Wetenschap
Slimmere AI:machine learning zonder negatieve gegevens
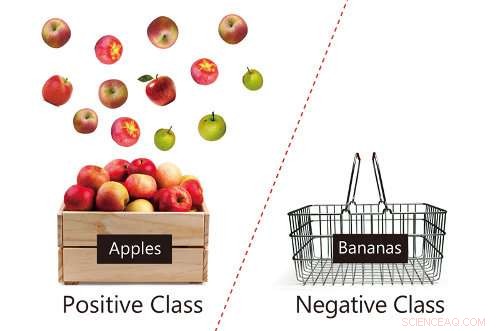
Schematische weergave van positieve gegevens (appels) en een gebrek aan negatieve gegevens (bananen), met een illustratie van het vertrouwen van de appelgegevens. Krediet:RIKEN
Een onderzoeksteam van het RIKEN Center for Advanced Intelligence Project (AIP) heeft met succes een nieuwe methode voor machine learning ontwikkeld waarmee een AI classificaties kan maken zonder zogenaamde "negatieve gegevens, " een bevinding die zou kunnen leiden tot een bredere toepassing op een verscheidenheid aan classificatietaken.
Het classificeren van dingen is van cruciaal belang voor ons dagelijks leven. Bijvoorbeeld, we moeten spammail detecteren, nep politiek nieuws, evenals meer alledaagse dingen zoals objecten of gezichten. Bij gebruik van AI, dergelijke taken zijn gebaseerd op 'classificatietechnologie' in machine learning - waarbij de computer leert met behulp van de grens tussen positieve en negatieve gegevens. Bijvoorbeeld, "positieve" gegevens zijn foto's met een blij gezicht, en "negatieve" gegevensfoto's met een droevig gezicht. Zodra een classificatiegrens is geleerd, de computer kan bepalen of bepaalde gegevens positief of negatief zijn. De moeilijkheid met deze technologie is dat er zowel positieve als negatieve gegevens nodig zijn voor het leerproces, en negatieve gegevens zijn in veel gevallen niet beschikbaar (bijvoorbeeld het is moeilijk om foto's met het label te vinden, "deze foto bevat een droevig gezicht, " aangezien de meeste mensen glimlachen voor een camera.)
Op het gebied van real-life programma's, wanneer een winkelier probeert te voorspellen wie een aankoop zal doen, het kan gemakkelijk gegevens vinden over klanten die bij hen hebben gekocht (positieve gegevens), maar het is in principe onmogelijk om gegevens te verkrijgen over klanten die niet bij hen hebben gekocht (negatieve gegevens), aangezien zij geen toegang hebben tot de gegevens van hun concurrenten. Een ander voorbeeld is een veelvoorkomende taak voor app-ontwikkelaars:ze moeten voorspellen welke gebruikers de app blijven gebruiken (positief) of stoppen (negatief). Echter, wanneer een gebruiker zich uitschrijft, de ontwikkelaars verliezen de gegevens van de gebruiker omdat ze de gegevens over die gebruiker volledig moeten verwijderen in overeenstemming met het privacybeleid om persoonlijke informatie te beschermen.
Volgens hoofdauteur Takashi Ishida van RIKEN AIP, "Vorige classificatiemethoden konden niet omgaan met de situatie waarin negatieve gegevens niet beschikbaar waren, maar we hebben het voor computers mogelijk gemaakt om te leren met alleen positieve gegevens, zolang we een betrouwbaarheidsscore hebben voor onze positieve gegevens, opgebouwd uit informatie zoals koopintentie of het actieve percentage van app-gebruikers. Met behulp van onze nieuwe methode, we kunnen computers alleen een classificatie laten leren van positieve gegevens die met vertrouwen zijn uitgerust."
Ishida stelde voor, samen met onderzoeker Gang Niu van zijn groep en teamleider Masashi Sugiyama, dat ze computers goed laten leren door de betrouwbaarheidsscore toe te voegen, die wiskundig overeenkomt met de waarschijnlijkheid of de gegevens tot een positieve klasse behoren of niet. Ze zijn erin geslaagd een methode te ontwikkelen waarmee computers alleen een classificatiegrens kunnen leren van positieve gegevens en informatie over het vertrouwen (positieve betrouwbaarheid) ervan tegen classificatieproblemen van machine learning die gegevens positief en negatief verdelen.
Om te zien hoe goed het systeem functioneerde, ze gebruikten het op een reeks foto's met verschillende labels van modeartikelen. Bijvoorbeeld, ze kozen voor "T-shirt, " als de positieve klasse en een ander item, bijv. "sandaal", als de negatieve klasse. Vervolgens voegden ze een vertrouwensscore toe aan de "T-shirt" -foto's. Ze ontdekten dat zonder toegang tot de negatieve gegevens (bijv. "sandalen" foto's), in sommige gevallen, hun methode was net zo goed als een methode waarbij positieve en negatieve gegevens worden gebruikt.
Volgens Ishida, "Deze ontdekking zou het scala aan toepassingen kunnen uitbreiden waar classificatietechnologie kan worden gebruikt. Zelfs op gebieden waar machine learning actief is gebruikt, onze classificatietechnologie kan worden gebruikt in nieuwe situaties waar alleen positieve gegevens kunnen worden verzameld vanwege gegevensregulering of zakelijke beperkingen. In de nabije toekomst, we hopen onze technologie in te zetten in verschillende onderzoeksgebieden, zoals natuurlijke taalverwerking, computer visie, robotica, en bio-informatica."
 Voorloper van hernieuwbare plastic zou de cellulose-biobrandstofindustrie kunnen laten groeien
Voorloper van hernieuwbare plastic zou de cellulose-biobrandstofindustrie kunnen laten groeien- Nieuwe katalysator kan betere lithium-zwavelbatterijen mogelijk maken, voeding van de volgende generatie elektronica
- Nanoglue kan composieten meerdere malen sterker maken tijdens dynamische belasting
- Nieuw katalysatorcomposiet vermindert het gebruik van zeldzame aardelementen
- Wat zijn twee soorten verdamping?
- NASA volgt tropische storm Talim in Filippijnse Zee
- Arctische zee-ijsdips worden laag voor de winter (update)
- Vulkaanbibliotheken kunnen helpen bij het plannen van toekomstige vulkanische crises
- Beheersing van antropogene emissies kan de waterkwaliteit in kustzeeën verbeteren
- Waarom de wereld zich zorgen moet maken over de toekomst van de Amazone
Hoofdlijnen
- Moeten we de genen van buitengewone mensen sparen voor klonen?
- Phototroph (Prokaryote Metabolism): Wat is het?
- Graafwespen en hun chemie
- Hoe beïnvloedt CO2 de opening van de huidmondjes?
- Soorten monomeren
- Nieuwe studies zijn bedoeld om sociaalwetenschappelijke methoden in natuurbehoudonderzoek te stimuleren
- Waar wordt de kern in de cel gevonden en waarom?
- Welk type organisch macromolecuul is glucose?
- Abiogenese: definitie, theorie, bewijs & voorbeelden
- Gegevensgestuurde modellering en op AI gebaseerde beeldverwerking om de productie te verbeteren

- Bezos belooft een bod van $ 1 miljard om de Indiase e-commercestorm het hoofd te bieden

- Winst luchtvaartmaatschappij Emirates meer dan verdubbeld op vrachtvraag

- Google toont AI-vooruitgang op zijn grote conferentie

- Onderzoekers ontwikkelen vaccin tegen aanvallen op machine learning


 New York verliest aanbieder van rideshare als Juno stopt
New York verliest aanbieder van rideshare als Juno stopt- NASA voltooit motortest afvuren van maanraket bij 2e poging
- Rutheniumregels voor nieuwe brandstofcellen
- Experts verklaren het effect van klimaatverandering op infrastructuur
- Onderzoekers meten het kielzog van supersonische projectielen
- De relatie tussen abiotische en biotische componenten van een bosecosysteem
- Nieuwe leerruimten:interactie tussen belanghebbenden en ontwikkeling van een operationele cultuur op school
- Southwest verlengt MAX-aarding tot april 2020
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
