Wetenschap
Een diepgaande leertechniek om realtime lipsynchronisatie te genereren voor live 2D-animatie
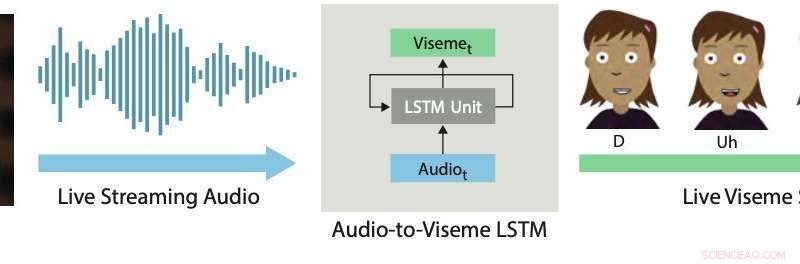
Realtime lipsynchronisatie. Onze deep learning-aanpak maakt gebruik van een LSTM om live streaming audio om te zetten in discrete visemes voor 2D-tekens. Krediet:Aneja &Li.
Live 2D-animatie is een vrij nieuwe en krachtige vorm van communicatie waarmee menselijke artiesten stripfiguren in realtime kunnen besturen terwijl ze interageren en improviseren met andere acteurs of leden van een publiek. Recente voorbeelden zijn onder meer Stephen Colbert die cartoongasten interviewde op De late show , Homer beantwoordt live inbelvragen van kijkers tijdens een segment van The Simpsons , Archer in gesprek met een live publiek op ComicCon, en de sterren van Disney's Ster versus de krachten van het kwaad en Mijn kleine pony het hosten van live chatsessies met fans via YouTube of Facebook Live.
Het produceren van realistische en effectieve live 2D-animaties vereist het gebruik van interactieve systemen die menselijke prestaties automatisch in realtime kunnen omzetten in animaties. Een belangrijk aspect van deze systemen is het bereiken van een goede lipsynchronisatie, wat in wezen betekent dat de monden van geanimeerde personages op de juiste manier bewegen tijdens het spreken, het nabootsen van de bewegingen waargenomen in de monden van artiesten.
Goede lipsynchronisatie kan live 2D-animatie overtuigender en krachtiger maken, waardoor geanimeerde personages de uitvoering realistischer kunnen belichamen. Omgekeerd, slechte lipsynchronisatie doorbreekt meestal de illusie van personages als live deelnemers aan een uitvoering of dialoog.
In een paper dat onlangs is voorgepubliceerd op arXiv, twee onderzoekers van Adobe Research en de Universiteit van Washington introduceerden een op deep learning gebaseerd interactief systeem dat automatisch live lipsynchronisatie genereert voor gelaagde 2D-geanimeerde karakters. Het door hen ontwikkelde systeem maakt gebruik van een lange-kortetermijngeheugen (LSTM)-model, een terugkerend neuraal netwerk (RNN) architectuur vaak toegepast op taken die betrekking hebben op het classificeren of verwerken van gegevens, evenals het maken van voorspellingen.
"Aangezien spraak het dominante onderdeel is van bijna elke live-animatie, wij geloven dat het meest kritieke probleem dat op dit gebied moet worden aangepakt, live lipsynchronisatie is, wat inhoudt dat de spraak van een acteur wordt omgezet in overeenkomstige mondbewegingen (d.w.z. viseme-reeks) in het geanimeerde personage. In dit werk, we richten ons op het creëren van hoogwaardige lipsynchronisatie voor live 2D-animatie, " Wilmot Li en Deepali Aneja, de twee onderzoekers die het onderzoek hebben uitgevoerd, vertelde TechXplore via e-mail.
Li is hoofdwetenschapper bij Adobe Research met een Ph.D. in de informatica die uitgebreid onderzoek heeft gedaan naar onderwerpen op het snijvlak van computergraphics en mens-computerinteractie. Aneja, anderzijds, is momenteel bezig met het afronden van een Ph.D. in computerwetenschappen aan de Universiteit van Washington, waar ze deel uitmaakt van het Graphics and Imaging Lab.
Het door Li en Aneja ontwikkelde systeem gebruikt een eenvoudig LSTM-model om streaming audio-invoer om te zetten in een overeenkomstige viseme-reeks met 24 frames per seconde, met een latentie van minder dan 200 milliseconden. Met andere woorden, hun systeem zorgt ervoor dat de lippen van een geanimeerd personage op dezelfde manier bewegen als die van een menselijke gebruiker die in realtime spreekt, met minder dan 200 milliseconden vertraging tussen de stem en de lipbeweging.
"In dit werk, we leveren twee bijdragen:het identificeren van de juiste functieweergave en netwerkconfiguratie om state-of-the-art resultaten te bereiken voor live 2D-lipsynchronisatie en het bedenken van een nieuwe augmentatiemethode voor het verzamelen van trainingsgegevens voor het model, " legden Li en Aneja uit.
"Voor het met de hand schrijven van lipsynchronisatie, professionele animators nemen stilistische beslissingen over de specifieke keuze van visemes en de timing en het aantal overgangen. Als resultaat, het trainen van een enkel 'algemeen' model is waarschijnlijk niet voldoende voor de meeste toepassingen, " zeiden Li en Aneja. Verder, het verkrijgen van gelabelde lipsynchronisatiegegevens om deep learning-modellen te trainen kan zowel duur als tijdrovend zijn. Professionele animators kunnen vijf tot zeven uur werk per minuut spraak besteden aan het met de hand schrijven van viseme-reeksen. Zich bewust van deze beperkingen, Li en Aneja ontwikkelden een methode die sneller en effectiever trainingsgegevens kan genereren.
Om hun LSTM-model effectiever te trainen, Li en Aneja introduceerden een nieuwe techniek die handgeschreven trainingsgegevens aanvult met behulp van audio time warping. Deze procedure voor gegevensvergroting zorgde voor een goede lipsynchronisatie, zelfs bij het trainen van hun model op een kleine gelabelde dataset.
Om de effectiviteit van hun interactieve systeem bij het produceren van lipsynchronisatie in realtime te evalueren, de onderzoekers vroegen menselijke kijkers om de kwaliteit van live-animaties die door hun model worden aangedreven, te beoordelen met die geproduceerd met commerciële 2D-animatietools. Ze ontdekten dat de meeste kijkers de lipsynchronisatie prefereerden die door hun benadering werd gegenereerd boven die van andere technieken.
"We hebben ook de wisselwerking tussen lipsynchronisatiekwaliteit en de hoeveelheid trainingsgegevens onderzocht, en we ontdekten dat onze methode voor gegevensvergroting de uitvoer van het model aanzienlijk verbetert, " zeiden Li en Aneja. "In het algemeen, we kunnen redelijke resultaten produceren met slechts 15 minuten met de hand geschreven lipsynchronisatiegegevens."
interessant, de onderzoekers ontdekten dat hun LSTM-model verschillende lipsynchronisatiestijlen kan verwerven op basis van de gegevens waarop het is getraind, terwijl het ook goed generaliseert over een breed scala aan sprekers. Onder de indruk van de bemoedigende resultaten van het model, Adobe besloot een versie ervan te integreren in zijn Adobe Character Animator-software, uitgebracht in het najaar van 2018.
"Nauwkeurig, lipsynchronisatie met lage latentie is belangrijk voor bijna alle live animatie-instellingen, en onze menselijke beoordelingsexperimenten laten zien dat onze techniek een verbetering is van bestaande state-of-the-art 2-D lip sync-engines, waarvan de meeste offline verwerking vereisen, " zeiden Li en Aneja. Dus, de onderzoekers zijn van mening dat hun werk directe praktische implicaties heeft voor zowel live als niet-live 2D-animatieproductie. De onderzoekers zijn niet op de hoogte van eerder 2D-lipsynchronisatiewerk met vergelijkbare uitgebreide vergelijkingen met commerciële tools.
In hun recente studie, Li en Aneja waren in staat om enkele van de belangrijkste technische uitdagingen aan te gaan die verband houden met de ontwikkeling van technieken voor live 2D-animatie. Eerst, ze demonstreerden een nieuwe methode om artistieke regels voor 2D-lipsynchronisatie te coderen met behulp van RNN's, die in de toekomst nog verder kunnen worden verbeterd.
De onderzoekers zijn van mening dat er veel meer mogelijkheden zijn om moderne machine learning-technieken toe te passen om 2D-animatieworkflows te verbeteren. "Zo ver, een uitdaging was het gebrek aan trainingsgegevens, wat duur is om te verzamelen. Echter, zoals we in dit werk laten zien, er kunnen manieren zijn om gebruik te maken van gestructureerde gegevens en automatische bewerkingsalgoritmen (bijv. dynamische tijdvervorming) om het nut van handgemaakte animatiegegevens te maximaliseren, ' zeiden Li en Aneja.
Hoewel de door de onderzoekers voorgestelde data-augmentatiestrategie de vereisten voor trainingsgegevens aanzienlijk kan verminderen voor modellen die zijn ontworpen om realtime lipsynchronisatie te produceren, het met de hand animeren van voldoende lipsynchronisatie-inhoud om nieuwe modellen te trainen vereist nog steeds veel werk en inspanning. Volgens Li en Aneja, echter, Het is misschien niet nodig om een heel model helemaal opnieuw te trainen voor elke nieuwe lipsynchronisatiestijl die het tegenkomt.
De onderzoekers zijn geïnteresseerd in het verkennen van strategieën voor fijnafstemming waarmee animators het model kunnen aanpassen aan verschillende stijlen met een veel kleinere hoeveelheid gebruikersinvoer. "Een verwant idee is om direct een lipsynchronisatiemodel te leren dat expliciet afstembare stilistische parameters bevat. Hoewel dit misschien een veel grotere trainingsdataset vereist, het potentiële voordeel is een model dat algemeen genoeg is om een reeks lipsynchronisatiestijlen te ondersteunen zonder extra training, ', aldus de onderzoekers.
interessant, in hun experimenten, de onderzoekers merkten op dat het eenvoudige kruis-entropieverlies dat ze gebruikten om hun model te trainen, niet nauwkeurig de meest relevante perceptuele verschillen tussen lipsynchronisatiesequenties weerspiegelde. Specifieker, ze ontdekten dat bepaalde discrepanties (bijv. het missen van een overgang of het vervangen van een viseem met gesloten mond door een viseem met open mond) zijn veel meer voor de hand liggend dan andere. "We denken dat het ontwerpen of leren van een perceptueel gebaseerd verlies in toekomstig onderzoek kan leiden tot verbeteringen in het resulterende model, ' zeiden Li en Aneja.
© 2019 Wetenschap X Netwerk
 De zaak van de ontbrekende diamanten
De zaak van de ontbrekende diamanten- Gevolgen van massale afsterving van koraal op riffen in de Indische Oceaan onthuld
- Lood terugwinnen, plastic, en zwavelzuur uit gebruikte autobatterijen
- Portugal worstelt om uit de as van zijn dodelijkste vuur te herrijzen
- Onderzoekers ontrafelen mysteries van de binnenste kern van de aarde
Hoofdlijnen
- Pan-Europese bemonsteringscampagne werpt licht op de enorme diversiteit van zoetwaterplankton
- Welke gebeurtenis volgt DNA-replicatie in een celcyclus?
- Hoe de lengte van DNA-fragmenten
- VS keuren herstelplan voor Mexicaanse wolven goed
- Studie vindt dat black box-methoden die door biologen worden gebruikt, waarschijnlijk het aantal nieuwe soorten overschatten
- Wat is interfase, metafase en anafase?
- Uitbreiding tonijnquota stap achteruit voor instandhouding
- The Stages of the Human Decomposition Process
- Waarom zijn we gewelddadig?
- Zelfrijdende autoservice in Frisco, Texas, starten in juli

- Uber verlaat Zuidoost-Azië en trekt zich terug uit de wereldwijde markten

- Een mensachtige planner waarmee robots objecten in een rommelige omgeving kunnen bereiken
- De Chinese provincie Hainan stopt met de verkoop van auto's op fossiele brandstoffen in 2030

- poorten, Zuckerberg werkt samen aan nieuw onderwijsinitiatief


 Hubbles op de eerste rij wanneer sterrenstelsels botsen
Hubbles op de eerste rij wanneer sterrenstelsels botsen- Herziening van de aardbeving in Kobe en de variaties van de atmosferische radonconcentratie
- De effecten van bioaccumulatie op het ecosysteem
- Nieuwe core-shell-katalysator voor ethanolbrandstofcellen
- Dronken noedels of Pad Kee Mao? Taal is belangrijk op etnische menu's
- Nieuwe mastodontsoort ontdekt in Californië
- Deepfake-video's in een oogwenk detecteren
- Cellen gebruiken concentratiegradiënten als kompas
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
