Wetenschap
Deepfake audio heeft iets te vertellen:onderzoekers gebruiken vloeiende dynamiek om kunstmatige bedrieglijke stemmen te herkennen
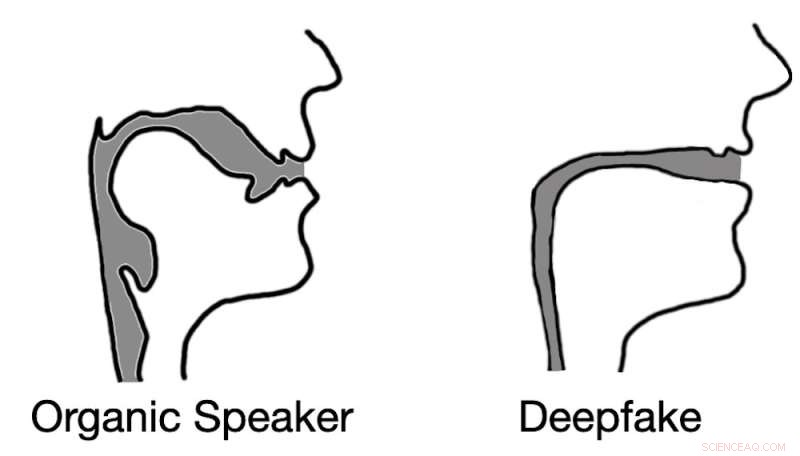
Deepfaked audio resulteert vaak in reconstructies van het stemkanaal die lijken op rietjes in plaats van biologische stemkanalen. Krediet:Logan Blue et al., CC BY-ND
Stel je het volgende scenario voor. Er gaat een telefoon. Een kantoormedewerker neemt op en hoort zijn baas in paniek zeggen dat ze vergat geld over te maken naar de nieuwe aannemer voordat ze voor de dag vertrok en hem nodig heeft om het te doen. Ze geeft hem de informatie over de overboeking en met het overgemaakte geld is de crisis afgewend.
De arbeider leunt achterover in zijn stoel, haalt diep adem en kijkt toe hoe zijn baas binnenkomt. De stem aan de andere kant van de lijn was niet zijn baas. In feite was het niet eens een mens. De stem die hij hoorde was die van een audiodeepfake, een door een machine gegenereerde audiosample die was ontworpen om precies zoals zijn baas te klinken.
Dergelijke aanvallen met behulp van opgenomen audio hebben al plaatsgevonden, en deepfakes voor conversatiegeluiden zijn misschien niet ver weg.
Deepfakes, zowel audio als video, waren alleen mogelijk met de ontwikkeling van geavanceerde machine learning-technologieën in de afgelopen jaren. Deepfakes hebben geleid tot een nieuw niveau van onzekerheid rond digitale media. Om deepfakes te detecteren, hebben veel onderzoekers zich gericht op het analyseren van visuele artefacten - kleine glitches en inconsistenties - gevonden in videodeepfakes.
Audiodeepfakes vormen mogelijk een nog grotere bedreiging, omdat mensen vaak verbaal communiceren zonder video, bijvoorbeeld via telefoongesprekken, radio en spraakopnamen. Deze spraakcommunicatie vergroot de mogelijkheden voor aanvallers om deepfakes te gebruiken aanzienlijk.
Om audiodeepfakes te detecteren, hebben wij en onze onderzoekscollega's aan de Universiteit van Florida een techniek ontwikkeld die de akoestische en vloeiende dynamische verschillen meet tussen stemsamples die organisch zijn gemaakt door menselijke luidsprekers en die welke synthetisch door computers zijn gegenereerd.
Organische versus synthetische stemmen
Mensen vocaliseren door lucht over de verschillende structuren van het stemkanaal te persen, inclusief stemplooien, tong en lippen. Door deze structuren te herschikken, verandert u de akoestische eigenschappen van uw stemkanaal, waardoor u meer dan 200 verschillende geluiden of fonemen kunt creëren. De menselijke anatomie beperkt echter fundamenteel het akoestische gedrag van deze verschillende fonemen, wat resulteert in een relatief klein aantal correcte geluiden voor elk.
Daarentegen worden audiodeepfakes gemaakt door eerst een computer te laten luisteren naar audio-opnames van een gerichte slachtofferspreker. Afhankelijk van de exacte gebruikte technieken, moet de computer mogelijk slechts 10 tot 20 seconden audio beluisteren. Deze audio wordt gebruikt om belangrijke informatie over de unieke aspecten van de stem van het slachtoffer te extraheren.
De aanvaller selecteert een zin voor de deepfake om uit te spreken en genereert vervolgens, met behulp van een aangepast tekst-naar-spraak-algoritme, een audiovoorbeeld dat klinkt alsof het slachtoffer de geselecteerde zin uitspreekt. Dit proces van het maken van een enkele deepfake-audiosample kan binnen enkele seconden worden voltooid, waardoor aanvallers mogelijk voldoende flexibiliteit hebben om de deepfake-stem in een gesprek te gebruiken.
Deepfakes van audio detecteren
De eerste stap in het onderscheiden van spraak geproduceerd door mensen van spraak gegenereerd door deepfakes, is begrijpen hoe het vocale kanaal akoestisch kan worden gemodelleerd. Gelukkig hebben wetenschappers technieken om in te schatten hoe iemand - of een wezen zoals een dinosaurus - zou klinken op basis van anatomische metingen van zijn vocale kanaal.
Wij deden het omgekeerde. Door veel van deze zelfde technieken om te keren, waren we in staat om een benadering te krijgen van het stemkanaal van een spreker tijdens een spraaksegment. Hierdoor konden we effectief in de anatomie kijken van de spreker die het audiovoorbeeld heeft gemaakt.
Vanaf hier veronderstelden we dat deepfake-audiosamples niet zouden worden beperkt door dezelfde anatomische beperkingen die mensen hebben. Met andere woorden, de analyse van deepfak-audiosamples simuleerde vormen van het stemkanaal die niet bij mensen voorkomen.
Onze testresultaten bevestigden niet alleen onze hypothese, maar onthulden ook iets interessants. Bij het extraheren van schattingen van het stemkanaal uit deepfake-audio, ontdekten we dat de schattingen vaak komisch incorrect waren. Het was bijvoorbeeld gebruikelijk dat deepfake-audio resulteerde in stemkanalen met dezelfde relatieve diameter en consistentie als een rietje, in tegenstelling tot menselijke stemkanalen, die veel breder en variabeler van vorm zijn.
Dit besef toont aan dat deepfake-audio, zelfs wanneer deze overtuigend is voor menselijke luisteraars, verre van te onderscheiden is van door mensen gegenereerde spraak. Door de anatomie te schatten die verantwoordelijk is voor het creëren van de waargenomen spraak, is het mogelijk om te bepalen of de audio door een persoon of een computer is gegenereerd.
Waarom dit belangrijk is
De wereld van vandaag wordt bepaald door de digitale uitwisseling van media en informatie. Alles, van nieuws tot entertainment tot gesprekken met dierbaren, gebeurt meestal via digitale uitwisselingen. Zelfs in hun kindertijd ondermijnen deepfake-video en -audio het vertrouwen dat mensen in deze uitwisselingen hebben, waardoor hun bruikbaarheid effectief wordt beperkt.
Als de digitale wereld een kritieke bron van informatie in het leven van mensen moet blijven, zijn effectieve en veilige technieken voor het bepalen van de bron van een audiofragment van cruciaal belang. + Verder verkennen
Valse spraakopnames identificeren
Dit artikel is opnieuw gepubliceerd vanuit The Conversation onder een Creative Commons-licentie. Lees het originele artikel. 
 Antibacteriële resistente ziekten onder vuur nemen
Antibacteriële resistente ziekten onder vuur nemen- Welke soorten aanpassingen moeten de woestijnbewoners maken om water te besparen?
- De multitasking-katalysator
- Proces voor het maken van papieren handdoeken
- Onderzoekers ontwikkelen nieuwe elektrodestructuur voor secundaire batterij in vaste toestand
- Ethiopië zou op een van 's werelds grootste onaangeboorde goudafzettingen kunnen zitten
- NASA vindt extreme regenval in tropische cycloon Kenanga
- Het voedsel gebruiken dat wordt verspild in New York City
- Luister naar de aarde die weer een wereldwijd temperatuurrecord verbreekt
- NASA ziet post-tropische cycloon Lorenzo Ierland treffen
Hoofdlijnen
- Fysische en chemische eigenschappen van lipiden
- Wetenschappers visualiseren de structuur van de belangrijkste DNA-reparatiecomponent met een bijna-atomaire resolutie
- Jagen op ooien met dikhoornschapen zou meer trofeerammen kunnen opleveren
- Wat gebeurt er met je cellen als je uitgedroogd bent?
- Verschil tussen triglyceriden en fosfolipiden
- Super Invader Tree treft Zuid, maar de vlooienkever kan een held zijn
- Naamloze soorten bacteriën een naam geven in het tijdperk van big data
- Onderzoekers voeren een nieuwe analyse van het tarwemicrobioom uit onder vier managementstrategieën
- Moleculaire tags onthullen hoe beschadigde lysosomen worden geselecteerd en gemarkeerd voor verwijdering
- NTSB:Tesla Autopilot, afgeleide bestuurder veroorzaakt dodelijke crash (update)

- Engineering team ontwikkelt scheepswerf op een schip

- Wetenschappers ontwikkelen een manier om veranderingen in het cardiovasculaire systeem van een persoon te volgen

- Facebook geeft ouders controle over wanneer kinderen app kunnen gebruiken

- FBI en Nigeria voeren onderzoek naar cybercriminaliteit op


 Waar is de ondermaan van de aarde?
Waar is de ondermaan van de aarde?- Een strategie voor het ontwerpen van elektrolyten voor het maken van batterijen van tweewaardig metaal
- Nieuw binair systeem met het door astronomen gevonden stralende effect
- Watchdog dringt er bij China op aan de invoer van illegaal hout aan banden te leggen
- Waarnemingen onthullen de aard van de chemisch eigenaardige ster HD 63401
- Wat zijn eco-plastics?
- Disney+-service een jaar verwijderd van streaming-shows
- De weg effenen:een versneller op een microchip
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
