Wetenschap
TACC bouwt naadloze software voor wetenschappelijke innovatie
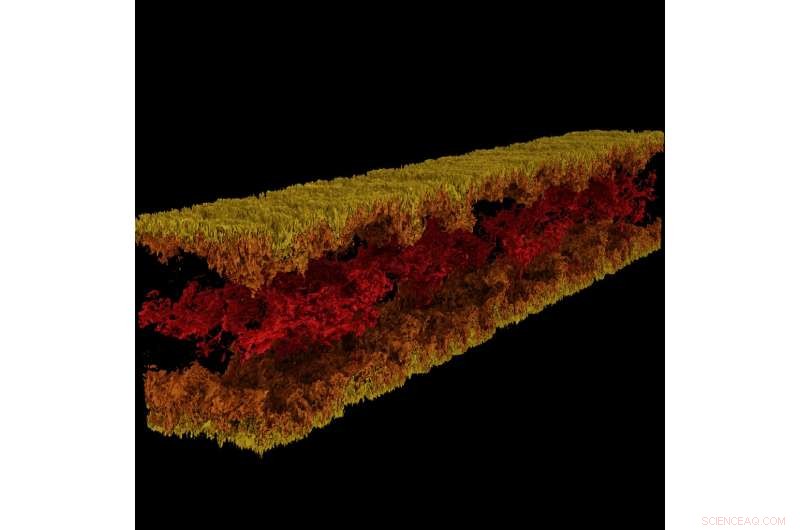
Turbulente kanaalstroomvisualisatie geproduceerd met GraviT. Krediet:visualisatie:Texas Advanced Computing Center. Gegevens:ICES, De Universiteit van Texas in Austin.
Groot, impactvolle wetenschap vereist een heel technologisch ecosysteem om vooruitgang te boeken. Dit omvat geavanceerde computersystemen, opslag met hoge capaciteit, hogesnelheidsnetwerken, stroom, afkoeling... de lijst gaat maar door.
Kritisch, het vereist ook state-of-the-art software:programma's die naadloos samenwerken om wetenschappers en ingenieurs in staat te stellen moeilijke vragen te beantwoorden, hun oplossingen delen, en onderzoek doen met de maximale efficiëntie en de minimale pijn.
Om deze kritieke vorm van wetenschappelijke vooruitgang te koesteren, in 2012 heeft NSF het programma Software Infrastructure for Sustained Innovation (SI2) opgezet, met als doel innovaties in onderzoek en onderwijs om te zetten in duurzame softwarebronnen die een integraal onderdeel zijn van de cyberinfrastructuur.
"Wetenschappelijke ontdekking en innovatie vorderen langs fundamenteel nieuwe wegen die worden geopend door de ontwikkeling van steeds geavanceerdere software, " schreef de National Science Foundation (NSF) in de SI2-programmaaanvraag. "Software is ook direct verantwoordelijk voor verhoogde wetenschappelijke productiviteit en aanzienlijke verbetering van de capaciteiten van onderzoekers."
Met vijf huidige SI2-onderscheidingen, en samenwerkende rollen op verschillende andere, het Texas Advanced Computing Center (TACC) is een van de nationale leiders in het ontwikkelen van software voor wetenschappelijk computergebruik. Hoofdonderzoekers van TACC zullen hun werk van 30 april tot 2 mei presenteren op de NSF SI2 Hoofdonderzoekersbijeenkomst 2018 in Washington, gelijkstroom
"Een deel van de missie van TACC is het verbeteren van de productiviteit van onderzoekers die onze systemen gebruiken, " zei Bill Barth, TACC-directeur van high performance computing en een voormalige ontvanger van een SI2-subsidie. "Het SI2-programma heeft ons daarbij geholpen door inspanningen te ondersteunen om nieuwe tools te ontwikkelen en bestaande tools uit te breiden met extra prestatie- en bruikbaarheidsfuncties."
Van frameworks voor grootschalige visualisatie tot automatische parallellisatietools en meer, Door TACC ontwikkelde software verandert de manier waarop onderzoekers in de toekomst rekenen.
Interactieve parallellisatietool
De kracht van supercomputers ligt voornamelijk in hun vermogen om wiskundige vergelijkingen parallel op te lossen. Neem een moeilijk probleem, verdeel het in zijn samenstellende delen, los elk deel afzonderlijk op en breng de antwoorden weer bij elkaar - dit is in wezen parallel computergebruik. Echter, de taak om je probleem zo te organiseren dat het kan worden aangepakt door een supercomputer is niet eenvoudig, zelfs voor ervaren computerwetenschappers.
Ritu Arora, een onderzoeker bij TACC, heeft gewerkt aan het verlagen van de lat voor parallel computergebruik door een tool te ontwikkelen die een seriële code kan omzetten, die slechts één processor tegelijk kan gebruiken, in een parallelle code die tien tot duizenden processors kan gebruiken. De tool analyseert een seriële applicatie, vraagt om aanvullende informatie van de gebruiker, past ingebouwde heuristieken toe, en genereert een parallelle versie van de seriële invoertoepassing.
Arora en haar medewerkers hebben de huidige versie van IPT in de cloud geïmplementeerd, zodat onderzoekers het gemakkelijk via een webbrowser kunnen gebruiken. Onderzoekers kunnen semi-automatisch parallelle versies van hun code genereren en de parallelle code testen op nauwkeurigheid en prestaties op TACC- en XSEDE-bronnen, inclusief Stampede2, Lonestar5, en Komeet.
"De omvang van de maatschappelijke impact van IPT is een directe functie van het belang van HPC in STEM en opkomende niet-traditionele domeinen, en de steile uitdagingen waarmee domeinexperts en studenten worden geconfronteerd bij het beklimmen van de leercurve voor parallel programmeren, "Zei Arora. "Naast het verkorten van de ontwikkelingstijd en de uitvoeringstijd van de applicaties op HPC-platforms, IPT zal het energieverbruik verminderen en de prestaties van de HPC-platforms maximaliseren door de mogelijkheid om hybride code te genereren."

GraviT stelde onderzoekers in staat om raytracing-visualisaties te maken met behulp van gegevens van Enzo, een simulatiecode ontworpen voor rijke, multi-fysica hydrodynamische astrofysische berekeningen. Krediet:Universiteit van Texas in Austin
Als een voorbeeld van de mogelijkheden van IPT, Arora wijst op een recente poging om een toepassing van moleculaire dynamica (MD) te parallelliseren. Door de seriële applicatie te parallelliseren met OpenMP op een hoog abstractieniveau - dat wil zeggen, zonder dat de gebruiker de syntaxis van OpenMP op laag niveau kende - ze bereikten een snelheidsverbetering van 88% in de code.
Ze kwantificeerden ook de impact van IPT in termen van gebruikersproductiviteit door het aantal regels code te meten dat een onderzoeker moet schrijven tijdens het proces van het handmatig parallelliseren van een applicatie versus het gebruik van IPT.
"In onze testcases IPT verbeterde de gebruikersproductiviteit met meer dan 90%, in vergelijking met het handmatig schrijven van de code, en de parallelle code heeft gegenereerd die binnen 10% van de prestaties van de best beschikbare handgeschreven parallelle code voor die toepassingen ligt, " zei Arora. "We zijn erg blij met het succes tot nu toe."
TACC breidt IPT uit om aanvullende typen seriële toepassingen te ondersteunen, evenals toepassingen die onregelmatige berekenings- en communicatiepatronen vertonen.
(Bekijk een videodemonstratie van IPT waarin TACC het proces laat zien van het parallelliseren van een moleculaire dynamica-toepassing met het OpenMP-programmeermodel.)
GraviT
Wetenschappelijke visualisatie - het proces waarbij ruwe gegevens worden omgezet in interpreteerbare afbeeldingen - is een belangrijk aspect van onderzoek. Echter, het kan een uitdaging zijn wanneer u gegevenssets op petabyteschaal probeert te visualiseren die zijn verspreid over vele knooppunten van een computercluster. Zeker als je geavanceerde visualisatiemethoden probeert te gebruiken, zoals raytracing, een techniek om een afbeelding te genereren door het pad van licht als pixels in een beeldvlak te volgen en de effecten van de ontmoetingen met virtuele objecten te simuleren.
Om dit probleem aan te pakken, Paul Navratil, directeur visualisatie bij TACC, heeft geleid tot een poging om GraviT te creëren, een schaalbare, raytracing-framework met gedistribueerd geheugen en softwarebibliotheek voor toepassingen die gegevens bevatten die zo groot zijn dat deze zich niet in het geheugen van een enkel rekenknooppunt kunnen bevinden. Medewerkers aan het project zijn onder meer Hank Childs (University of Oregon), Chuck Hansen (Universiteit van Utah), Matt Turk (Nationaal Centrum voor Supercomputing-toepassingen) en Allen Malony (ParaTools).
GraviT werkt op verschillende hardwareplatforms, including the Intel Xeon processors and NVIDIA GPUs. It can also function in heterogeneous computing environments, bijvoorbeeld, hybrid CPU and GPU systems. GraviT has been successfully integrated into the GLuRay OpenGL-based ray tracing interface, the VisIt visualization toolkit, the VTK visualization toolkit, and the yt visualization framework.
"High-fidelity rendering techniques like ray tracing improve visual analysis by providing the same spatial cues of light and shadow that we see in the world around us, but these are challenging to use in distributed contexts, " said Navratil. "GraviT enables these techniques to be used efficiently across distributed computing resources, unlocking their potential for large scale analysis and to be used in situ, where data is not written to disk prior to analysis."
(The GraviT source code is available at the TACC GitHub site ).
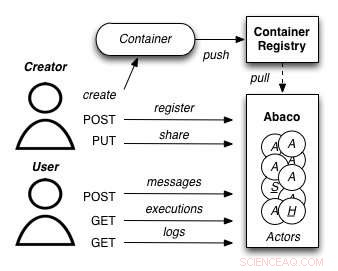
A diagram showing how the Abaco "Actor" model works. Credit:University of Texas at Austin
Abaco
The increased availability of data has enabled entirely new kinds of analyses to emerge, yielding answers to many important questions. Echter, these analyses are complex and frequently require advanced computer science expertise to run correctly.
Joe Stubbs, who leads TACC's Cloud and Interactive Computing (CIC) group, is working on a project that simplifies how researchers create analysis tools that are reliable and scalable. Het project, known as Abaco, adapts the "Actor" model, whereby software systems are designed as a collection of simple functions, which can then be provided as a cloud-based capability on high performance computing environments.
"Abaco significantly simplifies the way scientific software is developed and used, " said Stubbs. "Scientific software developers will find it much easier to design and implement a system. Verder, scientists and researchers that use software will be able to easily compose collections of actors with pre-determined functionality in order to get the computation and data they need."
The Abaco API (application programming interface) combines technologies and techniques from cloud computing, including Linux Containers and the "functions-as-a-service" paradigm, with the Actor model for concurrent computation. Investigators addressing grand challenge problems in synthetic biology, earthquake engineering and food safety are already using the tool to advance their work. Stubbs is working to extend Abaco's ability to do data federation and discoverability, so Abaco programs can be used to build federated datasets consisting of separate datasets from all over the internet.
"By reducing the barriers to developing and using such services, this project will boost the productivity of scientists and engineers working on the problems of today, and better prepare them to tackle the new problems of tomorrow, " Stubbs said.
Expanding volunteer computing
Volunteer computing uses donated computing time on consumer devices such as home computers and smartphones to conduct scientific investigations. Early successes from this approach include the discovery of the structure of an enzyme involved in reproduction of HIV by FoldIt participants; and the detection of pulsars using Einstein@Home.
Volunteer computing can provide greater computing power, at lower cost, than conventional approaches such as organizational computing centers and commercial clouds, but participation in volunteer computing efforts is yet to reach its full potential.
TACC is partnering with the University of California at Berkeley and Purdue University to build new capabilities for BOINC (the most common software framework used for volunteer computing) to grow this promising mode of distributed computing. The project involves two complementary development efforts. Eerst, it adds BOINC-based volunteer computing conduits to two major high-performance computing providers:TACC and nanoHUB, a web portal for nano science that provides computing capabilities. Op deze manier, the project benefits the thousands of scientists who use these facilities and creates technologies that make it easy for other HPC providers to add their own volunteer computing capability to their systems.
Tweede, the team will develop a unified interface for volunteer computing, tentatively called Science United, where donors can register to participate and scientists can market their volunteer computing projects to the public.
TACC is currently setting up a BOINC server on Jetstream and using containerization technologies, such as Docker and VirtualBox, to build and package popular applications that can run in high-throughput computing mode on the devices of volunteers. Initial applications being tested include AutoDock Vina, used for drug discovery, and OpenSees, used by the natural hazards community. Als volgende stap, TACC will develop the plumbing required for selecting and routing qualified jobs from TACC resources to the BOINC server.
"By creating a huge pool of low-cost computing power that will benefit thousands of scientists, and increasing public awareness of and interest in science, the project plans to establish volunteer computing as a central and long-term part of the U.S. scientific cyber infrastructure, " said David Anderson, the lead principal investigator on the project from UC Berkeley.
 Wereldsnelheidsrecord voor polymeersimulaties meer dan honderdvoudig verbrijzeld
Wereldsnelheidsrecord voor polymeersimulaties meer dan honderdvoudig verbrijzeld- Virtuele bibliotheek van 1 miljoen nieuwe macrolide-steigers kan de ontdekking van geneesmiddelen helpen versnellen
- Het gebruik van materiaal met een hoge energiedichtheid in het ontwerp van de elektrode verbetert lithiumzwavelbatterijen
- Nieuwe coating met dubbele werking voorkomt dat bacteriën kruisbesmetting van verse producten mogelijk maken
- Vuurmierengifverbindingen kunnen leiden tot huidbehandelingen
- Onderzoekers leggen de wetenschap en geschiedenis uit achter de overgang van oude booreilanden naar permanente riffen
- Bezos Earth Fund geeft bijna $ 800 miljoen aan klimaatgroepen in eerste subsidieronde
- Boren naar olie in de Grote Australische Bocht zou rampzalig zijn voor het zeeleven en de lokale gemeenschap
- Welk type oceaanzone doen palingen live?
- Verbrande bomen en miljarden in contanten:hoe een klimaatprogramma in Californië ervoor zorgt dat bedrijven blijven vervuilen
Hoofdlijnen
- Microbiële bewoner stelt kevers in staat zich te voeden met een bladdieet
- Herstel van iconische inheemse vogel veroorzaakt problemen in stedelijke gebieden
- Ezels hebben meer bescherming nodig tegen de winter dan paarden
- Een universele voedsel- en alarmsignaal gevonden in zoogdierbloed
- Eerste luxe Perigord-truffel wordt in Groot-Brittannië verbouwd
- Verdediging tegen bijna elke prijs
- Waarvoor gebruikt het lichaam nucleïnezuren?
- Hoeveel steenarenden zijn er?
- Wat zijn de stappen in de meiose die de variabiliteit verhogen?
- Motorloze pompen en zelfregelende kleppen gemaakt van ultradunne film

- Een nieuwe benadering om oplossingsverwerkbare 2D-halfgeleiders te maken

- Netflix-effect:Snoersnijden versnelt op Amerikaanse markt

- Platform voor mobiele netwerken zou diensten tot snelheden van 100 Gbps brengen

- Lufthansa waarschuwt luchthavencapaciteit om groei onder druk te zetten


 Canada geeft grote vervuilers een pauze op koolstofheffingen
Canada geeft grote vervuilers een pauze op koolstofheffingen- Welk type binding ontstaat in wolfraam?
- Indonesische vrouwen pakken plastic afval steen voor steen aan
- Sloveense eco-held die een cementreus verpletterde
- Amerikaanse luchtvaartmaatschappijen schrappen vluchten vanwege viruscrisis
- De connectiviteit van vloeistoffen met meerdere componenten in subductiezones
- Franse wijnproductie getroffen door hittegolf
- Waarom microplastic afval de volgende grote bedreiging voor onze zeeën kan zijn
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
