Wetenschap
Machine learning-technologie om vreemde gebeurtenissen tussen LHC-gegevens te volgen
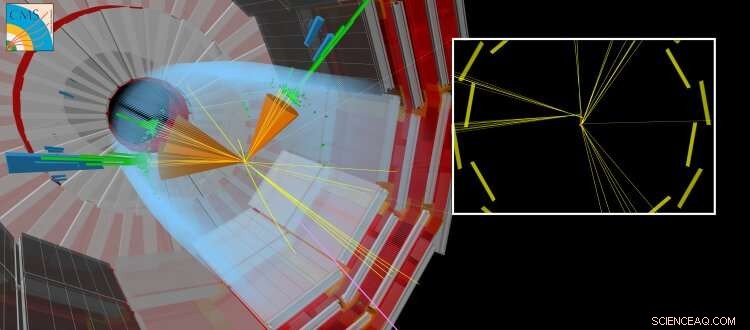
Een gesimuleerde CMS-botsing waarbij samen met andere 'gewone' jets een langlevend deeltje wordt geproduceerd. Het langlevende deeltje reist een korte afstand af voordat het vervalt, het creëren van deeltjes die verplaatst lijken te zijn vanaf het punt waar de LHC-stralen met elkaar in botsing kwamen. Krediet:CERN
Vandaag de dag, kunstmatige neurale netwerken hebben een impact op veel gebieden van ons dagelijks leven. Ze worden gebruikt voor een breed scala aan complexe taken, zoals autorijden, spraakherkenning uitvoeren (bijvoorbeeld Siri, Cortana, Alexa), suggesties voor winkelitems en trends, of het verbeteren van visuele effecten in films (bijv. geanimeerde personages zoals Thanos uit de film Oneindige Oorlog door Marvel).
traditioneel, algoritmen zijn handgemaakt om complexe taken op te lossen. Dit vereist dat experts een aanzienlijke hoeveelheid tijd besteden aan het identificeren van de optimale strategieën voor verschillende situaties. Kunstmatige neurale netwerken - geïnspireerd door onderling verbonden neuronen in de hersenen - kunnen automatisch van gegevens een bijna optimale oplossing voor het gegeven doel leren. Vaak, het geautomatiseerd leren of de "training" die nodig is om deze oplossingen te verkrijgen, wordt "gesuperviseerd" door het gebruik van aanvullende informatie die door een deskundige wordt verstrekt. Andere benaderingen zijn "zonder toezicht" en kunnen patronen in de gegevens identificeren. De wiskundige theorie achter kunstmatige neurale netwerken is in de loop van tientallen jaren geëvolueerd, maar pas onlangs hebben we ons begrip ontwikkeld over hoe we ze efficiënt kunnen trainen. De vereiste berekeningen lijken erg op de berekeningen die worden uitgevoerd door standaard videokaarten (die een grafische verwerkingseenheid of GPU bevatten) bij het renderen van driedimensionale scènes in videogames. De mogelijkheid om kunstmatige neurale netwerken in relatief korte tijd te trainen, wordt mogelijk gemaakt door gebruik te maken van de enorm parallelle computermogelijkheden van GPU's voor algemeen gebruik. De bloeiende videogame-industrie heeft de ontwikkeling van GPU's gestimuleerd. Deze vooruitgang, samen met de aanzienlijke vooruitgang in de theorie van machine learning en de steeds groter wordende hoeveelheid gedigitaliseerde informatie, heeft geholpen om het tijdperk van kunstmatige intelligentie en "deep learning" in te luiden.
Op het gebied van hoge-energiefysica, het gebruik van machine learning-technieken, zoals eenvoudige neurale netwerken of beslissingsbomen, al tientallen jaren in gebruik. Recenter, de theorie en experimentele gemeenschappen wenden zich steeds meer tot de nieuwste technieken, zoals "diepe" neurale netwerkarchitecturen, om ons te helpen de fundamentele aard van ons universum te begrijpen. Het standaardmodel van de deeltjesfysica is een samenhangende verzameling natuurkundige wetten - uitgedrukt in de taal van de wiskunde - die de fundamentele deeltjes en krachten beheersen, die op hun beurt de aard van ons zichtbare heelal verklaren. Bij de CERN LHC, veel wetenschappelijke resultaten richten zich op de zoektocht naar nieuwe "exotische" deeltjes die niet worden voorspeld door het standaardmodel. Deze hypothetische deeltjes zijn de manifestaties van nieuwe theorieën die vragen beantwoorden als:waarom bestaat het heelal voornamelijk uit materie in plaats van antimaterie, of wat is de aard van donkere materie?
-

Figuur 1:Schema van de netwerkarchitectuur. De bovenste (oranje en blauwe) delen van het diagram illustreren de componenten van het netwerk die worden gebruikt om jets te onderscheiden die worden geproduceerd bij het verval van langlevende deeltjes van jets die op andere manieren worden geproduceerd, getraind met gesimuleerde gegevens. Het onderste (groene) deel van het diagram toont de componenten die zijn getraind met behulp van echte botsingsgegevens. Krediet:CERN
-
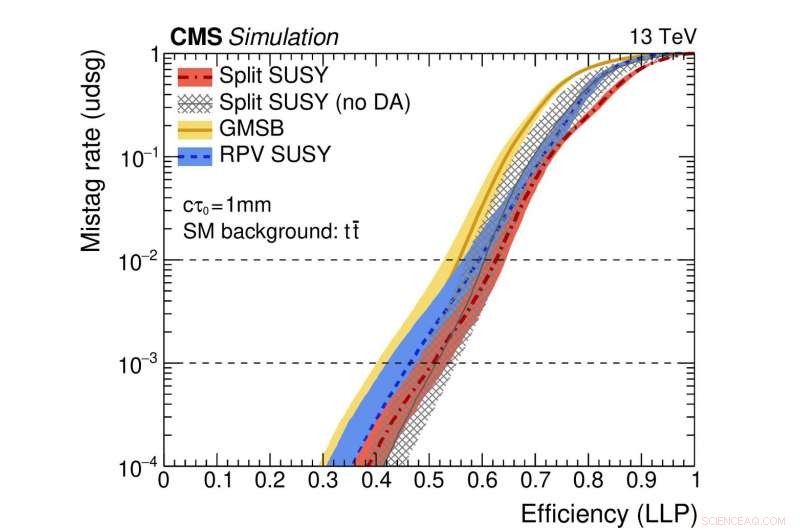
Figuur 2:Een illustratie van de prestaties van het netwerk. De gekleurde curven vertegenwoordigen de prestaties van verschillende theoretische supersymmetrische modellen. De horizontale as geeft de efficiëntie voor het correct identificeren van een langlevend deeltjesverval (d.w.z. de echt-positieve snelheid). De verticale as toont het corresponderende fout-positieve percentage, dat is de fractie van standaard jets die ten onrechte zijn geïdentificeerd als afkomstig van het verval van een langlevend deeltje. Als voorbeeld, we gebruiken een punt van de rode curve waar de fractie echte langlevende deeltjes die correct zijn geïdentificeerd 0,5 is (d.w.z. 50%). Deze methode identificeert ten onrechte slechts één regelmatige jet op duizend ten onrechte als afkomstig van een langlevend deeltjesverval. Krediet:CERN
Onlangs, zoektochten naar nieuwe deeltjes die meer dan een vluchtig moment in de tijd bestaan voordat ze vervallen tot gewone deeltjes hebben bijzondere aandacht gekregen. Deze "langlevende" deeltjes kunnen meetbare afstanden afleggen (fracties van millimeters of meer) van het proton-protonbotsingspunt in elk LHC-experiment voordat ze vervallen. Vaak, theoretische voorspellingen gaan ervan uit dat het langlevende deeltje niet detecteerbaar is. In dat geval, alleen de deeltjes van het verval van het onontdekte deeltje zullen sporen achterlaten in de detectorsystemen, wat leidt tot de nogal atypische experimentele signatuur van deeltjes die schijnbaar uit het niets verschijnen en verplaatst zijn vanaf het botsingspunt.
Een nieuw aspect van deze studie is het gebruik van gegevens van echte botsingsgebeurtenissen, evenals gesimuleerde gebeurtenissen, om het netwerk te trainen. Deze benadering wordt gebruikt omdat de simulatie, hoewel zeer geavanceerd, niet uitputtend alle details van de echte botsingsgegevens reproduceert. Vooral, de jets die voortkomen uit langlevende deeltjesverval zijn een uitdaging om nauwkeurig te simuleren. Het effect van het toepassen van deze techniek, genaamd "domeinaanpassing, " is dat de informatie die door het neurale netwerk wordt geleverd overeenkomt met een hoge mate van nauwkeurigheid voor zowel echte als gesimuleerde botsingsgegevens. Dit gedrag is een cruciale eigenschap voor algoritmen die zullen worden gebruikt bij zoekopdrachten naar zeldzame nieuwe natuurkundige processen, omdat de algoritmen robuustheid en betrouwbaarheid moeten aantonen wanneer ze op gegevens worden toegepast.
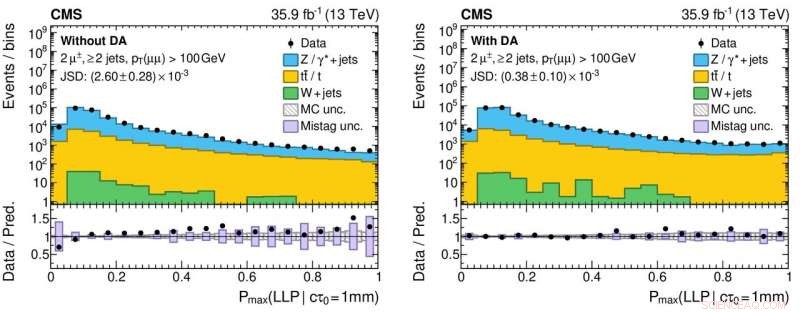
Figuur 3:Histogrammen van de uitvoerwaarden van het neurale netwerk voor echte (zwarte cirkelvormige markeringen) en gesimuleerde (gekleurde gevulde histogrammen) proton-protonbotsingsgegevens zonder (linkerpaneel) en met (rechterpaneel) de toepassing van domeinaanpassing. De onderste panelen geven de verhoudingen weer tussen het aantal echte gegevens en gesimuleerde gebeurtenissen die uit elke histogrambak zijn verkregen. De verhoudingen zijn aanzienlijk dichter bij de eenheid voor het rechterpaneel, wat wijst op een beter begrip van de prestaties van het neurale netwerk voor echte botsingsgegevens, wat cruciaal is om vals-positieve (en vals-negatieve!) wetenschappelijke resultaten te verminderen bij het zoeken naar exotische nieuwe deeltjes. Krediet:CERN
De CMS-samenwerking zal deze nieuwe tool inzetten als onderdeel van haar voortdurende zoektocht naar exotische, langlevende deeltjes. Dit onderzoek maakt deel uit van een groter, gecoördineerde inspanning bij alle LHC-experimenten om moderne machinetechnieken te gebruiken om de manier waarop de grote gegevensmonsters worden geregistreerd door de detectoren en de daaropvolgende gegevensanalyse te verbeteren. Bijvoorbeeld, het gebruik van domeinaanpassing kan het gemakkelijker maken om robuuste machinaal aangeleerde modellen in te zetten als onderdeel van toekomstige resultaten. De ervaring die is opgedaan met dit soort onderzoeken zal het fysica-potentieel tijdens run 3 vergroten, vanaf 2021, en verder met de High Luminosity LHC.
 Een chemisch maatpak voor alzheimermedicijnen
Een chemisch maatpak voor alzheimermedicijnen- Bindmiddelvrij titanosilicaat van het type MWW voor selectieve en duurzame epoxidatie van propyleen
- Vooruitgang met mRNA-medicijnen
- Synthese van een zeldzaam metaalcomplex van lachgas opent nieuwe perspectieven voor
- Wat zijn de belangrijkste chemische elementen die worden aangetroffen in cellen in de biologie?
- Een grote vulkaanuitbarsting schudde Deception Island 3, 980 jaar geleden
- Welke menselijke activiteiten hebben een negatief effect op de oceaan?
- Ice Caps Smeltende feiten
- Groeiende dode zone bevestigd door onderwaterrobots in de Golf van Oman
- Gegevens uit de ruimte die worden gebruikt om luchtvervuiling en de impact ervan op de gezondheid in kaart te brengen
Hoofdlijnen
- Wat is de relatie tussen stikstofbasen en de genetische code?
- Dance-gerelateerde wetenschapsprojecten
- Wat is een gen,
- Hoe maak je een 3D-model van de dikke darm
- Wat is het eindproduct van fotosynthese?
- Rechtbank vindt het goed om een soort uil te doden om het effect op andere uilen te zien
- Door klimaat beïnvloede veranderingen in bloei, vruchtvorming heeft ook invloed op de vogelstand, activiteiten
- Verschillende soorten microscopen en hun gebruik
- Chimpansees die het huis verlaten stellen het ouderschap uit






 Studie kijkt nauwkeuriger naar ondergrondse watersignalen van Mars
Studie kijkt nauwkeuriger naar ondergrondse watersignalen van Mars- Onderzoekers bedienen in het laboratorium gekweekte hartcellen op afstand
- Internationale lancering ingesteld voor streamingdienst Disney+
- Hoe te berekenen 2/3 van een nummer
- Astronomen verzamelen lichtvingerafdrukken om mysteries van de kosmos te onthullen
- Hawaii vulkaan stuurt meer lava, zwavelgas in gemeenschappen
- Wetenschappers ontdekken bewijs van vroege menselijke innovatie, evolutionaire tijdlijn terugdringen
- Biogefunctionaliseerd keramiek voor herstel van schedelbotdefecten - in vivo onderzoek
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
