Wetenschap
Een convolutioneel netwerk om emotionele annotaties uit te lijnen en te voorspellen
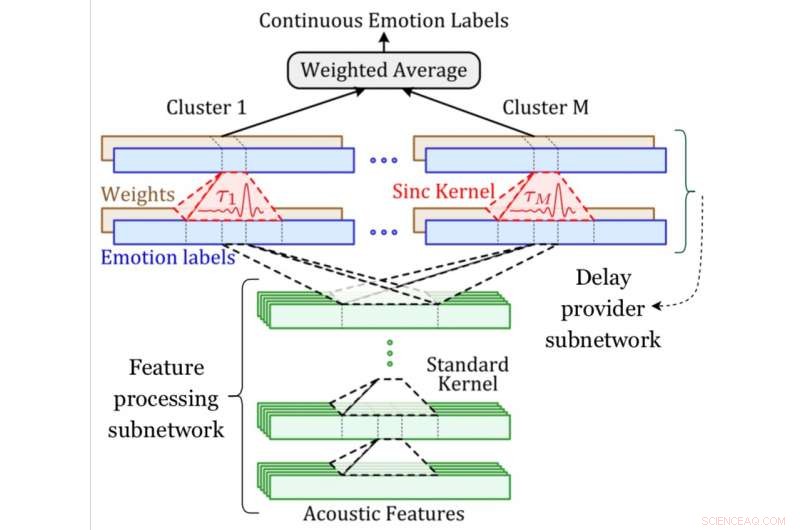
Een systeemdiagram van het MDS-netwerk. Krediet:Khorram, McInnis &Provost.
Machine learning-modellen die menselijke emoties kunnen herkennen en voorspellen, zijn de afgelopen jaren steeds populairder geworden. Om ervoor te zorgen dat de meeste van deze technieken goed presteren, echter, de gegevens die worden gebruikt om ze te trainen, worden eerst geannoteerd door menselijke proefpersonen. Bovendien, emoties veranderen voortdurend in de tijd, wat het annoteren van video's of spraakopnamen bijzonder uitdagend maakt, vaak resulterend in discrepanties tussen labels en opnames.
Om deze beperking aan te pakken, onderzoekers van de Universiteit van Michigan hebben onlangs een nieuw convolutioneel neuraal netwerk ontwikkeld dat tegelijkertijd op een end-to-end manier emotie-annotaties kan uitlijnen en voorspellen. Ze presenteerden hun techniek, een multi-delay sync (MDS) netwerk genoemd, in een paper gepubliceerd in IEEE Transacties op Affective Computing .
"Emotie varieert continu in de tijd; het ebt en vloeit in onze gesprekken" Emily Mower Provost, een van de onderzoekers die het onderzoek heeft uitgevoerd, vertelde TechXplore. "In engineering, we gebruiken vaak continue beschrijvingen van emoties om te meten hoe emoties variëren. Ons doel wordt dan om deze continue metingen vanuit spraak te voorspellen. Maar er is een vangst. Een van de grootste uitdagingen bij het werken met continue beschrijvingen van emoties is dat het vereist dat we labels hebben die continu variëren in de tijd. Dit wordt gedaan door teams van menselijke annotators. Echter, mensen zijn geen machines."
Zoals Mower Provost verder uitlegt, menselijke annotators kunnen soms beter afgestemd zijn op bepaalde emotionele signalen (bijv. gelach), maar mis de betekenis achter andere signalen (bijv. een geërgerde zucht). Naast dit, mensen kunnen enige tijd nodig hebben om een opname te verwerken, en daarom, hun reacties op emotionele signalen worden soms vertraagd. Als resultaat, continue emotielabels kunnen veel variatie bieden en zijn soms niet goed uitgelijnd met spraak in de gegevens.
In hun studie hebben Mower Provost en haar collega's hebben deze uitdagingen rechtstreeks aangepakt, gericht op twee continue metingen van emotie:positiviteit (valentie) en energie (activering/opwinding). Ze introduceerden het multi-delay sync-netwerk, een nieuwe methode om een verkeerde uitlijning tussen spraak en continue annotaties aan te pakken die anders reageert op verschillende soorten akoestische signalen.
"Tijdcontinue dimensionale beschrijvingen van emoties (bijv. opwinding, valentie) gedetailleerde informatie geven over zowel korte-tijdveranderingen als langetermijntrends in emotie-expressie, "Soheil Khorram, een andere onderzoeker die bij het onderzoek betrokken was, vertelde TechXplore. "Het belangrijkste doel van onze studie was om een automatisch emotieherkenningssysteem te ontwikkelen dat in staat is om de tijdcontinue dimensionale emoties van spraaksignalen te schatten. Dit systeem zou een aantal echte toepassingen kunnen hebben op verschillende gebieden, waaronder mens-computerinteractie, e-learning, marketing, gezondheidszorg, amusement en recht."
Het convolutionele netwerk ontwikkeld door Mower Provost, Khorram en hun collega's hebben twee belangrijke componenten, één voor emotievoorspelling en één voor afstemming. De component emotievoorspelling is een veelgebruikte convolutionele architectuur die is getraind om de relatie tussen akoestische kenmerken en emotielabels te identificeren.
De uitlijningscomponent, anderzijds, is de nieuwe laag die door de onderzoekers is geïntroduceerd (d.w.z. de vertraagde synchronisatielaag), die een leerbare tijdverschuiving toepast op een akoestisch signaal. De onderzoekers compenseerden de variatie in vertragingen door meerdere van deze lagen in te bouwen.
"Een belangrijke uitdaging bij het ontwikkelen van automatische systemen voor het voorspellen van tijd-continue emotielabels uit spraak is dat deze labels over het algemeen niet gesynchroniseerd zijn met de ingevoerde spraak, " legde Khorram uit. "Dit is voornamelijk te wijten aan vertragingen veroorzaakt door reactietijd, wat inherent is aan menselijke evaluaties. In tegenstelling tot andere benaderingen, ons convolutionele neurale netwerk is in staat om labels gelijktijdig uit te lijnen en te voorspellen op een end-to-end manier. Multi-delay sync-netwerk maakt gebruik van traditionele signaalverwerkingsconcepten (d.w.z. sync-filtering) in moderne deep learning-architecturen om het reactievertragingsprobleem aan te pakken."
De onderzoekers evalueerden hun techniek in een reeks experimenten met behulp van twee openbaar beschikbare datasets, namelijk de RECOLA en de SEWA datasets. Ze ontdekten dat het compenseren van de reactievertragingen van annotators tijdens het trainen van hun emotieherkenningsmodel leidde tot significante verbeteringen in de nauwkeurigheid van de emotieherkenning van het model.
Ze merkten ook op dat de reactievertragingen van annotators bij het definiëren van continue emotielabels doorgaans niet meer dan 7,5 seconden bedragen. Eindelijk, hun bevindingen suggereren dat delen van spraak die gelach bevatten over het algemeen kleinere vertragingscomponenten vereisen in vergelijking met die gekenmerkt door andere emotionele signalen. Met andere woorden, het is vaak gemakkelijker voor annotators om emotielabels te definiëren in spraaksegmenten die gelach bevatten.
"Emotie is overal en staat centraal in onze communicatie, Mower Provost zei. "We bouwen robuuste en generaliseerbare emotieherkenningssystemen zodat mensen deze informatie gemakkelijk kunnen openen en gebruiken. Een deel van dit doel wordt bereikt door het creëren van algoritmen die effectief gebruik kunnen maken van grote externe gegevensbronnen, zowel gelabeld als niet, en door effectief de natuurlijke dynamiek te modelleren die deel uitmaakt van hoe we emotioneel communiceren. Het andere deel wordt bereikt door alle complexiteit die inherent is aan de labels zelf te begrijpen."
Hoewel Mower Provost, Khorram en hun collega's pasten hun techniek toe op emotieherkenningstaken, het kan ook worden gebruikt om andere machine learning-toepassingen te verbeteren waarin input en output niet perfect op elkaar zijn afgestemd. In hun toekomstige werk, de onderzoekers zijn van plan door te gaan met het onderzoeken van manieren waarop emotielabels die door menselijke annotators zijn geproduceerd, efficiënt in gegevens kunnen worden geïntegreerd.
"We hebben een synchronisatiefilter gebruikt om de Dirac-deltafunctie te benaderen en de vertragingen te compenseren. andere functies, zoals Gaussiaans en driehoekig, kan ook worden gebruikt in plaats van de sync-kernel, " Khorram zei. "Ons toekomstige werk zal het effect onderzoeken van het gebruik van verschillende soorten kernels die de Dirac-deltafunctie kunnen benaderen. Aanvullend, in dit artikel hebben we ons gericht op de spraakmodaliteit om continue emotionele annotaties te voorspellen, terwijl het voorgestelde synchronisatienetwerk met meerdere vertragingen ook een redelijke modelleringstechniek is voor andere invoermodaliteiten. Een ander toekomstplan is om de prestaties van het voorgestelde netwerk te evalueren ten opzichte van andere fysiologische en gedragsmodaliteiten zoals:video, lichaamstaal en EEG."
© 2019 Wetenschap X Netwerk
 Nieuwe computationele screeningbenadering identificeert potentiële elektrolyten in vaste toestand
Nieuwe computationele screeningbenadering identificeert potentiële elektrolyten in vaste toestand- Zelfassemblerende homo-oligomeren van cyclische eiwitten
- Wanneer chemie met groen licht nabootst wat er in het leven gebeurt
- Welke handschoenen moeten worden gebruikt voor het omgaan met aceton?
- Cryo-EM onthult kritisch eiwitmodificerend complex en potentieel medicijndoelwit
- Betere neerslagvoorspellingen tot enkele uren van tevoren
- Onderzoek naar de hoeveelheid kwik en stof uit de Sahara op de Canarische Eilanden
- Leven op een luchtloze aarde
- Hebben extreme schommelingen in zuurstof, geen geleidelijke stijging, de Cambrische explosie veroorzaken?
- Soorten schimmels Planten
Hoofdlijnen
- Domme mensen zijn verrassend zelfverzekerd
- Twee soorten fagocyten
- Je lichaam aan: een hittegolf
- De oorsprong van genen voor het maken van bloemen
- Plantenziekte bestrijden bij warme temperaturen houdt voedsel op tafel
- Enzymactiviteit in appels
- Celstructuurdefinities
- Wat is Tastile Stimulation?
- Cat Chromosome-informatie
- PSA, Fiat Chrysler onthult fusie van gelijken

- Nieuwe zender maakt gebruik van ultrasnelle frequentie-hopping en data-encryptie om te voorkomen dat signalen worden onderschept

- Slimme algoritmen stimuleren de planning

- Op weg naar duurzame blockchains

- Facebook biedt $ 100 miljoen om door virus getroffen nieuwsmedia te helpen


 Voorstanders van de Chesapeake Bay juichen de passage van de federale natuurbeschermingswet toe
Voorstanders van de Chesapeake Bay juichen de passage van de federale natuurbeschermingswet toe- Fossiel dat ontbrekende evolutionaire schakel vult, vernoemd naar professoren van de Universiteit van Chicago
- Studie onderzoekt op welke zoekopdrachten autokopers klikken
- Welke vogels nestelen op de grond?
- Een vliegtuigcrash voorkomen - onderzoek helpt piloten om te trainen voor aerodynamische stallen
- De toekomst van de aarde wordt geschreven in het snel smeltende Groenland
- Veranderingen in droge gebieden met toekomstige klimaatverandering
- 360 graden, 180 seconden:nieuwe techniek versnelt analyse van gewaskenmerken
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
