Wetenschap
Multi-face tracking om AI te helpen de actie te volgen
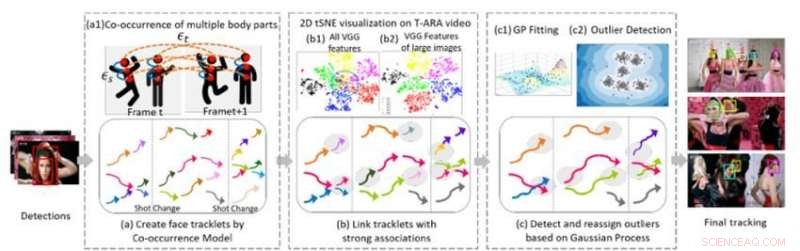
Figuur 1. Drie algoritmische kerncomponenten van onze methode voor het volgen van meerdere gezichten in een videosequentie. Krediet:IBM
Tijdens de recente conferentie over computervisie en patroonherkenning in 2018, Ik presenteerde een nieuw algoritme voor multi-face tracking, een essentieel onderdeel bij het begrijpen van video. Om visuele sequenties te begrijpen waarbij mensen betrokken zijn, AI-systemen moeten meerdere personen in verschillende scènes kunnen volgen, ondanks wisselende camerahoeken, verlichting, en verschijningen. Het nieuwe algoritme stelt AI-systemen in staat om deze taak te volbrengen.
Eerder werk op dit gebied was grotendeels gericht op het volgen van een enkele persoon of meerdere personen binnen een opname. De volgende stap is om meerdere mensen te volgen in een hele video die uit veel verschillende shots bestaat. Deze taak is een uitdaging omdat mensen de video herhaaldelijk kunnen verlaten en opnieuw kunnen bezoeken. Hun uiterlijk kan drastisch veranderen dankzij garderobe, kapsel, en make-up. Hun poses veranderen, en hun gezichten kunnen gedeeltelijk worden afgesloten door de kijkhoek, verlichting, of andere objecten in de scène. De camerahoek en zoom veranderen ook, en kenmerken zoals slechte beeldkwaliteit, slechte verlichting, en bewegingsonscherpte kan de moeilijkheidsgraad van de taak vergroten. Bestaande gezichtsherkenningstechnologieën werken mogelijk in meer beperkte gevallen, waarbij de afbeeldingen van goede kwaliteit zijn en het volledige gezicht van een persoon tonen, maar faal in onbeperkte video, waar de gezichten van mensen in profiel kunnen staan, afgesloten, bijgesneden, of wazig.
Een methode voor het volgen van meerdere gezichten
In samenwerking met professor Ying Hung, van de afdeling Statistiek en Biostatistiek aan de Rutgers University, we hebben een methode ontwikkeld om verschillende individuen in een videoreeks te herkennen en ze te herkennen als ze de video verlaten en vervolgens weer binnenkomen, ook al zien ze er heel anders uit. Om dit te doen, we maken eerst tracklets voor de aanwezigen in de video. De tracklets zijn gebaseerd op het gelijktijdig voorkomen van meerdere lichaamsdelen (gezicht, hoofd en schouders, bovenlichaam, en het hele lichaam) zodat mensen kunnen worden gevolgd, zelfs als ze niet volledig in het zicht van de camera zijn (bijv. hun gezichten zijn afgewend of afgesloten door andere objecten). We formuleren het meerpersoonsvolgprobleem als een grafiekstructuur G =(ν, ε) met twee soorten randen:εs en εt. Ruimtelijke randen s duiden de verbindingen van verschillende lichaamsdelen van een kandidaat binnen een frame aan en worden gebruikt om de veronderstelde toestand van een kandidaat te genereren. Tijdelijke randen geven de verbindingen aan van dezelfde lichaamsdelen over aangrenzende frames en worden gebruikt om de toestand van elke individuele persoon in verschillende frames te schatten. We genereren gezichtstracklets met behulp van gezichtsbegrenzende vakken uit de tracklets van elke individuele persoon en extraheren gezichtskenmerken voor clustering.
Het tweede deel van de methode verbindt tracklets die van dezelfde persoon zijn. Figuur 1 (b) toont 2D tSNE-visualisatie van geëxtraheerde VGG-face-functie op een muziekvideo. Het laat zien dat vergeleken met alle kenmerken (b1), kenmerk van grote afbeeldingen (b) zijn meer onderscheidend. We bouwen ondubbelzinnige verbindingen tussen tracklets door de gezichtsbeeldresolutie van de objecten en de relatieve afstanden van geëxtraheerde diepe kenmerken te analyseren. Deze stap genereert een eerste clusterresultaat. Empirische studies tonen aan dat op CNN gebaseerde modellen gevoelig zijn voor beeldwaas en ruis, omdat de netwerken over het algemeen zijn getraind op afbeeldingen van hoge kwaliteit. We genereren robuuste eindclusteringsresultaten door een Gaussian Process (GP) -model te gebruiken om de diepe functiebeperkingen te compenseren en de rijkdom aan gegevens vast te leggen. Anders dan op CNN gebaseerde benaderingen, GP-modellen bieden een flexibele parametrische benadering om de niet-lineariteit en ruimtelijk-temporele correlatie van het onderliggende systeem vast te leggen. Daarom, het is een aantrekkelijk hulpmiddel om te combineren met de op CNN gebaseerde benadering om de dimensie verder te verkleinen zonder complexe en ruimtelijke informatie over tijd en ruimte te verliezen. We passen het GP-model toe om uitbijters te detecteren, verwijder de verbanden tussen uitbijters en andere tracklets, en wijs de uitbijters vervolgens opnieuw toe aan verfijnde clusters die zijn gevormd nadat de uitbijters zijn losgekoppeld, waardoor hoogwaardige clusters ontstaan.
Meerdere gezichten volgen in muziekvideo's
Om de prestaties van onze aanpak te evalueren, we vergeleken het met de modernste methoden voor het analyseren van uitdagende datasets van onbeperkte video's. In een reeks experimenten, we gebruikten muziekvideo's, met een hoge beeldkwaliteit, maar belangrijke, snelle veranderingen in scène, camera-instelling, camerabeweging, verzinnen, en accessoires (zoals brillen). Ons algoritme presteerde beter dan andere methoden met betrekking tot zowel clusternauwkeurigheid als tracking. De zuiverheid van clusters was aanzienlijk beter met ons algoritme in vergelijking met de andere methoden (0,86 voor ons algoritme versus 0,56 voor de naaste concurrent die een van de muziekvideo's gebruikt). In aanvulling, onze methode bepaalde automatisch het aantal personen, of clusters, te volgen zonder dat handmatige videoanalyse nodig is.
De trackingprestaties van ons algoritme waren ook superieur aan de modernste methoden voor de meeste statistieken, inclusief terugroepen en precisie. Onze methode verhoogde merkbaar de meeste gevolgde (MT) en verminderde exemplaren van identiteitswisseling (IDS) en spoorfragmenten (Frag). De onderstaande video toont voorbeeldtrackingresultaten in verschillende muziekvideo's. Ons algoritme volgt op betrouwbare wijze meerdere personen over verschillende opnamen in de volledige onbeperkte video's, ook al hebben sommige individuen een zeer vergelijkbaar gezichtsuiterlijk, meerdere hoofdzangers verschijnen op een rommelige achtergrond vol met publiek, of sommige gezichten zijn zwaar afgesloten. Dit raamwerk voor het volgen van meerdere gezichten in video zonder beperkingen is een belangrijke stap in het verbeteren van het videobegrip. Het algoritme en zijn prestaties worden in meer detail beschreven in ons CVPR-document, "Een prior-minder methode voor het volgen van meerdere gezichten in video's zonder beperkingen."
Dit verhaal is opnieuw gepubliceerd met dank aan IBM Research. Lees hier het originele verhaal.

Hoofdlijnen
- Wat hebben alle levende organismen gemeen?
- Welke organellen bevinden zich in een prokaryote cel?
- Wat zijn voorbeelden van homozygote dominanten?
- Zijn er evolutionaire wortels voor menselijke obesitas?
- Hoe de hormonen van de hypofyse te onthouden
- Vier klassen Macromoleculen die belangrijk zijn voor levende wezens
- Campylobacter gebruikt andere organismen als Trojaans paard om nieuwe gastheren te infecteren
- Nieuwe aanwijzingen uit hersenstructuren van bidsprinkhaangarnalen
- Zwarte geit gaat weer gedijen in Israël
- Britse tiener die CIA-chef hackte krijgt twee jaar cel

- Australische luchtvaartmaatschappij Qantas schrapt 90 procent internationale routes

- Zelfrijdende shuttles:waar wachten we nog op?

- Economische zwaargewicht Boeing geplaagd door dubbele crises

- Amazon om meer dan 1 te creëren 000 nieuwe banen in Ierland


 Hoe een fabriek een nieuwe bestemming te geven in een crisis?
Hoe een fabriek een nieuwe bestemming te geven in een crisis?- Implantaat om hersenchemicaliën beter op te sporen na neurotrauma
- Laatste beelden van Cassini-ruimtevaartuig
- Afbeelding:vlucht naar ruimtestation boven de Bahama's
- Verschillen tussen een besloten aquifer en een onbeperkte aquifer
- Ongelijkheid:wat we hebben geleerd van de robots van het late Neolithicum
- Houten regengoten maken
- Homo naledi juveniele overblijfselen bieden aanwijzingen over hoe onze voorouders zijn opgegroeid
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
