Wetenschap
Onderzoek naar het zelfaandachtsmechanisme achter op BERT gebaseerde architecturen
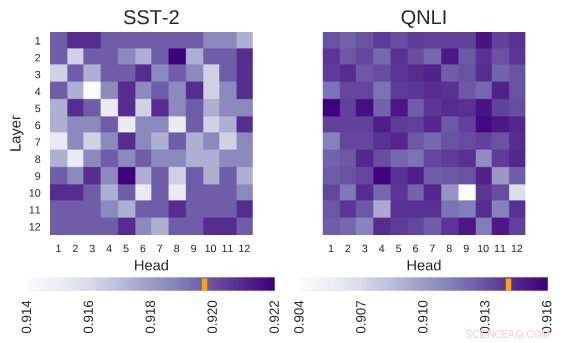
Onderzochte BERT-architectuur heeft de architectuur van 12 lagen bij 12 koppen. Elke cel in deze figuur toont de prestatie van BERT als de bijbehorende kop is uitgeschakeld. Donkere kleuren duiden op hogere prestaties, en witte cellen geven hoofden aan zonder welke de prestaties van BERT afnemen. Stanford Sentiment Treebank (SST-2):Er zijn meerdere heads die informatie coderen die nodig is voor de taak. Vraag Natural Language Inference (QNLI):De meeste koppen verbeteren de algehele prestatie wanneer ze zijn uitgeschakeld. Krediet:Kovaleva et al.
BERT, een op transformatoren gebaseerd model dat wordt gekenmerkt door een uniek zelfaandachtsmechanisme, is tot nu toe een geldig alternatief gebleken voor terugkerende neurale netwerken (RNN's) bij het aanpakken van natuurlijke taalverwerkingstaken (NLP). Ondanks hun voordelen, tot dusver, zeer weinig onderzoekers hebben deze op BERT gebaseerde architecturen diepgaand bestudeerd, of probeerden de redenen achter de effectiviteit van hun zelfaandachtsmechanisme te begrijpen.
Zich bewust van deze leemte in de literatuur, onderzoekers van het Text Machine Lab for Natural Language Processing van de University of Massachusetts Lowell hebben onlangs een onderzoek uitgevoerd naar de interpretatie van zelfaandacht, het meest vitale onderdeel van BERT-modellen. De hoofdonderzoeker en senior auteur van deze studie waren Olga Kovaleva en Anna Rumshisky, respectievelijk. Hun paper is vooraf gepubliceerd op arXiv en zal worden gepresenteerd op de EMNLP 2019-conferentie, suggereert dat een beperkt aantal aandachtspatronen wordt herhaald over verschillende BERT-subcomponenten, hint naar hun over-parametrisering.
"BERT is een recent model dat een doorbraak heeft gemaakt in de NLP-gemeenschap, het overnemen van de leaderboards voor meerdere taken. Geïnspireerd door deze recente trend, we waren nieuwsgierig om te onderzoeken hoe en waarom het werkt, " vertelde het team van onderzoekers aan TechXplore via e-mail. "We hoopten een verband te vinden tussen zelfaandacht, het belangrijkste onderliggende mechanisme van de BERT, en taalkundig interpreteerbare relaties binnen de gegeven invoertekst."
BERT-gebaseerde architecturen hebben een lagenstructuur, en elk van zijn lagen bestaat uit zogenaamde "koppen". Om het model te laten functioneren, elk van deze koppen is getraind om een specifiek type informatie te coderen, en draagt zo op zijn eigen manier bij aan het totale model. In hun studie hebben de onderzoekers analyseerden de informatie die door deze individuele hoofden werd gecodeerd, gericht op zowel de kwantiteit als de kwaliteit.
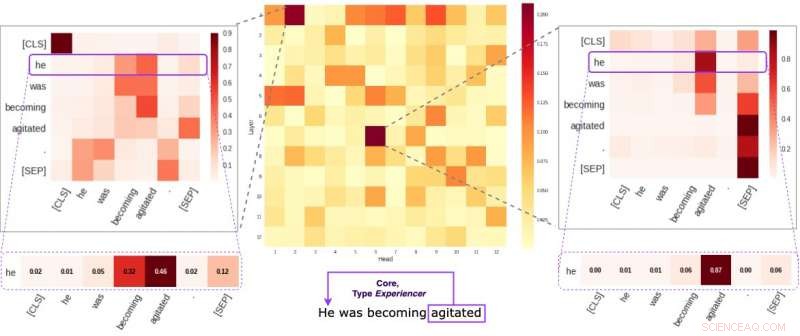
Elke cel in de middelste figuur geeft weer hoe individuele hoofden (gemiddeld) aandacht besteden aan semantische kernverbindingen binnen een bepaalde zin. We hebben twee specifieke hoofden geïdentificeerd die de neiging hebben om semantische informatie meer te coderen dan de andere. De twee afbeeldingen aan de zijkanten laten zien hoe deze twee koppen gewichten toekennen aan individuele woorden binnen een willekeurige zin van onze dataset. Krediet:Kovaleva et al.
"Onze methodologie was gericht op het onderzoeken van individuele hoofden en de aandachtspatronen die ze produceerden, " legden de onderzoekers uit. "In wezen, we probeerden de vraag te beantwoorden:"Als BERT een enkel woord van een zin codeert, schenkt het aandacht aan de andere woorden op een manier die zinvol is voor mensen?"
De onderzoekers voerden een reeks experimenten uit met zowel voorgetrainde basismodellen als verfijnde BERT-modellen. Dit stelde hen in staat om tal van interessante observaties te verzamelen met betrekking tot het zelfaandachtsmechanisme dat de kern vormt van op BERT gebaseerde architecturen. Bijvoorbeeld, ze merkten op dat een beperkt aantal aandachtspatronen vaak wordt herhaald over verschillende hoofden, wat suggereert dat BERT-modellen overgeparametriseerd zijn.
"We ontdekten dat BERT de neiging heeft om overgeparametriseerd te worden, en er is veel redundantie in de informatie die het codeert, " zeiden de onderzoekers. "Dit betekent dat de computationele voetafdruk van het trainen van zo'n groot model niet goed gerechtvaardigd is."
Een andere interessante bevinding verzameld door het team van onderzoekers van de Universiteit van Massachusetts Lowell is dat, afhankelijk van de taak die door een BERT-model wordt aangepakt, het willekeurig uitschakelen van enkele koppen kan leiden tot een verbetering, in plaats van een daling, qua prestaties. In aanvulling, de onderzoekers identificeerden geen linguïstische patronen die van bijzonder belang zijn bij het bepalen van de prestaties van BERT bij downstreamtaken.
"Het interpreteerbaar maken van deep learning is belangrijk voor zowel fundamenteel als toegepast onderzoek, en we zullen in deze richting blijven werken, " zeiden de onderzoekers. "Er zijn onlangs nieuwe op BERT gebaseerde modellen uitgebracht, en we zijn van plan onze methodologie uit te breiden om ze ook te onderzoeken."
© 2019 Wetenschap X Netwerk

Hoofdlijnen
- Transcriptiefactoren en genexpressie heroverwegen
- Negen verdwaalde olifanten geëlektrocuteerd in Botswana
- Het verschil tussen glycolyse en gluconeogenese
- Verschillende soorten brood Mold
- Nadelen en voordelen van een HPLC
- Anatomie en fysiologie van een synapsenstructuur
- Coevolution: definitie, soorten en voorbeelden
- Hoe menselijke Wang-cellen te observeren onder een lichtmicroscoop
- Drones gebruiken om gewasschade door wilde zwijnen in te schatten
- Thuiswerken tijdens de coronaviruspandemie zorgt voor nieuwe cyberbeveiligingsbedreigingen

- GM om ongeveer 4 te ontslaan, 000 loontrekkende:bron

- Tesla vermindert aantal voorraadkleuren om productie te stroomlijnen

- Honda roept 1,2 miljoen voertuigen terug met gevaarlijke airbags

- VAE versoepelt beperkingen, maar de meeste populaire apps zijn nog steeds geblokkeerd


 Echtparen die het niet eens zijn over spaar- en investeringsbeslissingen, hebben twee keer zoveel kans om te scheiden
Echtparen die het niet eens zijn over spaar- en investeringsbeslissingen, hebben twee keer zoveel kans om te scheiden- Een nieuw platform voor geïntegreerde fotonica
- Door vrouwen gerunde start-ups gehinderd door vooringenomenheid onder mannelijke investeerders:onderzoek
- Doorbraak kan goedkopere infraroodcamera's mogelijk maken
- Demonstratie van onconventionele transversale thermo-elektrische generatie
- Sextant
- Geüpgraded waterrisicofilter kan de reactie van bedrijven op waterrisico's helpen transformeren
- Video:Aanpak van de effecten van klimaatverandering op de bessenteelt in Europa
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | German | Dutch | Danish | Norway | Portuguese | Swedish |

-
Wetenschap © https://nl.scienceaq.com
