Wetenschap
WaveGlow:een op stroom gebaseerd generatief netwerk om spraak te synthetiseren
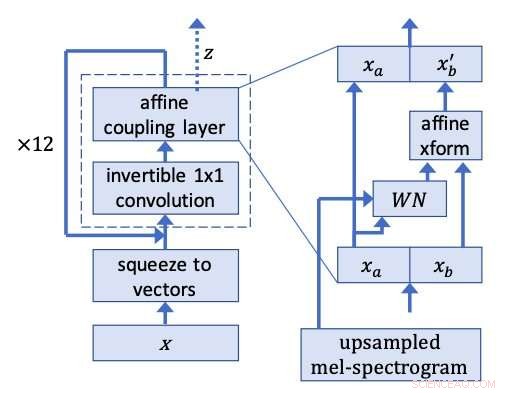
WaveGlow-netwerk. Krediet:Prenger, Valle, en Catanzaro.
Een team van onderzoekers van NVIDIA heeft onlangs WaveGlow ontwikkeld, een op flow gebaseerd netwerk dat hoogwaardige spraak kan genereren uit melspectrogrammen, die akoestische tijd-frequentierepresentaties van geluid zijn. hun methode, geschetst in een paper dat vooraf is gepubliceerd op arXiv, maakt gebruik van een enkel netwerk getraind met een enkele kostenfunctie, waardoor de trainingsprocedure eenvoudiger en stabieler wordt.
"De meeste neurale netwerken voor het synthetiseren van spraak waren te traag voor ons, "Ryan Prenger, een van de onderzoekers die het onderzoek heeft uitgevoerd, vertelde TechXplore. "Ze waren beperkt in snelheid omdat ze waren ontworpen om slechts één sample tegelijk te genereren. De uitzonderingen waren benaderingen van Google en Baidu die parallel zeer snel audio produceerden. deze benaderingen maakten gebruik van lerarennetwerken en studentennetwerken en waren te complex om te repliceren."
De onderzoekers lieten zich inspireren door Glow, een op flow gebaseerd netwerk van OpenAI dat parallel hoogwaardige afbeeldingen kan genereren, een vrij eenvoudige structuur behouden. Met behulp van een inverteerbare 1x1 convolutie, Glow behaalde opmerkelijke resultaten, het produceren van zeer realistische beelden. De onderzoekers besloten hetzelfde idee achter deze methode toe te passen op spraaksynthese.
"Denk aan de witte ruis die afkomstig is van een radio die niet op een zender is ingesteld, " legde Prenger uit. Die witte ruis is supergemakkelijk te genereren. Het basisidee van het synthetiseren van spraak met WaveGlow is om een neuraal netwerk te trainen om die witte ruis om te zetten in spraak. Als je een oud neuraal netwerk gebruikt, opleiding zal problematisch zijn. Maar als u specifiek een netwerk gebruikt dat zowel achteruit als vooruit kan worden uitgevoerd, de wiskunde wordt gemakkelijk en sommige trainingsproblemen verdwijnen."
De onderzoekers draaiden spraakfragmenten uit de trainingsdataset achterstevoren, WaveGlow trainen om te produceren wat sterk lijkt op witte ruis. Hun model past hetzelfde idee achter Glow toe op een WaveNet-achtige architectuur, vandaar de naam WaveGlow.
In een PyTorch-implementatie, WaveGlow produceerde audiosamples met een snelheid van meer dan 500 kHz, op een NVIDIA V100 GPU. Crowd-sourced mean opinion score (MOS)-tests op Amazon Mechanical Turk suggereren dat de aanpak een geluidskwaliteit levert die even goed is als de beste publiek beschikbare WaveNet-methode.
"In de wereld van spraaksynthese, er is behoefte aan modellen die spraak meer dan een orde van grootte sneller in realtime genereren, Prenger zei. "We hopen dat WaveGlow in deze behoefte kan voorzien en tegelijkertijd gemakkelijker te implementeren en te onderhouden is dan andere bestaande modellen. In de wereld van diep leren, we denken dat dit type benadering met behulp van een inverteerbaar neuraal netwerk en de resulterende eenvoudige verliesfunctie relatief weinig bestudeerd is. WaveGlow biedt nog een voorbeeld van hoe deze aanpak, ondanks zijn relatieve eenvoud, generatieve resultaten van hoge kwaliteit kan geven."
De code van WaveGlow is gemakkelijk online beschikbaar en is toegankelijk voor anderen die het willen proberen of ermee willen experimenteren. In de tussentijd, de onderzoekers werken aan het verbeteren van de kwaliteit van gesynthetiseerde audioclips door hun model te verfijnen en verdere evaluaties uit te voeren.
"We hebben niet veel analyses gedaan om te zien hoe klein van een netwerk we weg kunnen komen, "Zei Prenger. "De meeste van onze architectuurbeslissingen waren gebaseerd op zeer vroege delen van de training. Echter, kleinere netwerken met een langere trainingstijd kunnen geluid genereren dat net zo goed is. Er zijn veel interessante richtingen die dit onderzoek in de toekomst zou kunnen uitgaan."
© 2018 Wetenschap X Netwerk
 Noordelijke tropische droge trend is misschien gewoon een normale variatie
Noordelijke tropische droge trend is misschien gewoon een normale variatie- Hoe zouden wegen op zonne-energie werken?
- De Dode Zee – milieuonderzoek op de rand van uitersten
- Klimaatverandering, infrastructuur en de economische gevolgen van orkaan Harvey
- Grenzen overschrijden in het stroomgebiedbeheer van Louisiana
Hoofdlijnen
- Commensalisme:ik profiteer,
- Overeenkomsten van mitose en meiose
- Wat wordt er weergegeven als geen enkele kopie van een allel de expressie maskeert?
- Wat zijn twee typen endoplasmatisch reticulum?
- Onderzoek onthult hoe verontreinigende stoffen de vroege embryonale ontwikkeling beïnvloeden
- Nieuwe studie laat zien hoe mierenkolonies zich anders gedragen in verschillende omgevingen
- Cladistics: Definitie, methode en voorbeelden
- Verschil tussen koppelingstoewijzing en chromosoommapping
- Tonnen leven diep in het aardoppervlak gevonden
- Zesbenige robots van Tokyo Techs komen dichter bij de natuur

- Sociale media zijn niet allemaal slecht - het redt levens in rampgebieden
- DAWG-systeem is bedoeld om aanvallen te voorkomen die mogelijk zijn gemaakt door Meltdown en Spectre

- Snapchat is er voor jou met een nieuwe functie voor geestelijke gezondheid

- Sensorische huid helpt zachte robots om zich te oriënteren


 Mogelijke venus-tweeling ontdekt rond schemerige ster
Mogelijke venus-tweeling ontdekt rond schemerige ster- Foxconn-leiders, functionarissen van Wisconsin ontmoeten elkaar; details onduidelijk
- Domineren blanke mensen het buitenleven?
- Wetenschappers kraken de paranotenpuzzel, hoe komen de grootste noten naar boven?
- NASA's InSight-missie zal diep in het hart van Mars kijken voor aanwijzingen over zijn verleden
- Nieuw ontwerp laat microklokresonatoren rinkelen als een klok
- JPMorgan Chase onthult cryptocurrency-prototype
- Video:Hoe de baan van de aarde vrij te maken van ruimtepuin
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Portuguese | Swedish | German | Dutch | Danish | Norway | Spanish |

-
Wetenschap © https://nl.scienceaq.com
