Wetenschap
Hoe duidelijker rapportage van negatieve experimentele resultaten de reactieplanning in de chemie zou verbeteren
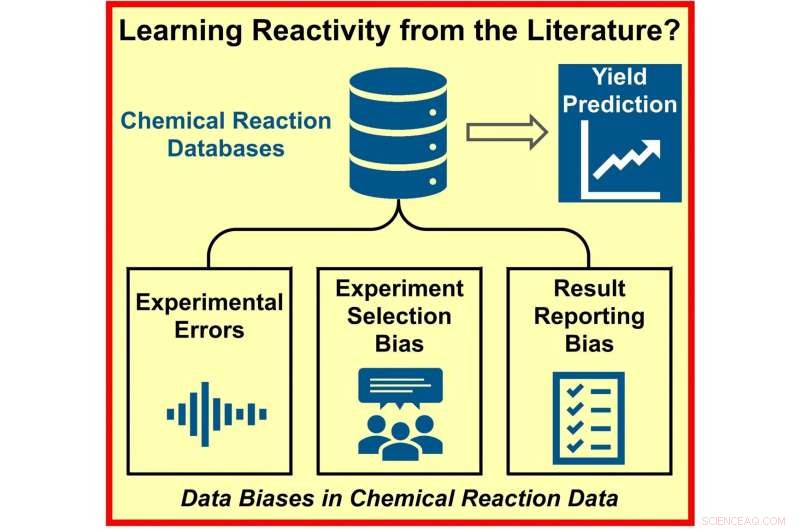
Krediet:Angewandte Chemie
Databases met enorme hoeveelheden experimentele gegevens zijn beschikbaar voor onderzoekers in een breed scala aan chemische disciplines. Een team van onderzoekers heeft echter ontdekt dat de beschikbare gegevens niet succesvol zijn in het voorspellen van de opbrengsten van nieuwe syntheses met behulp van kunstmatige intelligentie (AI) en machine learning. Hun studie gepubliceerd in het tijdschrift Angewandte Chemie International Edition suggereert dat dit grotendeels te wijten is aan de neiging van wetenschappers om mislukte experimenten niet te rapporteren.
Hoewel op AI gebaseerde modellen bijzonder succesvol zijn geweest in het voorspellen van moleculaire structuren en materiaaleigenschappen, geven ze nogal onnauwkeurige voorspellingen voor informatie met betrekking tot productopbrengsten bij synthese, zoals Frank Glorius en zijn team van onderzoekers van de Westfälische Wilhelms-Universität Münster, Duitsland, hebben ontdekt .
De onderzoekers schrijven dit falen toe aan de gegevens die worden gebruikt om AI-systemen te trainen. "Interessant is dat de voorspelling van reactieopbrengsten (reactiviteit) veel uitdagender is dan de voorspelling van moleculaire eigenschappen. Reagentia, reagentia, hoeveelheden, omstandigheden, de experimentele uitvoering - ze bepalen allemaal de opbrengst, en dus wordt het probleem van opbrengstvoorspelling zeer data -intensief", legt Glorius uit. Dus, ondanks de enorme hoeveelheden beschikbare literatuur en resultaten, kwamen de onderzoekers tot het besef dat de gegevens niet geschikt zijn voor nauwkeurige voorspellingen van de verwachte opbrengst.
Het probleem is niet alleen te wijten aan een gebrek aan experimenten. Daarentegen identificeerde het team drie mogelijke oorzaken voor bevooroordeelde gegevens. Ten eerste kunnen de resultaten van chemische syntheses gebrekkig zijn als gevolg van experimentele fouten. Ten tweede, wanneer scheikundigen hun experimenten plannen, kunnen ze, bewust of onbewust, vooringenomenheid introduceren op basis van persoonlijke ervaring en vertrouwen op gevestigde methoden. Ten slotte, aangezien alleen reacties met een positief resultaat naar verwachting bijdragen aan vooruitgang, worden mislukte reacties minder vaak gemeld.
Om erachter te komen welke van deze drie factoren de grootste invloed had, hebben Glorius en het team met opzet de datasets aangepast voor vier verschillende, veelgebruikte (en dus datarijke) organische reacties. Ze hebben de experimentele fout kunstmatig vergroot, de grootte van de datasamplingsets verkleind of negatieve resultaten uit de gegevens verwijderd. Uit hun onderzoek bleek dat de experimentele fout de minste invloed had op het model, terwijl de bijdrage van het ontbreken van negatieve resultaten fundamenteel was.
De groep hoopt dat deze bevindingen wetenschappers zullen aanmoedigen om mislukte experimenten en hun successen altijd te melden. Dit zou de beschikbaarheid van gegevens voor het trainen van AI verbeteren, wat uiteindelijk zou helpen om de planning te versnellen en experimenten efficiënter te maken. Glorius voegt eraan toe dat "machine learning in de (moleculaire) chemie de efficiëntie drastisch zal verhogen en dat er minder reacties hoeven te worden uitgevoerd om een bepaald doel te bereiken, bijvoorbeeld een optimalisatie. wereld - duurzamer." + Verder verkennen
Chemici gebruiken lichtenergie om kleine moleculaire ringen te produceren
 Vrijstaande microwire-array maakt flexibel zonnevenster mogelijk
Vrijstaande microwire-array maakt flexibel zonnevenster mogelijk- Aangepaste sequenties voor polymeren die zichtbaar licht gebruiken
- Hoe de efficiëntie van glycolyse te berekenen
- Wat zijn de verschillende soorten microscopie die in een microbiologisch laboratorium worden gebruikt?
- Het percentage opbrengst
- Ernst van Noord-Pacific stormen op hoogste punt in meer dan 1, 200 jaar
- Herstel Amazones van bosverlies beperkt door klimaatverandering
- Zeewier zinkt diep, koolstof meenemen
- EPA's COVID-19-beleid zal de toegang van het publiek tot klimaatgegevens verder beperken
- Welke plaatsen hebben een subarctisch klimaat?
Hoofdlijnen
- 3 geredde dolfijnen zwemmen vrij uit het Indonesische heiligdom
- Wat kan er gebeuren als Meiose verkeerd gaat?
- Een menselijk hart maken van pop-flessen
- Wetenschappelijke evaluatie van neushoorndiëten verbetert dierentuin
- Zelfverdediging voor planten
- Wat is de rol van het IgM-antilichaam?
- Vogelweervrienden:studenten uit Arkansas printen 3-D eendenpoot
- Bioloog onderzoekt de voor- en nadelen van virtuele en augmented reality bij het lesgeven in milieukunde
- Bewaken van genetische mutaties die belangrijk zijn voor panterbeheer in Florida
- Onderzoekers ontdekken nieuw fotoactiveringsmechanisme voor polymeerproductie
- Multifunctionele droom keramische matrixcomposieten zijn geboren

- Kristaloorlogen:onderzoek kan leiden tot efficiëntere methoden voor kristaltechnologie

- Onderzoekers ontwikkelen methode om het skelet van veelvoorkomende chemicaliën te verbeteren
- Wetenschappers verduidelijken aspect van interacties tussen vaste stoffen en vloeistoffen in dunne film


 5 Vereisten om mineraal te zijn
5 Vereisten om mineraal te zijn - Nanovezels dragen giftige peptiden in kankercellen
- Voorbeelden van zuurbuffers
- Hooggerechtshof verwerpt beroep tegen netneutraliteit
- Helicaten ontmoeten rotaxanen om belofte te creëren voor toekomstige ziektebehandeling
- Amerikaanse fintech-gigant FIS neemt betalingsbedrijf Worldpay . over
- Hoe lumen berekenen per Watt
- Wat is een ongelijkheid?
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
