Wetenschap
Onderzoekers ontwikkelen een dynamisch tekenherkenningssysteem voor toetsenborden
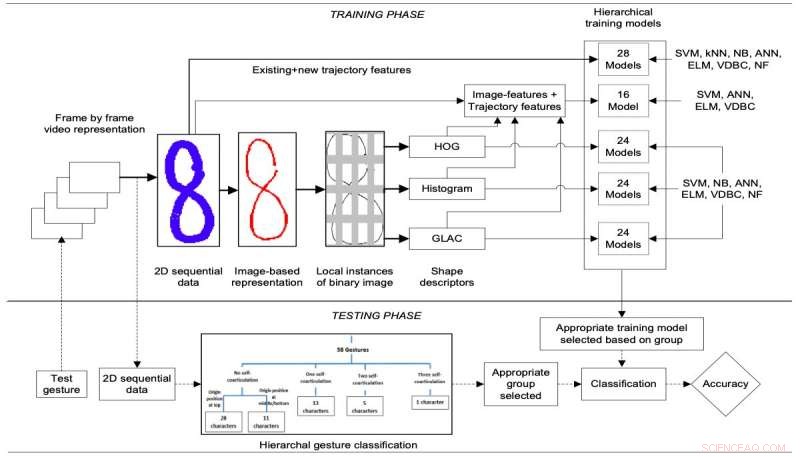
Blokweergave van de trainings- (harde en stippellijnen) en testfase (stippellijnen) van het voorgestelde systeem. Credit:S. Misra &R.H. Laskar.
Onderzoekers van NIT Silchar, Indië, hebben onlangs een nieuw dynamisch, op handgebaren gebaseerd herkenningssysteem voor toetsenbordtekens ontwikkeld. Dit virtuele toetsenbordsysteem, gepresenteerd in een paper gepubliceerd in Springer's Journal of Ambient Intelligence and Humanized Computing , maakt gebruik van een op afbeeldingen gebaseerde benadering voor gebarenherkenning die patroon is, snelheid en schaal invariant van aard.
"Gebaarherkenning is een veelbelovend vakgebied vanwege het enorme scala aan toepassingen, "Songita Misra, een van de onderzoekers die het onderzoek heeft uitgevoerd, vertelde TechXplore. "Een gebarenherkenningssysteem kan worden toegepast in virtual reality-systemen, augmented reality, gezondheidszorg, voertuigen, om patiënten met gezichts- of bewegingsstoornissen te helpen, voor huishoudelijke apparaten, robots, mijnbouw en verschillende andere toepassingen, die met elke dag die voorbijgaat toenemen."
Gebaarherkenning kan de interactie tussen mens en computer op verschillende gebieden verbeteren. Hoewel hulpmiddelen voor gebarenherkenning een breed scala aan toepassingen kunnen hebben, tot dusver, zeer weinig organisaties en instellingen hebben geprobeerd deze systemen in de samenleving te introduceren.
"Tijdens het literatuuronderzoek Ik merkte op dat de meeste bestaande onderzoeken ofwel beperkt zijn tot statische gebaren of dynamische gebaren van korte duur, zoals 'beweeg naar links, ' 'ga naar rechts, ' 'Klik, ' 'stop, ' enzovoort., die in principe de traditionele muis- en tv-afstandsbedieningen kan vervangen, " zei Songhita. "Met de toename van de vraag naar applicaties, de complexiteit van het systeem vanaf de kant van de ontwerper zal ongetwijfeld toenemen. Daarom, een grondige studie en analyse op het gebied van lange dynamische systemen is vereist."
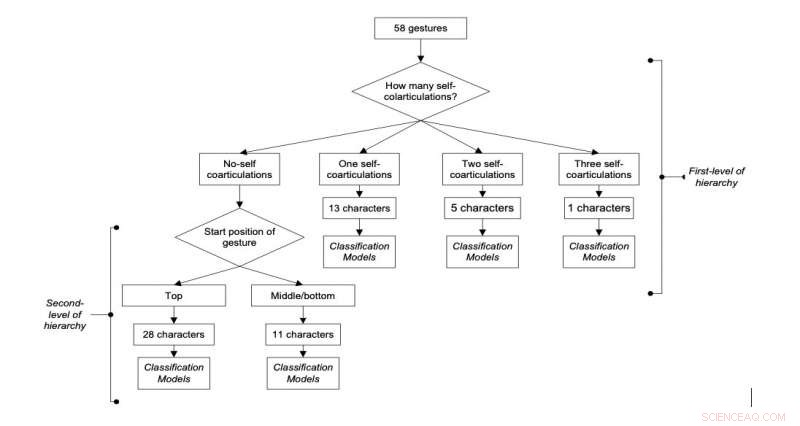
Stroomschema van het voorgestelde hiërarchische classificatiemodel. Credit:S. Misra &R.H. Laskar.
Traditionele toetsenborden ondersteunen een breed scala aan tekens, inclusief hoofdletters en kleine Engelse letters, rekenkundige operatoren, Arabische cijfers, en andere afdrukbare ASCII-tekens. Een systeem voor gebarenherkenning dat al deze karakters omvat, is een grote uitdaging om te ontwikkelen vanwege de aanzienlijke databasevereisten, evenals mogelijke complicaties in verband met handdetectie, volgen, extractie van kenmerken en het gebruik van classificaties.
In hun recente studie, Songhita en haar collega's wilden een virtueel keyboardsysteem ontwikkelen met ongeveer 95 karakters. Nog, vanwege de moeilijkheden die met deze taak gepaard gaan, hun systeem ondersteunt momenteel 58.
"Ons team, waaronder mijn gids Dr. Rabul Hussain Laskar, Dr. Joyeeta singha en ik, erin geslaagd om een 58 bedrukbaar toetsenbordkaraktersysteem te ontwikkelen met zowel kleurmarkeringen als blote hand, " legde Songhita uit. "Ons onderzoek op dit gebied begon in 2013 in ons Speech and Image-lab bij NIT Silchar."
De onderzoekers ontwikkelden een hiërarchische benadering van gebarenherkenning die gebaseerd is op zelf-co-articulatie, positie- en trajectkenmerken. Bestaande state-of-the-art modellen voor gebarenherkenning zijn gebaseerd op temporele trajectkenmerken, die afhankelijk zijn van het framegewijze 2-D sequentiële pad dat wordt gevolgd door bepaalde gebaren.

De 58 toetsenbordkarakters geclassificeerd in de studie. Credit:S. Misra &R.H. Laskar.
Door deze afhankelijkheid de kenmerken die door deze benaderingen worden geanalyseerd, kunnen worden beïnvloed door baanruis of andere patroonvariaties, snelheid of schaal. De aanpak van Songhita en haar collega's, anderzijds, gebruikt beeldmodellen die niet framegewijs worden verkregen, en worden dus niet beïnvloed door patroon, snelheid, schaal- of trajectvariaties.
De onderzoekers hebben deze beeldgebaseerde en trajectkenmerken samengevoegd in een hybride hiërarchisch classificatiemodel. Hun model bereikte een 3,9 procent grotere nauwkeurigheid dan een baseline niet-hiërarchisch trajectclassificatiemodel, met lagere misclassificatiepercentages voor tekens zoals '0' en 'O' of 'Z' en '2'.
"De uitgebreide versie van ons werk is goedgekeurd door IMPRINT-II voor sponsoring onder SERB, zomertijd, Indië, voor een duur van drie jaar, " zei Songhita. "Ons project, die in samenwerking is met IIT Guwahati, behoorde tot de 121 projecten die werden geselecteerd uit meer dan 2000 voorstellen. Dit is een grote prestatie voor ons, ook voor het instituut. Het onze zal zeker een van de eerste projecten in India zijn die zich uitsluitend richten op de ontwikkeling van een virtueel tekstinvoerinterfacesysteem."
De recente studie van Songhita en haar collega's was gericht op het ontwikkelen van een hiërarchisch classificatiemodel dat grote databases aankan zonder de nauwkeurigheid van het systeem te verminderen. Het doel van het bredere project goedgekeurd door IMPRINT-II, echter, zal een gehandicaptenvriendelijk gebarenherkenningssysteem ontwikkelen voor 95 afdrukbare toetsenbordtekens met behulp van zowel kleurmarkeringen als detectie met blote handen. Zodra dit systeem is voltooid, het zal worden ingezet voor gebruik door oudere en slechtziende gebruikers, evenals anderen die er baat bij kunnen hebben.
"De ontwikkeling van zo'n groot vocabulairesysteem zal een uitdagende taak zijn, " zei Songhita. "Tot nu toe, we hebben een herkenningssysteem van 58 tekens ontwikkeld met behulp van op visie gebaseerde technieken."
© 2019 Wetenschap X Netwerk
 Wetenschappers synthetiseren een nieuwe stof met antitumorale eigenschappen
Wetenschappers synthetiseren een nieuwe stof met antitumorale eigenschappen- Wetenschappers vinden sneller uit, goedkopere strategie voor het ontwerpen van infrarood-emitterende materialen
- Een nieuw elektrolytontwerp dat de prestaties van Li-ionbatterijen zou kunnen verbeteren
- Zijn antivitamines de nieuwe antibiotica?
- Nieuwe structurele eenheid vereenvoudigt het proces van het op maat ontwerpen van eiwitten
- Hoe veranderen drones de landbouw?
- Opwarming van de aarde vergroot potentiële schade door natuurbranden in mediterraan Europa
- Expeditie naar Peru legt klimaatgeschiedenis vast in ijs - voordat het weg is
- Uitbarstingsaanwijzingen:onderzoekers maken een momentopname van vulkaanleidingen
- Koralen helpen omgaan met druk
Hoofdlijnen
- Diversiteit van grote dieren speelt een belangrijke rol in koolstofcyclus
- Prokaryotische celstructuur
- Uitvindingen in 1947
- Wat een grote handtekening kan zeggen over je persoonlijkheid
- Wat is de rol van het IgM-antilichaam?
- Hoe het Human Microbiome-project werkt
- De levenscyclus van Gymnosperms
- Teams Advance maakt het bewerken van genen met chirurgische precisie mogelijk
- Het verschil tussen histon en nonhistone
- AMD-processors die kwetsbaar zijn voor beveiligingsproblemen, datalekken

- Moet u zich zorgen maken over Boeing 737's? Alleen als u een luchtvaartmaatschappij runt

- Zal de overstap naar de commerciële cloud sommige datagebruikers achterlaten?

- Google waarschuwt u wanneer uw wachtwoorden te eenvoudig te raden zijn en te vaak worden gebruikt

- De hybride val


 Compost gebruiken om bossen in Madagaskar te behouden
Compost gebruiken om bossen in Madagaskar te behouden- Hoe elektrische elektrische energie te berekenen
- Internationaal rapport bevestigt dat 2017 een van de drie warmste jaren ooit was
- Scheiding een zoet succes
- Maan rijker aan water dan ooit gedacht
- Federaal werkloosheidsgeld tijdens pandemie verhoogde uitgaven voor gezondheidszorg
- Stadia van de Mongo Seed
- Facebook stopt met uitgaven tegen privacy-inspanningen in Californië
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Portuguese | Swedish | German | Dutch | Danish | Norway | Spanish |

-
Wetenschap © https://nl.scienceaq.com
