Wetenschap
Eet je je smaak met honden? testen, AI testen
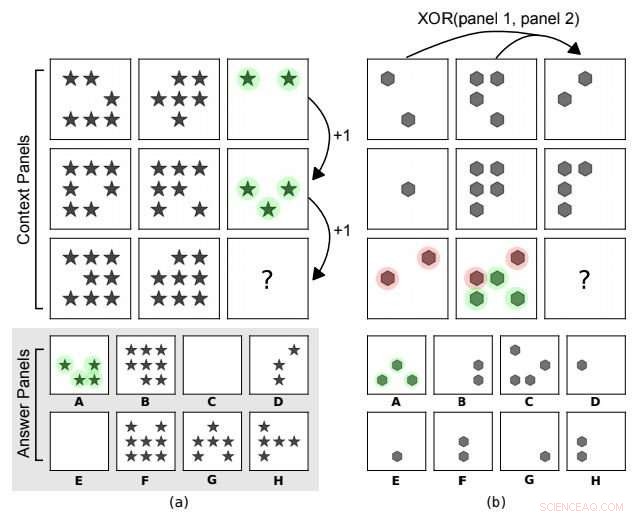
Progressieve Matrices in Raven-stijl. In (a) is de onderliggende abstracte regel een rekenkundige progressie op het aantal vormen langs de kolommen. In (b) is er een XOR-relatie op de vormposities langs de rijen (paneel 3 =XOR(paneel 1, paneel 2)). Andere kenmerken zoals vormtype spelen geen rol. A is de juiste keuze voor beide. Krediet:arXiv:1807.04225 [cs.LG]
testen, testen:DeepMind gaat AI zitten voor een IQ-test. Hoewel de resultaten van de AI-prestaties niet verbluffend zijn in het overtroeven of matchen van menselijke redeneringen, het is een begin. AI-wetenschappers erkennen dat het moeilijk is gebleken om hun vermogen om te redeneren over abstracte concepten vast te stellen. DeepMind wilde zien hoe AI zou kunnen presteren en het team stelde een dataset en uitdaging voor om abstract redeneren te onderzoeken.
Kan AI onze capaciteiten voor abstract redeneren evenaren? Zullen diepe neurale netwerken in de toekomst beter in staat zijn om abstracte visuele redeneerproblemen op te lossen? De DeepMind-onderzoekers zijn zeker op de zaak geweest.
hun papier, "Het meten van abstract redeneren in neurale netwerken, " staat op arXiv. Auteurs zijn David Barrett, Felix Heuvel, Adam Santoro, Ari Morcos, Timothy Lillicrap, van DeepMind. Je kunt zien waar ze naar op zoek waren en hoe ze hebben getest. Het artikel richt zich in feite op een benadering voor het meten van abstract redeneren in leermachines. In hun bespreking het team zei, Ja, er is vooruitgang geboekt op het gebied van redeneren en het leren van abstracte representatie in neurale netwerken, maar de mate waarin deze modellen zoiets als algemeen abstract redeneren vertonen 'is onderwerp van veel discussie'.
De modellen om te slagen moesten omgaan met generalisatieregimes waarin de trainings- en testgegevens verschilden. Ze zeiden dat ze een architectuur presenteerden met een structuur die was ontworpen om redeneren aan te moedigen. Resultaten:Gemengde zak. Ze zeiden dat hun model bedreven was in bepaalde vormen van generalisatie, maar zwak in anderen.
Niettemin, het is opmerkelijk dat ze manieren hebben onderzocht om sterker abstract redeneren in neurale netwerken te meten en uit te lokken.
"Standaard menselijke IQ-tests vereisen vaak dat testpersonen perceptueel eenvoudige visuele scènes interpreteren door principes toe te passen die ze door alledaagse ervaring hebben geleerd, ", aldus een DeepMind-blog. "We hebben nog niet de middelen om machine learning-agenten bloot te stellen aan een vergelijkbare stroom van 'alledaagse ervaringen', wat betekent dat we hun vermogen om kennis over te dragen van de echte wereld naar visuele redeneertests niet gemakkelijk kunnen meten. Niettemin, we kunnen een experimentele opstelling creëren die nog steeds goed gebruik maakt van menselijke visuele redeneertests."
Ze gingen verder met het bouwen van een generator voor matrixproblemen met een reeks abstracte factoren. Het team stimuleert meer onderzoek naar abstract redeneren, en ze maakten hun dataset publiekelijk beschikbaar.
De grote vraag is of wetenschappers menselijke analytische redeneervermogens kunnen bereiken.
Hoewel hun IQ-testresultaten misschien een allegaartje waren, de onderzoekers zien dit niet als een spel van winnen of opgeven. Ze zullen hun werk voortzetten om strategieën te onderzoeken om generalisatie te verbeteren en toekomstige modellen te verkennen. Als CIO Duik merkte op, "Intelligente assistenten hebben bergen gegevens gekregen om consumenten op bijna elk denkbaar gebied te helpen, maar wanneer onbekende problemen worden gepresenteerd, kunnen ze nog steeds tekortschieten."
De auteurs schreven, in hun samenvatting, "We stellen een dataset en uitdaging voor die zijn ontworpen om abstract redeneren te onderzoeken, geïnspireerd door een bekende menselijke IQ-test. Om te slagen in deze uitdaging, modellen moeten omgaan met verschillende generaliserende `regimes' waarin de trainings- en testgegevens op duidelijk gedefinieerde manieren van elkaar verschillen. We laten zien dat populaire modellen zoals ResNets slecht presteren, ook als de trainings- en testsets maar minimaal verschillen, en we presenteren een nieuwe architectuur, met een structuur die is ontworpen om redeneren aan te moedigen, dat doet het beduidend beter."
CIO Duik beschreven hun tests als visuele IQ-tests. In het proces, de auteurs waren geïnteresseerd om de prestaties te zien in het vermogen om te generaliseren wanneer testgegevens anders waren.
Het matchen van AI met menselijke vaardigheden voor abstractie blijft een zware strijd.
Als CIO Duik 's Alex Hickey schreef, AI zou verschillende betekenissen moeten onderscheiden tussen "spaghetti met kaas eten" en "spaghetti eten met honden".
De paper merkte op dat het testen van de mogelijkheden van neurale netwerken lastig kan zijn en dat neurale netwerken hun valkuilen hebben, gezien hun vermogen tot memoriseren en het vermogen om oppervlakkige statistische aanwijzingen te benutten.
© 2018 Tech Xplore
 De universele waarheid over plakkerige oppervlakken
De universele waarheid over plakkerige oppervlakken- Wetenschappers ontwikkelen moleculaire code voor melanine-achtige materialen
- Een oubollige oplossing om de verspreiding van het nieuwe coronavirus tegen te gaan
- Ultrazware precisiepolymeren
- Superspons belooft effectieve giftige opruiming van meren en meer
- NASA vernieuwt de focus op de bevroren gebieden van de aarde
- Net Zero toezeggingen gaan wereldwijd, nu moet actie op woorden volgen, zegt Oxford-ECIU-rapport
- Geofysisch onderzoek wil onthullen hoe vegetatie reageert op klimaatverandering
- Wetenschapper leidt aanstaande NASA-veldstudie van sneeuwstormen aan de oostkust
- Een supercellonweersbui volgen over de Great Plains
Hoofdlijnen
- Hinderlaag in een petrischaal
- Honden likken hun mond om te communiceren met boze mensen
- Op zoek naar het CRISPR Zwitsers zakmes
- Feiten over osmose voor kinderen
- 10 echt slimme mensen die echt domme dingen deden
- Hoge verwachtingen van Australische poging om pandawelpen te fokken
- Kenmerken van ATP
- Welke sequenties zorgen ervoor dat DNA uitpakt en ademt?
- Nucleïnezuren: structuur, functie, typen en voorbeelden






 Team werkt zoete scheidingsmethode uit de jaren 50 bij om nanodeeltjes van organismen te verwijderen
Team werkt zoete scheidingsmethode uit de jaren 50 bij om nanodeeltjes van organismen te verwijderen- Nieuwe manieren ontdekken om het Higgs-deeltje te zien
- Waarom de ontdekking van een schare quasars de inspanningen om de oorsprong van sterrenstelsels te begrijpen zal stimuleren?
- Mysterieuze ijzeren röntgenlijnen worden vreemder met zeer nauwkeurige metingen
- Welvarende landen hebben handel nodig om milieuproblemen te verminderen
- Een materieel toetsenbord gemaakt van grafeen
- Bijna tweederde van de Amerikaanse kinderen leeft in vermogensarmoede, nieuwe studie toont
- We kunnen de vrije wil misschien niet begrijpen met wetenschap. Dit is waarom
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
