Wetenschap
AI leren om te leren van niet-experts
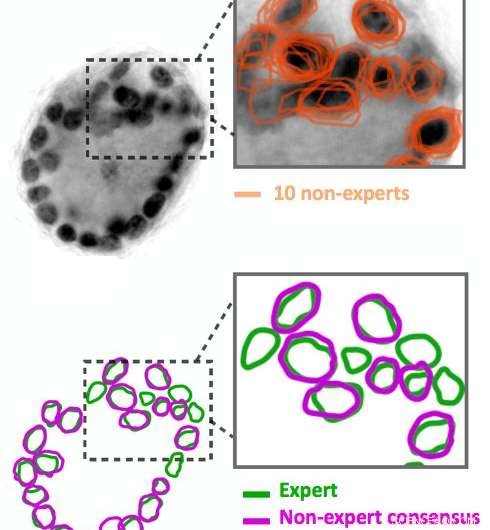
Niet-deskundige beeldannotaties zijn luidruchtig. Tien niet-experts schetsten de donkere zwarte cirkels in de afbeelding, dat zijn celkernen. Hun resultaten (in oranje weergegeven) komen niet precies overeen. Onze algoritmen zijn in staat om een consensusoverzicht (weergegeven in paars) af te leiden uit de gegevens met ruis. Vergelijk deze consensus met deskundige annotatie van dezelfde afbeelding (weergegeven in groen). Krediet:IBM
Vandaag rapporteerden mijn IBM-team en mijn collega's in het UCSF Gartner-lab in: Natuurmethoden een innovatieve benadering om datasets van niet-experts te genereren en deze te gebruiken voor training in machine learning. Onze aanpak is ontworpen om AI-systemen in staat te stellen net zo goed te leren van niet-experts als van door experts gegenereerde trainingsgegevens. We ontwikkelden een platform, genaamd Quanti.us, waarmee niet-experts afbeeldingen kunnen analyseren (een veel voorkomende taak in biomedisch onderzoek) en een geannoteerde dataset kunnen maken. Het platform wordt aangevuld met een reeks algoritmen die speciaal zijn ontworpen om dit soort "luidruchtige" en onvolledige gegevens correct te interpreteren. Samen gebruikt, deze technologieën kunnen toepassingen van machine learning in biomedisch onderzoek uitbreiden.
Niet-experts en luidruchtige gegevens
De beperkte beschikbaarheid van hoogwaardige geannoteerde datasets is een knelpunt bij het bevorderen van machine learning. Door algoritmen te maken die nauwkeurige resultaten kunnen leveren van annotaties van lagere kwaliteit - en een systeem om dergelijke gegevens snel te verzamelen - kunnen we het knelpunt helpen verlichten. Het analyseren van afbeeldingen op interessante kenmerken is een goed voorbeeld. Annotatie van afbeeldingen door experts is nauwkeurig maar tijdrovend, en geautomatiseerde analysetechnieken zoals op contrast gebaseerde segmentatie en randdetectie presteren goed onder gedefinieerde omstandigheden, maar zijn gevoelig voor veranderingen in de experimentele opstelling en kunnen onbetrouwbare resultaten opleveren.
Voer crowdsourcing in. Quanti.us gebruiken, we verkregen crowd-sourced beeldannotaties 10-50 keer sneller dan een enkele expert nodig zou hebben om dezelfde afbeeldingen te analyseren. Maar, zoals men zou verwachten, annotaties van niet-experts waren luidruchtig:sommige identificeerden een functie correct en andere waren off-target. We hebben algoritmen ontwikkeld om de luidruchtige gegevens te verwerken, het afleiden van de juiste locatie van een kenmerk uit de aggregatie van zowel on- als off-target hits. Toen we een diep convolutieregressienetwerk trainden met behulp van de crowd-sourced dataset, het presteerde bijna net zo goed als een netwerk dat was getraind in deskundige annotaties, met betrekking tot precisie en terugroepactie. Samen met het document waarin onze aanpak en strategie worden beschreven, we hebben de broncode voor ons algoritme vrijgegeven.
Toepassingen in cellulaire engineering
Beeldanalyse staat centraal in vele gebieden van kwantitatieve biologie en geneeskunde. Een paar jaar geleden hebben wij en onze medewerkers het door de NSF gefinancierde Center for Cellular Construction (CCC) aangekondigd, een wetenschappelijk en technologisch centrum dat pioniert in de nieuwe wetenschappelijke discipline van cellulaire engineering. CCC faciliteert nauwe samenwerking tussen experts van verschillende disciplines, zoals machinaal leren, natuurkunde, computertechnologie, cel- en moleculaire biologie, en genomica, om vooruitgang in cellulaire engineering te stimuleren. We willen cellen bestuderen en maken die kunnen worden gebruikt als geautomatiseerde machines, of ad-hocsensoren, om nieuwe en essentiële informatie te leren over een verscheidenheid aan biologische entiteiten en hun relatie met de omgeving waarin ze leven. We gebruiken beeldanalyse om de positie en grootte van interne celcomponenten te bepalen. Maar zelfs met geavanceerde beeldvormingstechnieken, exacte gevolgtrekking van cellulaire substructuren kan ongelooflijk luidruchtig zijn, waardoor het moeilijk is om op de componenten van de cel te werken. Onze techniek kan deze lawaaierige gegevens gebruiken om correct te voorspellen waar de relevante cellulaire structuren kunnen zijn, waardoor een betere identificatie mogelijk is van organellen die betrokken zijn bij de productie van belangrijke chemicaliën of potentiële medicijndoelen bij een ziekte.
Wij zijn van mening dat onze algoritmen een belangrijke eerste stap zijn naar complexere AI-platforms. Dergelijke systemen kunnen aanvullende paradigma's "mens in de lus" gebruiken, door een bioloog in te schakelen om fouten tijdens de trainingsfase te corrigeren, bijvoorbeeld, om de prestaties verder te verbeteren. We zien ook een mogelijkheid om onze methode buiten de biologie toe te passen op andere gebieden waar geannoteerde datasets van hoge kwaliteit schaars kunnen zijn.
Dit verhaal is opnieuw gepubliceerd met dank aan IBM Research. Lees hier het originele verhaal.
 Nieuwe moleculaire printtechnologie kan complexe chemische omgevingen nabootsen die op het menselijk lichaam lijken
Nieuwe moleculaire printtechnologie kan complexe chemische omgevingen nabootsen die op het menselijk lichaam lijken- Het toevoegen van een polymeer stabiliseert instortende metaal-organische raamwerken
- Bubbels helpen nieuwe katalysatoren zichzelf te optimaliseren
- Wat zijn de drie belangrijkste typen microscopen?
- Batterijen verborgen laag onthuld
- Zal het lonen van een koolstofarm pad lonend zijn voor Californië?
- Radioactieve elementen uit water filteren
- Wat is er zo speciaal aan een dinosaurus genaamd Leonardo?
- Synchrotron-licht om mijnafval in zeesediment in de Portman-baai te analyseren
- Onderzoekers ontwikkelen radars in de lucht om de kenmerken van Amerikaanse snowpacks voor watermodellen te meten
Hoofdlijnen
- Erfelijkheid: definitie, factor, soorten en voorbeelden
- Regenboogkleuren onthullen celgeschiedenis
- Star Treks Kobayashi Maru Oefening verkent situaties zonder winstoogmerk
- Het verschil tussen histon en nonhiston
- nieuwe ontdekking, meer bijen markeren Michigans eerst, volledige bijentelling
- Herten geven de voorkeur aan inheemse planten die blijvende schade aan bossen achterlaten
- Nieuwe analyse plaatst Hobbit op onverwachte ledemaat van de menselijke stamboom
- Landbouwgroepen dagen waarschuwing onkruidverdelger in Californië uit
- Ponso helpen, enige overlevende van Chimpansee-eiland in I. Coast
- Ruimtemotor met ionenaandrijving voor het eerst in vliegtuigen gebruikt

- Vuren leiden tot onenigheid in Google-rangen

- Nieuwe machine is bedoeld om een einde te maken aan de schande van de dood van het riool in India

- Zelfverwarmend, snelladende batterij maakt elektrische voertuigen klimaatbestendig

- Tesla-voorraad slipt door berichten dat het leveranciers om terugbetalingen heeft gevraagd


 Mentoren spelen een cruciale rol in de kwaliteit van de universiteitservaring, nieuwe peiling suggereert
Mentoren spelen een cruciale rol in de kwaliteit van de universiteitservaring, nieuwe peiling suggereert- Verbazingwekkend groene synthesemethode voor hightech kleurstoffen
- Ongelijkheid in wetenschapsfinanciering
- Zou het leven in olie kunnen beginnen?
- Dubbele staking om kanker te bestrijden
- De last van het klimaatrisico valt op de armen
- Team lost mysterie van colloïdale kettingen op
- Postglaciale geschiedenis van Lake of the Woods
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway | French |

-
Wetenschap © https://nl.scienceaq.com
