Wetenschap
Schaalbare prognoses voor IoT in de cloud
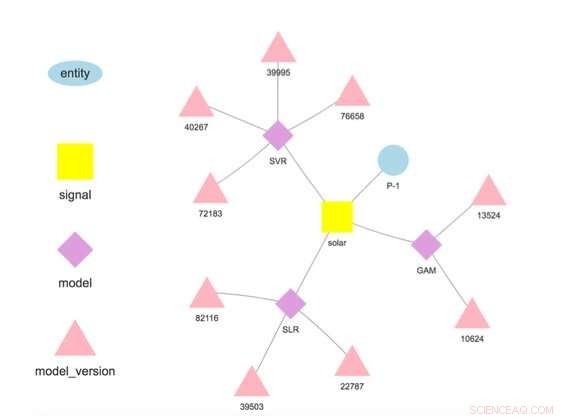
Figuur 1. Modelhiërarchie voor een geselecteerde entiteit en signaal. Krediet:IBM
Deze week op de internationale conferentie over datamining, IBM Research-Ierland-wetenschapper Francesco Fusco demonstreerde IBM Research Castor, een systeem voor het beheren van tijdreeksgegevens en -modellen op schaal en in de cloud. Bedrijven van vandaag draaien op prognoses. Of het nu een voorgevoel is van wat we denken dat er gaat gebeuren of het product van een zorgvuldig uitgekiende analyse, we hebben een beeld van wat er gaat gebeuren en handelen daarnaar. IBM Research Castor is voor IoT-gedreven bedrijven die honderden of duizenden verschillende voorspellingen voor tijdreeksen nodig hebben. Hoewel het model voor een individuele prognose misschien klein is, het bijhouden van de herkomst en prestaties van dit aantal modellen kan een uitdaging zijn. In tegenstelling tot AI-gestuurde gevallen die een klein aantal grote modellen gebruiken voor beeldverwerking of natuurlijke taal, dit werk richt zich op de IoT-toepassingen die een groot aantal kleinere modellen nodig hebben.
Ons systeem biedt een uitgebreide maar selectieve reeks mogelijkheden voor tijdreeksgegevens en -modellen. Het neemt gegevens op van IoT-apparaten of andere bronnen. Het biedt toegang tot de gegevens met behulp van semantiek, waardoor gebruikers gegevens als volgt kunnen ophalen:getTimeseries( myServer, "Winkel1234", "uuromzet").
Het slaat modellen op die zijn geschreven in R of Python voor training en scoren. Elk model is gekoppeld aan een entiteit die beschrijft waar de gegevens vandaan komen, zoals "Store1234" hierboven, en een signaal dat beschrijft wat er wordt gemeten, zoals "uuromzet". Modellen worden getraind en gescoord op door de gebruiker gedefinieerde frequenties, en in tegenstelling tot veel andere aanbiedingen, de voorspellingen worden automatisch opgeslagen.
Datawetenschappers implementeren modellen door een workflow in vier stappen te implementeren:
- Laad de gegevens voor training of scoren uit relevante gegevensbronnen;
- Transformeer die data in een dataframe voor modeltraining of scoring;
- Train het model om een versie te verkrijgen die geschikt is voor het maken van prognoses; en
- Scoor het model om hoeveelheden van belang te voorspellen.
Zodra het model is geïmplementeerd, het systeem voert de training en score uit, automatisch opslaan van het getrainde model en de prognoseresultaten. Gegevens die worden gebruikt bij training en scoren hoeven niet afkomstig te zijn van het platform, waardoor modellen gegevens uit meerdere bronnen kunnen gebruiken. In feite, dit is een belangrijke drijfveer voor ons werk:het maken van prognoses met toegevoegde waarde op basis van meerdere gegevensbronnen. Bijvoorbeeld, een bedrijf kan een deel van zijn eigen gegevens combineren met gegevens die zijn gekocht van een derde partij, zoals weersvoorspellingen, om een hoeveelheid rente te voorspellen.
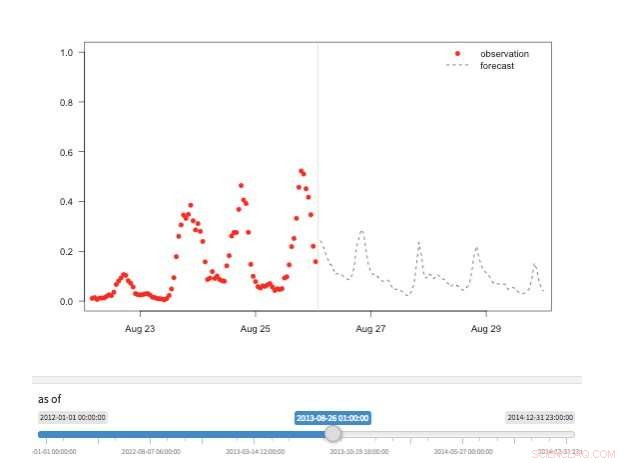
Figuur 2. "Tijdmachine"-weergave met beschikbare observaties en voorspellingen voor verschillende punten in de geschiedenis. Krediet:IBM
Ons systeem slaat modellen apart van configuratie- en runtimeparameters op. Deze scheiding maakt het mogelijk om enkele details van een model te wijzigen, zoals de API-sleutel voor toegang tot gegevens van derden of de scorefrequentie, zonder herplaatsing. Verschillende modellen voor dezelfde doelvariabele worden ondersteund en aangemoedigd om vergelijkingen van voorspellingen van verschillende algoritmen mogelijk te maken. Modellen kunnen aan elkaar worden geketend, zodat de uitvoer van het ene model de invoer voor het andere vormt als in een ensemble. Een model dat op een specifieke dataset is getraind, vertegenwoordigt een modelversie, die ook wordt gevolgd. Zo is het mogelijk om de herkomst van modellen en voorspellingen vast te stellen (Figuur 1).
Er zijn verschillende weergaven beschikbaar om prognosewaarden te verkennen. Uiteraard kunnen waarden zelf worden opgevraagd en gevisualiseerd. We ondersteunen ook een "tijdmachine"-weergave met de laatste voorspellingen en laatste waarnemingen (Figuur 2). In deze interactieve weergave de gebruiker kan verschillende punten in de geschiedenis selecteren en zien welke informatie op dat moment beschikbaar was. We ondersteunen ook een weergave van de prognose-evolutie met opeenvolgende prognoses voor hetzelfde tijdstip (Figuur 3). Op deze manier kunnen gebruikers zien hoe de voorspellingen veranderden naarmate de streeftijd dichterbij kwam.
Onder de motorkap, IBM Research Castor maakt intensief gebruik van serverless computing om resource-elasticiteit en kostenbeheersing te bieden. Bij typische implementaties worden modellen elke week of elke maand getraind en elk uur gescoord. Tijdens de training of het scoren van tijd, voor elk model wordt een serverloze functie gemaakt, waardoor honderden modellen op het gewenste tijdstip parallel kunnen trainen of scoren. Nadat dit werk is afgelopen, de computerbron verdwijnt totdat deze weer nodig is. In een meer conventionele workflow, virtuele machines of cloudcontainers zijn inactief wanneer ze niet in gebruik zijn, maar brengen nog steeds kosten met zich mee.
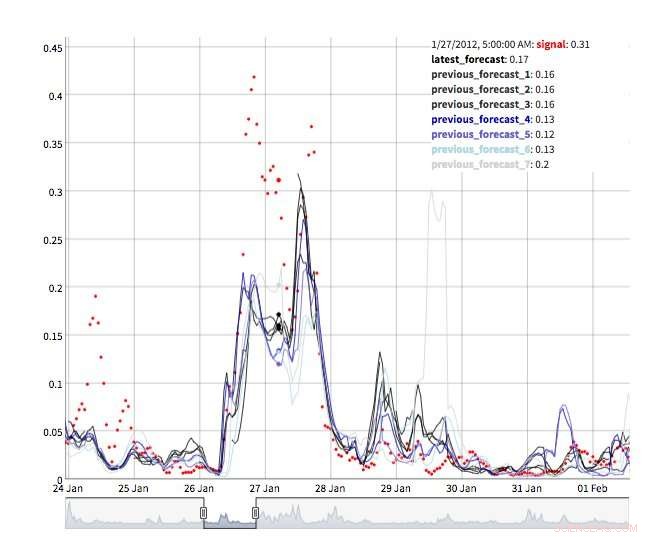
Figuur 3. Prognose evolutie. Krediet:IBM
IBM Research Castor implementeert native op IBM Cloud met behulp van de nieuwste services zoals IBM's DashDB, Componeren, Cloud-functies, en Kubernetes om een robuust en betrouwbaar systeem te bieden. Met een gerechtigde account op IBM Cloud, IBM Research Castor kan binnen enkele minuten worden geïmplementeerd, waardoor het ideaal is voor zowel proof-of-concept als langer lopende projecten. Clientpakketten / SDK's voor Python en R worden geleverd zodat datawetenschappers snel aan de slag kunnen in een vertrouwde omgeving en visualisatieteams kunnen gebruikmaken van bekende frameworks zoals Django en Shiny. Als deze niet passen bij uw toepassing, de op JSON gebaseerde berichten-API is ook beschikbaar.
Dit verhaal is opnieuw gepubliceerd met dank aan IBM Research. Lees hier het originele verhaal.
 De rotte appels uitvissen:nieuwe kwantitatieve methode om de veiligheid van voedsel te beoordelen
De rotte appels uitvissen:nieuwe kwantitatieve methode om de veiligheid van voedsel te beoordelen- Sensor detecteert vleugje slechte adem
- Hoe te verwijderen Ethanol van Gasoline
- Onderzoeksbevinding kan het energieverbruik en de kosten bij het maken van silicium verlagen
- Hoe de polariteit van verbindingen te vinden
- Wil je klimaatverandering tegengaan? Hier zijn 8 stappen die je kunt nemen
- De 20 beste plaatsen om stikstofvervuiling op Amerikaanse boerderijen aan te pakken
- Afbeelding:NASA ziet tropische cycloon Berguitta op weg naar Mauritius
- Marriott-hotels dumpen kleine plastic toiletflessen
- De verliezen na de aardbeving:verwoestend en kostbaar
Hoofdlijnen
- Wereldprimeur gebruikt satellieten en oceaanmodellen om de biodiversiteit op de Antarctische zeebodem te verklaren
- Evolutionaire relaties tussen prokaryoten en eukaryoten
- Dood door duizend sneden? Niet voor kleine populaties
- De voor- en nadelen van grote oren voor vleermuissoorten
- Gestratificeerd epitheelweefsel: definitie, structuur, typen
- Waarom verhuizen chloroplasten in Elodea?
- Parasitaire wormen wachten niet om te worden opgeslokt door nieuwe gastheren
- Trofisch niveau (voedselketen en web): definitie en voorbeelden (met diagram)
- Voelen planten pijn?
- Toyota, China's BYD kondigde elektrische auto-onderneming aan

- Smartphone versus virus, zal privacy altijd de verliezer zijn?

- De volgende generatie robotkakkerlak kan onderwateromgevingen verkennen

- Pixel 3a versus Pixel 3:geweldige camera voor de prijs maakt Googles telefoon van $ 399 de betere koop

- Pinterest, YouTube zegt optreden tegen antivaccinatieberichten


 Beleggers ontvluchten Bayer na tweede glyfosaat-proefslag (update)
Beleggers ontvluchten Bayer na tweede glyfosaat-proefslag (update)- Koel blijven in het nano-elektrische universum door warm te worden
- Hoe het aantal isomeren te berekenen
- Push om toeleveringsketens duurzamer te maken blijft in een stroomversnelling komen
- De zoektocht naar leven op Mars breidt zich uit naar het bestuderen van zijn manen
- Onderzoek onthult veelbelovende verschuivingen in vervuiling tijdens lockdown
- Ammoniaksynthese gemakkelijk gemaakt met 2D-katalysator
- Smartphone-makers wedden op opvouwbare schermen als next big thing
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
