Wetenschap
Een AI-ondersteunde analyse van de driedimensionale distributie van sterrenstelsels in ons universum
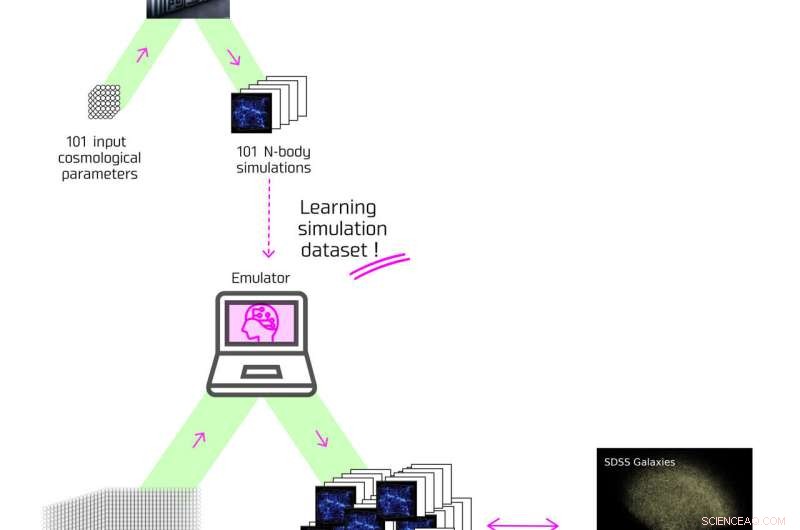
Stroomschema van hoe de door het onderzoeksteam ontwikkelde emulator werkt. Krediet:Kavli IPMU, NAOJ
Door een machine learning-techniek, een neurale netwerkmethode, toe te passen op gigantische hoeveelheden simulatiegegevens over de vorming van kosmische structuren in het universum, heeft een team van onderzoekers een zeer snel en zeer efficiënt softwareprogramma ontwikkeld dat theoretische voorspellingen kan doen over structuur vorming. Door modelvoorspellingen te vergelijken met feitelijke waarnemingsdatasets, slaagde het team erin kosmologische parameters nauwkeurig te meten, meldt een onderzoek in Physical Review D .
Toen het grootste sterrenstelselonderzoek tot nu toe ter wereld, de Sloan Digital Sky Survey (SDSS), een driedimensionale kaart van het universum maakte via de waargenomen verdeling van sterrenstelsels, werd duidelijk dat sterrenstelsels bepaalde kenmerken hadden. Sommige zouden samenklonteren, of zich verspreiden in filamenten, en op sommige plaatsen waren er holtes waar helemaal geen sterrenstelsels bestonden. Al deze sterrenstelsels evolueerden niet op een uniforme manier, ze werden gevormd als gevolg van hun lokale omgeving. Over het algemeen zijn onderzoekers het erover eens dat deze niet-uniforme verdeling van sterrenstelsels het gevolg is van de effecten van de zwaartekracht die worden veroorzaakt door de verspreiding van "onzichtbare" donkere materie, de mysterieuze materie die nog niemand rechtstreeks heeft waargenomen.
Door de gegevens in de driedimensionale kaart van sterrenstelsels in detail te bestuderen, konden onderzoekers de fundamentele grootheden blootleggen, zoals de hoeveelheid donkere materie in het universum. In de afgelopen jaren zijn N-lichaamsimulaties op grote schaal gebruikt in onderzoeken die de vorming van kosmische structuren in het universum nabootsen. Deze simulaties bootsen de aanvankelijke inhomogeniteiten bij hoge roodverschuiving na door een groot aantal N-lichaamsdeeltjes die donkere materiedeeltjes effectief vertegenwoordigen, en simuleren vervolgens hoe de distributie van donkere materie in de loop van de tijd evolueert, door zwaartekrachttrekkrachten tussen deeltjes in een uitdijend universum te berekenen. De simulaties zijn echter meestal duur en nemen tientallen uren in beslag op een supercomputer, zelfs voor één kosmologisch model.

Verdeling van ongeveer 1 miljoen sterrenstelsels waargenomen door Sloan Digital Sky Survey (linksboven) en een ingezoomde afbeelding van het dunne rechthoekige gebied (linksonder). Dit kan worden vergeleken met de verdeling van onzichtbare donkere materie die wordt voorspeld door supercomputersimulatie, uitgaande van het kosmologische model dat onze AI afleidt (rechtsboven). Rechtsonder zie je de verdeling van nepsterrenstelsels die zijn gevormd in gebieden met een hoge dichtheid van donkere materie. De voorspelde distributie van sterrenstelsels deelt de karakteristieke patronen zoals clusters, filamenten en holtes van sterrenstelsels die worden gezien in de werkelijke SDSS-gegevens. Krediet:Takahiro Nishimichi
Een team van onderzoekers, geleid door voormalig Kavli Institute for the Physics and Mathematics of the Universe (Kavli IPMU) Projectonderzoeker Yosuke Kobayashi (momenteel postdoctoraal onderzoeksmedewerker aan de Universiteit van Arizona), en met inbegrip van Kavli IPMU Professor Masahiro Takada en Kavli IPMU Visiting Scientists Takahiro Nishimichi en Hironao Miyatake combineerden machinaal leren met numerieke simulatiegegevens door de supercomputer "ATERUI II" van het National Astronomical Observatory of Japan (NAOJ) om theoretische berekeningen van het vermogensspectrum te genereren, de meest fundamentele hoeveelheid gemeten uit melkwegonderzoeken, wat onderzoekers vertelt statistisch gezien hoe sterrenstelsels in het heelal zijn verdeeld.
Gewoonlijk zouden er enkele miljoenen N-lichaamsimulaties moeten worden uitgevoerd, maar Kobayashi's team was in staat om machine learning te gebruiken om hun programma te leren het vermogensspectrum met hetzelfde nauwkeurigheidsniveau te berekenen als een simulatie, zelfs voor een kosmologisch model waarvoor de simulatie was nog niet uitgevoerd. Deze technologie wordt een emulator genoemd en wordt al gebruikt in de informatica buiten de astronomie.
"Door machine learning te combineren met numerieke simulaties, die veel kosten, hebben we gegevens van astronomische waarnemingen met hoge precisie kunnen analyseren. Deze emulators zijn eerder gebruikt in kosmologische studies, maar bijna niemand heeft rekening kunnen houden met de talrijke andere effecten, die kosmologische parameterresultaten in gevaar zouden brengen met behulp van echte onderzoeksgegevens van sterrenstelsels. Onze emulator kan en was in staat om echte observatiegegevens te analyseren. Deze studie heeft een nieuwe grens geopend voor grootschalige structurele gegevensanalyse, "zei de hoofdauteur Kobayashi .
Om de emulator echter toe te passen op werkelijke onderzoeksgegevens van sterrenstelsels, moest het team rekening houden met de onzekerheid van de "sterrenstelselbias", een onzekerheid die rekening houdt met het feit dat onderzoekers niet nauwkeurig kunnen voorspellen waar sterrenstelsels zich in het universum vormen vanwege hun gecompliceerde fysica die inherent is aan de vorming van sterrenstelsels .
Om deze moeilijkheid te overwinnen, concentreerde het team zich op het simuleren van de verdeling van donkere materie "halo's", waar sprake is van een hoge dichtheid van donkere materie en een grote kans op vorming van sterrenstelsels. Het team slaagde erin een flexibele modelvoorspelling te doen voor een bepaald kosmologisch model, door een voldoende aantal "hinderlijke" parameters te introduceren om rekening te houden met de onzekerheid over de vooroordelen van sterrenstelsels.
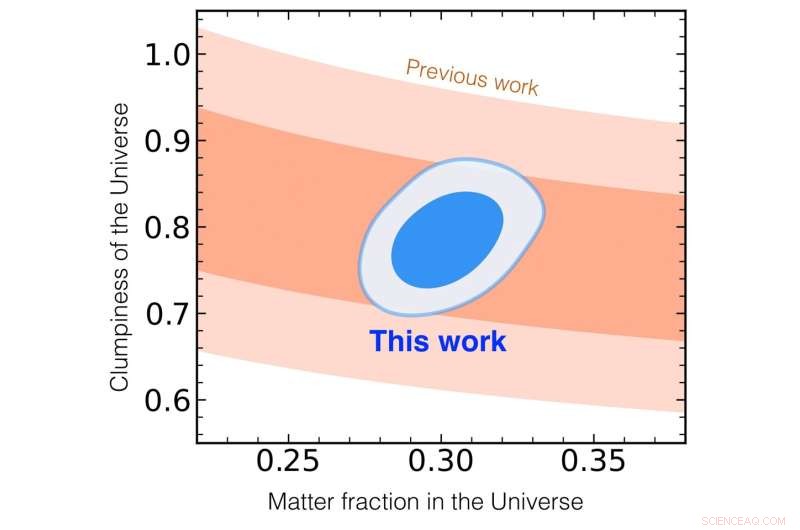
Een vergelijking van de driedimensionale melkwegkaart van Sloan Digital Sky Survey en de resultaten die zijn gegenereerd door de emulator die is ontwikkeld door Kobayashi et al. De x-as toont de fractie van de materie in het huidige heelal, de y-as toont de fysieke parameters die overeenkomen met de klonterigheid van het huidige heelal (hoe groter het aantal, hoe meer sterrenstelsels er in dat heelal zijn). De lichtblauwe en donkerblauwe banden komen overeen met een betrouwbaarheid van 68% en 95%, en binnen dit gebied wordt de waarschijnlijkheid weergegeven dat hier een echte waarde van het universum is. De oranje band komt overeen met de resultaten van de SSDS. Krediet:Yosuke Kobayashi
Vervolgens vergeleek het team de voorspelling van het model met een werkelijke SDSS-gegevensset en heeft het met succes kosmologische parameters met hoge precisie gemeten. Het bevestigt als een onafhankelijke analyse dat slechts ongeveer 30 procent van alle energie afkomstig is van materie (voornamelijk donkere materie), en dat de resterende 70 procent het resultaat is van donkere energie die de versnelde uitdijing van het universum veroorzaakt. Ze slaagden er ook in om de klonterigheid van materie in ons universum te meten, terwijl de conventionele methode die werd gebruikt om de 3D-kaarten van sterrenstelsels te analyseren, deze twee parameters niet tegelijkertijd kon bepalen.
De nauwkeurigheid van hun parametermeting overtreft die verkregen door de eerdere analyses van melkwegonderzoeken. Deze resultaten demonstreren de effectiviteit van de emulator die in dit onderzoek is ontwikkeld. De volgende stap voor het onderzoeksteam zal zijn om door te gaan met het bestuderen van de massa van donkere materie en de aard van donkere energie door hun emulator toe te passen op melkwegkaarten die zullen worden vastgelegd door de Prime Focus Spectrograph, in ontwikkeling, geleid door de Kavli IPMU, om te worden gemonteerd op de Subaru-telescoop van NAOJ. + Verder verkennen
Kunstmatige intelligentietool ontwikkeld om de structuur van het universum te voorspellen

Hoofdlijnen
- De voordelen van het hebben van een groot aantal chromosomen
- Wat doet Choline voor het lichaam?
- Soorten redeneren in geometrie
- Intra-rij onkruid wieden mogelijk met vision-systemen
- Hondenurine om bedreigde bonte plevieren te redden
- The Differences in Fraternal & Paternal Twins
- Helder en fotostabiel groen fluorescerend eiwit afgeleid van Japanse kwallen
- Monitoring van microben om marsonauten gezond te houden
- Hoe een utility-functie af te leiden






 asteroïden, waterstof is een geweldig recept voor leven op Mars
asteroïden, waterstof is een geweldig recept voor leven op Mars- Hoe werkt Paper Chromatography en waarom scheiden pigmenten zich op verschillende punten?
- Verschillen tussen koolstofvezel en fiberglas
- Huishoudens die magneten gebruiken
- Tropische cycloon Alcides regenval waargenomen door GPM Satellite
- Onderzoekers observeren dynamische kwantumfase-overgangen in een interactief veellichamensysteem
- Sterke maar dunne transparante films gemaakt van cellulose nanovezels met brede toepasbaarheid
- Reconstructie van 3D magnetische topologie van zonne-protuberansen op de schijf
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
