren dat het toevoegen van gewichtsplasticiteit bij het zoeken naar neurale architectuur de prestaties van meerdere modellen op zowel NLP- als computervisietaken aanzienlijk kan verbeteren.
De studie uitgevoerd door Benyahia, Yu en hun collega's werpen licht op de kwestie van catastrofaal vergeten, in het bijzonder dat wat gebeurt wanneer meerdere modellen opeenvolgend worden getraind. Na het wiskundig modelleren van dit probleem, de onderzoekers introduceerden een oplossing die het kon overwinnen, of in ieder geval de impact ervan drastisch verminderen.
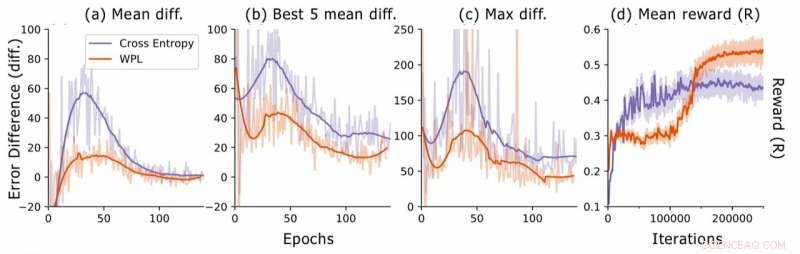
Foutverschil tijdens het zoeken naar neurale architectuur. Voor elke architectuur de onderzoekers berekenen de RNN-foutverschillen err2−err1, waarbij err1 de fout is direct na het trainen van deze architectuur en err2 degene nadat alle architecturen zijn getraind in het huidige tijdperk. Ze plotten (a) het gemiddelde verschil over alle bemonsterde modellen, (b) het gemiddelde verschil over de 5 modellen met de laagste fout1, en (c) het maximale verschil over alle modellen. In (d), ze plotten de gemiddelde beloning van de gesamplede architecturen als een functie van trainingsiteraties. Hoewel WPL in eerste instantie leidt tot lagere beloningen, vanwege een groot gewicht α in vergelijking (8), door het later vergeten te verminderen, kan de controller betere architecturen samplen, zoals blijkt uit de hogere beloning in de tweede helft. Krediet:Benyahia, Yu et al.
"Bij het vergeten van meerdere modellen, ons leidende principe was om te denken in formules en niet alleen door simpele intuïtie of heuristieken, " zeiden Benyahia en Yu. "We zijn er sterk van overtuigd dat dit 'denken in formules' onderzoekers tot grote ontdekkingen kan leiden. Daarom voor verder onderzoek we willen deze benadering toepassen op andere gebieden van machine learning. In aanvulling, we zijn van plan ons verlies aan te passen aan recente ultramoderne autoML-methoden om de effectiviteit ervan aan te tonen bij het oplossen van het door ons waargenomen probleem van gewichtsverdeling."
© 2019 Wetenschap X Netwerk

Hoofdlijnen
- High School Biology Topics
- Wat zijn de kleine delen van het DNA die Code for a Trait?
- Het verschil tussen de genoom-DNA-extractie tussen dieren en planten
- Hoop op een van 's werelds zeldzaamste primaten:eerste telling van Zanzibar Red Colobus-aap
- BigH1 - de belangrijkste histon voor mannelijke vruchtbaarheid
- Sorry,
- Luie mieren maken zichzelf op onverwachte manieren nuttig
- Interessante feiten over DNA-vingerafdrukken
- Bevindingen sonde cel samenwerking, massale migratie
- Robotachtige architectuur geïnspireerd op pelikaanpaling:Origami-ontvouwings- en huidrekmechanismen

- Hoe digitale media de grens tussen Australië en China doen vervagen

- Via de FUBI-methode, kinderen nemen deel aan het ontwerpen van interactieve ervaringen over het hele lichaam
- Berekening van transformatorbelasting

- Tunnelvisie voor bestelwagens kan vervuiling verminderen


 Met suiker omhulde nanowormen niet als ontbijt in het menselijke immuunsysteem
Met suiker omhulde nanowormen niet als ontbijt in het menselijke immuunsysteem- Skeletensysteem van een koe
- Studie:zou donkere materie zich kunnen verbergen in bestaande gegevens?
- NASA wijt het monsterfiasco van Mars rover aan slecht, poederachtige rots
- Computerprogramma detecteert verschillen tussen menselijke cellen
- Een type semi-transparant polymeer dat bij kamertemperatuur kan worden hersteld met een kleine druk
- Luchtvervuiling veroorzaakt meer bezoeken aan spoedeisende hulp voor hart- en longaandoeningen
- Extinction Rebellion:terreurdreiging is een wake-up call voor hoe de staat omgaat met milieuactivisme
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Portuguese | Swedish | German | Dutch | Danish | Norway | Italian | Spanish |

-
Wetenschap © https://nl.scienceaq.com
