Wetenschap
Onderzoeksbewijs onthult misbruik van Holocaust-datasets
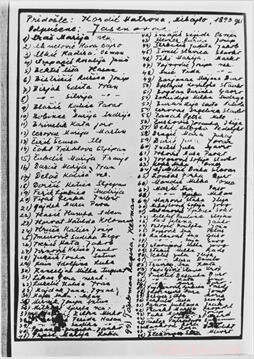
Een van de meer dan 7, 000 lijsten met namen uit concentratiekampen in het U.S. Holocaust Memorial Museum. Dit is een handgeschreven lijst van Servische en Kroatische vrouwen die naar het concentratiekamp Jasenovac zijn gedeporteerd. Krediet:Holocaust Memorial Museum in de Verenigde Staten
Faculteitslid Luchtvaart- en Ruimtevaarttechniek Melkior Ornik is ook een wiskundige, een geschiedenisfanaat, en een sterk voorstander van integriteit als het gaat om het gebruik van harde wetenschap in openbare discussies. Dus, toen een verhaal opdook in zijn nieuwsfeed over een paar onderzoekers die een statistische methode ontwikkelden om datasets te analyseren en deze gebruikten om zogenaamd het aantal Holocaustslachtoffers uit een concentratiekamp in Kroatië te weerleggen, het trok natuurlijk zijn aandacht.
Ornik is een professor in de afdeling Luchtvaart- en Ruimtevaarttechniek aan de Universiteit van Illinois Urbana-Champaign. Hij ging verder met het diepgaand bestuderen van het onderzoek en gebruikte de methode om dezelfde gegevens van het Holocaust Memorial Museum in de Verenigde Staten opnieuw te analyseren. Daarna schreef hij een weerleggingspaper waarin hij de bevindingen van de onderzoekers ontkracht.
Het weerwoord van Ornik is gepubliceerd in hetzelfde tijdschrift als het originele artikel. Hij zei dat de redacteur hem had gevraagd een lijst met antwoorden op te nemen op enkele van de mogelijke vragen die andere wetenschappers zouden kunnen hebben als ze zijn artikel lezen. Een paar weken later, het tijdschrift plaatste een notitie bij het originele artikel waarin stond dat ze de mening van de auteurs niet onderschrijven of delen, en raadde aan Orniks paper te lezen.
"Als wetenschappers, als ingenieurs, Ik denk dat het onze plicht is om gebrekkige en gebrekkige wetenschap te corrigeren, "Zei Ornik. "Er wordt zoveel moeite gedaan om het publiek en de beleidsmakers in de wetenschap te laten geloven, dat wanneer een wiskunde-expert zegt dat ze bewijs hebben, het geeft geloofwaardigheid aan het argument. Maar wanneer hun beweringen aantoonbaar niet waar zijn, het is niet goed voor de wetenschap en het is niet goed voor de samenleving. Daarom is het vooral belangrijk voor wetenschappers om valse bevindingen aan te vechten wanneer we ze ontdekken."
Volgens Ornik, sommige individuen propageren de opvatting dat concentratiekampen niet bestonden of niet werden gebruikt om mensen te doden, of dat het momenteel algemeen aanvaarde aantal slachtoffers aanzienlijk is opgedreven. De meeste historici nemen de beweringen niet serieus in het licht van de enorme hoeveelheid beschikbare gegevens en bewijzen.
"Voor de auteurs van het originele artikel om te beweren dat ze wiskundig bewijs hebben gevonden dat de lijst met slachtoffers van dat kamp is verzonnen, heeft duidelijke historische implicaties, " zei Ornik. "Ik denk, tot op zekere hoogte is het kwaad al geschied, maar ik voelde de behoefte om vast te leggen met de veronderstellingen, onnauwkeurigheden, en misbruik van de ruwe museumgegevens die ik in het oorspronkelijke onderzoek vond."
Het artikel waarop Ornik reageerde, presenteert een nieuwe methode om anomalieën in een reeks histogrammen te identificeren. Ornik zei dat hij de verdiensten van de methode die in het originele artikel wordt gepresenteerd niet betwist, alleen de toepassing ervan op het concentratiekamp Jasenovac.
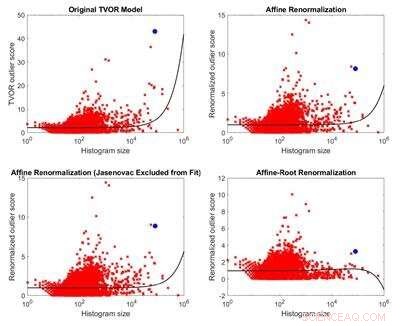
Vergelijking van het oorspronkelijke uitbijteridentificatiemodel en drie daarvan afgeleide modellen. Omdat de veronderstellingen niet van toepassing zijn op de beschouwde dataset, het oorspronkelijke model heeft geen theoretische basis. Drie alternatieve modellen zijn minder bevooroordeeld dan het oorspronkelijke model en leveren tegengestelde resultaten op. Krediet:Melkior Ornik
Ornik werd wantrouwend over de conclusies van het artikel omdat de onderzoekers in één geval suggereerden dat een kleinere lijst van nature een kleinere uitbijterscore heeft, maar ze vergeleken scores over de grootte van de slachtofferlijst om te beweren dat degene die betrekking had op Jasenovac, een van de grootste, problematisch was.
"Ik begon te kijken of er een vooroordeel was voor de grootte en of ze eigenlijk meer geneigd waren om de vlag van problematisch zijn toe te wijzen aan een grotere lijst of niet. En het blijkt, ondanks de beweringen van de auteurs, zij waren, "Zei Ornik. "De grotere lijsten zullen waarschijnlijk problematischer worden berekend dan de kleinere lijsten wanneer hun methode op de gegevens wordt toegepast."
Ornik, die vaak vergelijkbare statistische analyses gebruikt in ruimtevaarttoepassingen, legde een andere reden uit dat hun statistische argument niet werkt.
"Als je naar gegevens kijkt, een verzameling van alles, en als je een uitbijter wilt achterhalen - iets dat anders is - moet je aannemen dat alle stukjes gegevens uit dezelfde bron komen, dezelfde verdeling. Maak een lijst van slachtoffers per geboortejaar. Het zou een grafiek opleveren van de leeftijden van elke persoon. Stel dat 10 procent ouder is dan 70 jaar. Nutsvoorzieningen, die verdeling zou niet waar zijn voor een lijst van gedeporteerde kinderen, bijvoorbeeld, omdat die lijst per definitie, is structureel anders. Het is ook anders dan een lijst van iedereen die een identiteitskaart heeft. Identiteitskaarten worden alleen afgegeven aan mensen die geen kinderen zijn. Nog, de lijsten waarmee deze onderzoekers werkten kwamen uit een veelheid van bronnen en bevatten lijsten van kinderen, lijsten van mensen die gaan trouwen, lijsten van krijgsgevangenen - dingen die per definitie niet uit dezelfde distributie kunnen komen."
Een andere grote fout in het originele papier, Ornik zei, is dat sommige dubbele lijsten werden behandeld als twee afzonderlijke lijsten. Dit betekende dat ongeveer 67 procent van hun volledige database eigenlijk sublijsten van de grotere lijst was.
"De 7, 000-plus-lijsten die online zijn gepubliceerd door het Holocaust Museum zijn niet samengesteld, " zei Ornik. "Bijvoorbeeld, er zijn twee lijsten die precies dezelfde gegevens bevatten; de ene is in het cyrillisch en de andere gebruikt het Latijnse alfabet. Maar ze behandelden ze als twee afzonderlijke lijsten. Er zijn andere lijsten met dezelfde naam, maar er is geen manier om te weten of ze dezelfde persoon zijn of twee verschillende mensen die op dezelfde dag zijn geboren met identieke namen. Ze hadden de zeer flagrante fouten kunnen verwijderen waarin een lijst duidelijk wordt gedupliceerd, maar de rest, u zou toegang moeten hebben tot de originele historische gegevens."
Zowel het originele papier als het papier van Ornik, "Reageer op 'TVOR:discrete totale variatie-uitbijters vinden tussen histogrammen, '" zijn gepubliceerd in IEEE-toegang .
 Onderzoekers gebruiken maïszetmeel om ongedierte te bestrijden
Onderzoekers gebruiken maïszetmeel om ongedierte te bestrijden- Onderzoekers ontwikkelen tools om 3D-weergave van grote RNA-moleculen te verscherpen
- Drie manieren waarop de polariteit van watermoleculen het gedrag van water beïnvloeden
- Techniek maakt handig, nauwkeurige optische beeldvorming van individuele eiwitten
- Wanneer Starfish op het strand halen?
Hoofdlijnen
- Invasieve planten hebben een ongekend vermogen om nieuwe continenten en klimaten te verkennen
- Waarom zijn er 61 Anticodonen?
- Genetische aandoeningen: definitie, oorzaken, lijst met zeldzame en veel voorkomende ziekten
- Hoe koeien tevreden te houden?
- Erfelijkheid: definitie, factor, soorten en voorbeelden
- Invasieve superschurkenkrab kan door zijn kieuwen heen eten
- Ondergewaardeerde microben krijgen nu de eer voor het behouden van twee banen in de bodem
- Wat zijn de stappen in de meiose die de variabiliteit verhogen?
- Wat is de chemische samenstelling van de meeste sterren?
- Studie benadrukt de impact van het helpen van seksverslaafde studenten om hiv onder de knie te krijgen, lessen zwangerschapspreventie

- Helpt of schaadt piraterij de online mond-tot-mondreclame rond filmreleases?

- Lawaai kan je van je eten afhouden

- PEMDAS gebruiken en oplossen in volgorde van bewerkingen (voorbeelden)

- Als mensen met een verstandelijke beperking niet kunnen trouwen, ze lopen het risico op een gedwongen huwelijk


 Op naar lucht:uitgestorven zeeschorpioenen kunnen uit het water ademen, fossiele detective onthult
Op naar lucht:uitgestorven zeeschorpioenen kunnen uit het water ademen, fossiele detective onthult- De oudste krater ter wereld van een meteoriet is toch geen inslagkrater
- Nieuwe methode helpt bij het detecteren van biocontaminanten die gemakkelijk in water worden overgedragen en in de industrie worden gebruikt
- Topologische isolatoren verbinden met magnetische materialen voor energiezuinige elektronica
- Boeing meldt winst in eerste kwartaal, liften 2018 voorspelling
- Intrinsiek ferromagnetisme op lange afstand in tweedimensionale materialen
- Stralingsgordels van Saturnus:een vreemdeling voor de zonnewind
- Politieke factoren bij migratie
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
