Wetenschap
Chipontwerp vermindert drastisch de energie die nodig is om met licht te rekenen
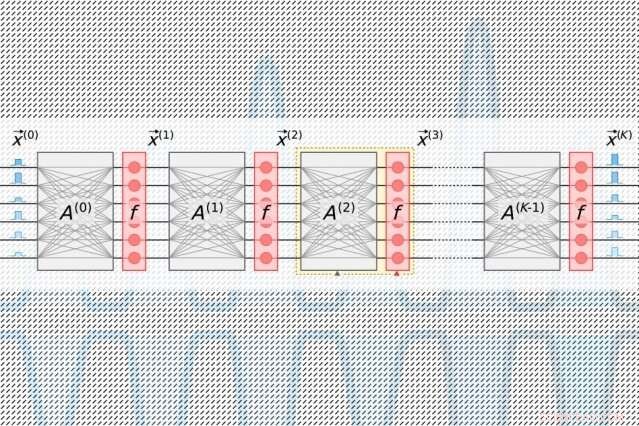
Een nieuw fotonisch chipontwerp vermindert drastisch de energie die nodig is om met licht te rekenen, met simulaties die suggereren dat het optische neurale netwerken 10 miljoen keer efficiënter kan uitvoeren dan zijn elektrische tegenhangers. Krediet:MIT Nieuws
MIT-onderzoekers hebben een nieuwe "fotonische" chip ontwikkeld die licht gebruikt in plaats van elektriciteit - en daarbij relatief weinig stroom verbruikt. De chip zou kunnen worden gebruikt om enorme neurale netwerken miljoenen keren efficiënter te verwerken dan de klassieke computers van vandaag.
Neurale netwerken zijn modellen voor machinaal leren die veel worden gebruikt voor taken als identificatie van robotobjecten, natuurlijke taalverwerking, Drug ontwikkeling, medische beeldvorming, en het aandrijven van zelfrijdende auto's. Nieuwe optische neurale netwerken, die optische verschijnselen gebruiken om de berekening te versnellen, kunnen veel sneller en efficiënter werken dan hun elektrische tegenhangers.
Maar naarmate traditionele en optische neurale netwerken complexer worden, ze eten tonnen kracht op. Om dat probleem aan te pakken, onderzoekers en grote technologiebedrijven, waaronder Google, IBM, en Tesla - hebben "AI-versnellers, "gespecialiseerde chips die de snelheid en efficiëntie van het trainen en testen van neurale netwerken verbeteren.
Voor elektrische chips, inclusief de meeste AI-versnellers, er is een theoretische minimumlimiet voor het energieverbruik. Onlangs, MIT-onderzoekers zijn begonnen met het ontwikkelen van fotonische versnellers voor optische neurale netwerken. Deze chips presteren orden van grootte efficiënter, maar ze vertrouwen op een aantal omvangrijke optische componenten die hun gebruik beperken tot relatief kleine neurale netwerken.
In een paper gepubliceerd in Fysieke beoordeling X , MIT-onderzoekers beschrijven een nieuwe fotonische versneller die gebruikmaakt van compactere optische componenten en optische signaalverwerkingstechnieken, om zowel het stroomverbruik als het chipgebied drastisch te verminderen. Dat stelt de chip in staat om op te schalen naar neurale netwerken die enkele ordes van grootte groter zijn dan zijn tegenhangers.
Gesimuleerde training van neurale netwerken op de MNIST-dataset voor beeldclassificatie suggereert dat de versneller in theorie neurale netwerken meer dan 10 miljoen keer onder de limiet voor energieverbruik van traditionele op elektriciteit gebaseerde versnellers kan verwerken en ongeveer 1, 000 keer onder de limiet van fotonische versnellers. De onderzoekers werken nu aan een prototype-chip om de resultaten experimenteel te bewijzen.
"Mensen zijn op zoek naar technologie die buiten de fundamentele grenzen van energieverbruik kan rekenen, " zegt Ryan Hamerly, een postdoc in het Research Laboratory of Electronics. "Fotonische versnellers zijn veelbelovend... maar onze motivatie is om een [fotonische versneller] te bouwen die kan opschalen tot grote neurale netwerken."
Praktische toepassingen voor dergelijke technologieën zijn onder meer het verminderen van het energieverbruik in datacenters. "Er is een groeiende vraag naar datacenters voor het runnen van grote neurale netwerken, en het wordt steeds meer rekenkundig onhandelbaar naarmate de vraag groeit, " zegt co-auteur Alexander Sludds, een afgestudeerde student in het Research Laboratory of Electronics. Het doel is "om te voldoen aan de computationele vraag met neurale netwerkhardware ... om het knelpunt van energieverbruik en latentie aan te pakken."
Samen met Sludds en Hamerly op het papier zijn:co-auteur Liane Bernstein, een RLE-afgestudeerde student; Marin Soljacic, een MIT-hoogleraar natuurkunde; en Dirk Englund, een MIT universitair hoofddocent elektrotechniek en informatica, een onderzoeker in RLE, en hoofd van het Quantum Photonics Laboratory.
Compact ontwerp
Neurale netwerken verwerken gegevens door vele rekenlagen met onderling verbonden knooppunten, genaamd "neuronen, " om patronen in de gegevens te vinden. Neuronen ontvangen invoer van hun stroomopwaartse buren en berekenen een uitvoersignaal dat naar neuronen verder stroomafwaarts wordt gestuurd. Aan elke invoer wordt ook een "gewicht, " een waarde gebaseerd op het relatieve belang ervan voor alle andere invoer. Naarmate de gegevens zich "dieper" door lagen verspreiden, het netwerk leert steeds complexere informatie. Uiteindelijk, een uitvoerlaag genereert een voorspelling op basis van de berekeningen door de lagen heen.
Alle AI-versnellers zijn bedoeld om de energie te verminderen die nodig is om gegevens te verwerken en te verplaatsen tijdens een specifieke lineaire algebrastap in neurale netwerken, genaamd "matrix vermenigvuldiging." Daar, neuronen en gewichten worden gecodeerd in afzonderlijke tabellen met rijen en kolommen en vervolgens gecombineerd om de output te berekenen.
In traditionele fotonische versnellers, gepulseerde lasers gecodeerd met informatie over elk neuron in een laag stromen in golfgeleiders en door bundelsplitsers. De resulterende optische signalen worden ingevoerd in een raster van vierkante optische componenten, genaamd "Mach-Zehnder-interferometers, " die zijn geprogrammeerd om matrixvermenigvuldiging uit te voeren. De interferometers, die zijn gecodeerd met informatie over elk gewicht, gebruik signaalinterferentietechnieken die de optische signalen en gewichtswaarden verwerken om een output voor elk neuron te berekenen. Maar er is een schaalprobleem:voor elk neuron moet er één golfgeleider zijn en, voor elk gewicht, er moet één interferometer zijn. Omdat het aantal gewichten kwadraat met het aantal neuronen, die interferometers nemen veel onroerend goed in beslag.
"Je realiseert je snel dat het aantal inputneuronen nooit groter kan zijn dan 100 of zo, omdat je niet zoveel componenten op de chip kunt passen, "zegt Hamerly. "Als je fotonische versneller niet meer dan 100 neuronen per laag kan verwerken, dan maakt het het moeilijk om grote neurale netwerken in die architectuur te implementeren."
De chip van de onderzoekers is gebaseerd op een compactere, energiezuinig "opto-elektronisch" schema dat gegevens codeert met optische signalen, maar gebruikt "gebalanceerde homodyne detectie" voor matrixvermenigvuldiging. Dat is een techniek die een meetbaar elektrisch signaal produceert na berekening van het product van de amplitudes (golfhoogten) van twee optische signalen.
Lichtpulsen gecodeerd met informatie over de input- en outputneuronen voor elke neurale netwerklaag - die nodig zijn om het netwerk te trainen - stromen door een enkel kanaal. Afzonderlijke pulsen gecodeerd met informatie over hele rijen gewichten in de matrixvermenigvuldigingstabel stromen door afzonderlijke kanalen. Optische signalen die de neuron- en gewichtsgegevens dragen, waaieren uit naar het raster van homodyne-fotodetectoren. De fotodetectoren gebruiken de amplitude van de signalen om een uitgangswaarde voor elk neuron te berekenen. Elke detector voedt een elektrisch uitgangssignaal voor elk neuron in een modulator, die het signaal weer omzet in een lichtpuls. Dat optische signaal wordt de input voor de volgende laag, enzovoort.
Het ontwerp vereist slechts één kanaal per input- en outputneuron, en slechts zoveel homodyne fotodetectoren als er neuronen zijn, geen gewichten. Omdat er altijd veel minder neuronen zijn dan gewichten, dit bespaart veel ruimte, dus de chip kan opschalen naar neurale netwerken met meer dan een miljoen neuronen per laag.
De sweet spot vinden
Met fotonische versnellers, er is een onvermijdelijke ruis in het signaal. Hoe meer licht er in de chip komt, hoe minder ruis en hoe nauwkeuriger, maar dat wordt behoorlijk inefficiënt. Minder ingangslicht verhoogt de efficiëntie, maar heeft een negatieve invloed op de prestaties van het neurale netwerk. Maar er is een "sweet spot, "Bernstein zegt, dat minimaal optisch vermogen gebruikt met behoud van nauwkeurigheid.
Die goede plek voor AI-versnellers wordt gemeten in het aantal joule dat nodig is om een enkele bewerking van het vermenigvuldigen van twee getallen uit te voeren, zoals tijdens matrixvermenigvuldiging. Direct, traditionele versnellers worden gemeten in picojoules, of een biljoenste van een joule. Fotonische versnellers meten in attojoules, wat een miljoen keer efficiënter is.
In hun simulaties de onderzoekers ontdekten dat hun fotonische versneller kon werken met sub-attojoule-efficiëntie. "Er is een minimaal optisch vermogen dat je kunt sturen, voordat de nauwkeurigheid verloren gaat. De fundamentele limiet van onze chip is een stuk lager dan traditionele versnellers … en lager dan andere fotonische versnellers, ' zegt Bernstein.
Dit verhaal is opnieuw gepubliceerd met dank aan MIT News (web.mit.edu/newsoffice/), een populaire site met nieuws over MIT-onderzoek, innovatie en onderwijs.

Hoofdlijnen
- Hoe herstelt de huid?
- Bij voetbalsucces draait alles om vaardigheid:studeren
- Monniksparkieten vallen Mexico binnen
- Plasmamembraan: definitie, structuur en functie (met diagram)
- Het verschil tussen een sporofyt en gametofyt
- CRISPR-octrooioorlogen benadrukken het probleem van het verlenen van brede intellectuele eigendomsrechten voor technologie die publieke voordelen biedt
- Basiscelfuncties
- Cellen voelen en verkennen hun omgeving
- Neurale opnames van wilde vleermuizen onthullen een unieke organisatie van het middenhersenengebied voor het volgen en vangen van prooien
- Aan boord van het ISS, onderzoekers onderzoeken complex stofgedrag in plasma's

- Gebouwd licht kan de gezondheid verbeteren, voedsel, suggereert onderzoeker

- Eieren onthullen wat er met de hersenen kan gebeuren bij impact

- Natuurkundigen ontdekken nieuw effect in de interactie van plasma's met vaste stoffen

- Higgs-boson zoekt nieuwe fenomenen

 Polyethyleen Glycol Vs. Ethylene Glycol
Polyethyleen Glycol Vs. Ethylene Glycol- Een diploma belooft een beter leven, maar sociale mobiliteit heeft een keerzijde
- Vroeg waarschuwingssysteem voor aardbevingen breidt zich uit naar Oregon, Washington
- Onderzoekers schetsen nieuwe benadering voor het voorspellen van de vrijgaveprijzen van Bordeaux-wijnen
- Big data kunnen bestaande praktijken van politietoezicht versterken, studie toont
- Haldan Keffer Hartline
- Mede-oprichters Instagram nemen ontslag bij socialmediabedrijf
- Onderzoek:Toegenomen aanwezigheid van wetshandhavers op scholen verbetert de veiligheid niet
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
