Wetenschap
Machine learning gebruiken om onbetrouwbare Facebook-pagina's te detecteren
Distributie van top-10-functies. Krediet:Panida Songram.
Een groeiend aantal bedrijven en individuen wereldwijd maakt Facebook-pagina's voor marketing- en reclamedoeleinden. Facebook biedt namelijk de mogelijkheid om gratis te communiceren met potentiële of bestaande klanten, reclame voor nieuwe producten, aanbiedingen of diensten.
Nog, juist omdat deze dienst gratis en gemakkelijk toegankelijk is, kwaadwillende gebruikers gebruiken het om misleidende pagina's te maken. Het detecteren en identificeren van onbetrouwbare pagina's is van cruciaal belang, omdat het kan helpen om gebruikers te waarschuwen en kwaadaardige activiteiten op het platform te verminderen.
Wereldwijd hebben onderzoekers daarom geprobeerd methoden te ontwikkelen om misleiding op Facebook en andere sociale-mediaplatforms te detecteren en te voorkomen. Panida Songram, een onderzoeker aan de Mahasarakham University, in Thailand, heeft onlangs een onderzoek uitgevoerd naar het gebruik van gesuperviseerde machine learning om de betrouwbaarheid of onbetrouwbaarheid van Facebook-pagina's te detecteren.
"Dit artikel is bedoeld om de kenmerken van onbetrouwbare en betrouwbare Facebook-pagina's op te sporen en te onderzoeken, " Songram schreef in haar krant, die werd gepubliceerd in Springer's Artificial Life and Robotics tijdschrift. "Effectieve machine learning-modellen en functieselectiemethoden worden ook onderzocht voor het detecteren van onbetrouwbare en betrouwbare pagina's."
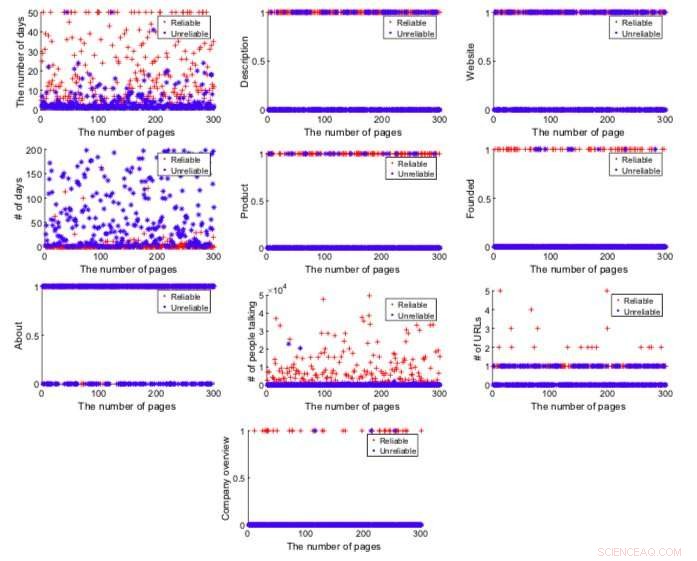
Songram heeft een groot aantal functies geëxtraheerd die kunnen helpen bepalen of een pagina betrouwbaar is of niet, inclusief paginadetails, informatie over een product of dienst, gebruikersreacties en postgedrag van de paginabeheerder. Vervolgens trainde ze een machine learning-tool onder toezicht om deze functies te analyseren en pagina's als betrouwbaar of onbetrouwbaar te classificeren.
"Eerst, Facebook-pagina's worden willekeurig verzameld en vervolgens gelabeld door vijf gebruikers, Songram legt uit in haar paper. "Facebook-pagina's met instemming van vijf gebruikers worden geselecteerd en hun informatie wordt opgehaald met behulp van de Facebook Graph API. Volgende, kenmerken worden uit de informatie gehaald en in de experimenten onderzocht."
Songram evalueerde de effectiviteit van verschillende classificaties bij het detecteren van onbetrouwbare en betrouwbare pagina's. Ze ontdekte dat KNN de beste classificeerder was, met een nauwkeurigheid van 88,67 procent. Ze voerde ook een analyse uit van de functies van de Facebook-pagina, om beter te begrijpen wat kenmerkend is voor betrouwbare of onbetrouwbare pagina's.
"Voor onbetrouwbare pagina's, het aantal dagen tussen de datum van de laatste post en de ophaaldatum is hoog en het aantal berichten per week (postfrequentie) is erg klein, Songram schreef in haar paper. "Het geeft aan dat onbetrouwbare pagina's niet actief zijn, terwijl betrouwbare pagina's actief zijn."
Songram merkte op dat het aantal mensen dat online onbetrouwbare pagina's bespreekt aanzienlijk kleiner is dan degenen die het hebben over betrouwbare pagina's. Een mogelijke verklaring hiervoor is dat gebruikers zich vaak realiseren dat de pagina's onbetrouwbaar zijn en er daarom online niet over praten. Berichten op betrouwbare pagina's bevatten ook veel meer URL's dan die op onbetrouwbare pagina's, evenals meer informatie over het bedrijf en zijn producten/diensten.
Met behulp van wat zij vond dat de top 10 functies waren om de betrouwbaarheid van een Facebook-pagina te bepalen, Songram behaalde een classificatienauwkeurigheid van 91,37 procent. In de toekomst, haar bevindingen zouden kunnen helpen bij de ontwikkeling van effectievere tools om snel onbetrouwbare Facebook-pagina's te detecteren.
© 2018 Wetenschap X Netwerk
 Nieuw onderzoek toont de beperkingen van coördinatie in de chemie aan
Nieuw onderzoek toont de beperkingen van coördinatie in de chemie aan- Hoe te converteren van molariteit naar molaliteit
- Nieuwe strategie ter bevordering van hergebruik van met koolstofvezel versterkte kunststoffen
- Hoe PH in Water te verminderen
- Neutronen onthullen verborgen geheimen van het hepatitis C-virus
- Nieuwe studie kijkt naar handel in stikstofkredieten om de groei van oeverbuffers te stimuleren
- Nieuwe tool voor het beoordelen van de voordelen, risico's en duurzaamheid van de visconsumptie
- Visdoden en ondrinkbaar water:dit is wat je deze zomer kunt verwachten voor de Murray Darling
- Zuurstof volgen in de Sargasso Seas 18 graden water
- Het reguleren van de indirecte CO2-emissies door landgebruik door biobrandstoffen brengt hoge verborgen kosten met zich mee voor de brandstofverbruikers
Hoofdlijnen
- Hoe SARS werkt
- Dit wetenschappelijke experiment duurt 500 jaar
- Informatie over bloedvaten
- Plantenziekte bestrijden bij warme temperaturen houdt voedsel op tafel
- Wat gebruiken chloroplasten om glucose te maken?
- Wetenschappers onderzoeken hoe verschillende huizen en levensstijlen van invloed zijn op welke insecten bij ons leven
- Wat zijn de voordelen en nadelen van Flow Cytometry?
- Waar bevindt het DNA zich in een cel?
- Duurzaamheid van visserij gekoppeld aan genderrollen onder handelaren
- SwarmTouch:een tactiele interactiestrategie voor communicatie tussen mens en zwerm

- Alibaba kijkt naar $ 15 miljard Hong Kong-notering:rapport

- Nieuw-Zeeland bekritiseert Google wegens blunder in moordzaak

- Spel is over? China houdt online games in bedwang bij laatste tegenslag in de industrie

- S&P verlaagt de vooruitzichten voor de kredietwaardigheid van Boeing naar negatief


 Hoe een R-410A koelsysteem controleren en opladen
Hoe een R-410A koelsysteem controleren en opladen - Wetenschappers onderzoeken het potentieel voor verdere verbeteringen aan de voorspellingen van tropische cycloonsporen
- Wetenschappers gebruiken diamant in 's werelds eerste continue solid-state maser op kamertemperatuur
- Waarom de opkomst van populistische nationalistische leiders de wereldwijde klimaatbesprekingen herschrijft
- Afbeelding:Hubble haakt een eenarmig sterrenstelsel vast
- in opknapbeurt, Facebook zet in op kleinschalige verbindingen, romantiek
- grappige kant, harde rand - het gedrag van je baas is belangrijk, uit onderzoek blijkt
- Data Dont Lie: Ayrton Ostlys March Madness Lessons and a Look at the Sweet 16
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | German | Dutch | Danish | Norway | Portuguese | Swedish |

-
Wetenschap © https://nl.scienceaq.com
