Wetenschap
Gegevensanalyse slepen en neerzetten

Voor jaren, onderzoekers van MIT en Brown University hebben een interactief systeem ontwikkeld waarmee gebruikers gegevens kunnen slepen en neerzetten op elk touchscreen, inclusief smartphones en interactieve whiteboards. Nutsvoorzieningen, ze hebben een tool toegevoegd die direct en automatisch machine learning-modellen genereert om voorspellingstaken op die gegevens uit te voeren. Krediet:Melanie Gonick
In de Ijzeren man films, Tony Stark gebruikt een holografische computer om 3D-gegevens in het niets te projecteren, manipuleer ze met zijn handen, en oplossingen vinden voor zijn superheldenproblemen. In dezelfde ader, onderzoekers van MIT en Brown University hebben nu een systeem ontwikkeld voor interactieve gegevensanalyse dat op touchscreens draait en waarmee iedereen, niet alleen geniale, miljardair, playboy-filantropen - pakken problemen uit de echte wereld aan.
Voor jaren, de onderzoekers hebben een interactief datawetenschappelijk systeem ontwikkeld genaamd Northstar, die in de cloud draait maar een interface heeft die elk touchscreen-apparaat ondersteunt, inclusief smartphones en grote interactieve whiteboards. Gebruikers voeden de systeemdatasets, en manipuleren, combineren, en extraheer functies op een gebruiksvriendelijke interface, met hun vingers of een digitale pen, trends en patronen te ontdekken.
In een paper die wordt gepresenteerd op de ACM SIGMOD-conferentie, de onderzoekers beschrijven een nieuw onderdeel van Northstar, genaamd VDS voor "virtual data scientist, " die direct machine learning-modellen genereert om voorspellingstaken uit te voeren op hun datasets. Artsen, bijvoorbeeld, kan het systeem gebruiken om te voorspellen welke patiënten meer kans hebben op bepaalde ziekten, terwijl ondernemers misschien de verkoop willen voorspellen. Als u een interactief whiteboard gebruikt, iedereen kan ook realtime samenwerken.
Het doel is om datawetenschap te democratiseren door het eenvoudig maken van complexe analyses, snel en nauwkeurig.
"Zelfs een coffeeshopeigenaar die geen kennis heeft van datawetenschap, zou in staat moeten zijn om zijn verkoop in de komende weken te voorspellen om erachter te komen hoeveel koffie hij moet kopen, " zegt co-auteur en lange tijd Northstar-projectleider Tim Kraska, een universitair hoofddocent elektrotechniek en computerwetenschappen bij MIT's Computer Science and Artificial Intelligence Laboratory (CSAIL) en medeoprichter van het nieuwe Data System en AI Lab (DSAIL). "In bedrijven die datawetenschappers hebben, er is veel heen en weer tussen datawetenschappers en niet-experts, dus we kunnen ze ook in één ruimte brengen om samen analyses te doen."
VDS is gebaseerd op een steeds populairder wordende techniek in kunstmatige intelligentie, genaamd geautomatiseerde machine-learning (AutoML), waarmee mensen met beperkte kennis van datawetenschap AI-modellen kunnen trainen om voorspellingen te doen op basis van hun datasets. Momenteel, de tool leidt de DARPA D3M Automatic Machine Learning-competitie, die elke zes maanden beslist over de best presterende AutoML-tool.
Deelnemen aan Kraska op het papier zijn:eerste auteur Zeyuan Shang, een afgestudeerde student, en Emanuel Zgraggen, een postdoc en hoofdbijdrager van Northstar, zowel van EECS, CSAIL, en DSAIL; Benedetto Buratti, Yeounoh Chung, Philip Eichmann, en Eli Upfal, heel bruin; en Carsten Binnig die onlangs van Brown naar de Technische Universiteit van Darmstadt in Duitsland verhuisde.

Krediet:Melanie Gonick
Een "onbegrensd canvas" voor analyses
Het nieuwe werk bouwt voort op jarenlange samenwerking op Northstar tussen onderzoekers van MIT en Brown. Ruim vier jaar, de onderzoekers hebben talloze artikelen gepubliceerd waarin componenten van Northstar worden beschreven, inclusief de interactieve interface, operaties op meerdere platforms, resultaten versnellen, en studies over gebruikersgedrag.
Northstar begint als een blanco, witte interface. Gebruikers uploaden datasets in het systeem, die verschijnen in een "datasets"-vak aan de linkerkant. Alle gegevenslabels zullen automatisch een apart vak 'kenmerken' hieronder invullen. Er is ook een "operators"-box die verschillende algoritmen bevat, evenals de nieuwe AutoML-tool. Alle gegevens worden opgeslagen en geanalyseerd in de cloud.
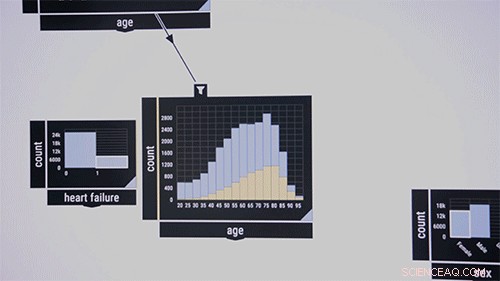
De onderzoekers demonstreren het systeem graag op een openbare dataset met informatie over patiënten op de intensive care. Denk aan medische onderzoekers die het samen voorkomen van bepaalde ziekten in bepaalde leeftijdsgroepen willen onderzoeken. Ze slepen en neerzetten in het midden van de interface een patrooncontrole-algoritme, die in eerste instantie wordt weergegeven als een lege doos. Als invoer, ze gaan naar de doos met ziektekenmerken gelabeld, zeggen, "bloed, " "besmettelijk, " en "metabool." Percentages van die ziekten in de dataset verschijnen in het vak. ze slepen de "leeftijd"-functie naar de interface, die een staafdiagram van de leeftijdsverdeling van de patiënt weergeeft. Door een lijn tussen de twee vakken te trekken, worden ze met elkaar verbonden. Door leeftijdsgroepen te omcirkelen, het algoritme berekent onmiddellijk het gelijktijdig voorkomen van de drie ziekten onder de leeftijdsgroep.
"Het is als een grote, onbegrensd canvas waar je alles kunt indelen hoe je wilt, " zegt Zgraggen, wie is de belangrijkste uitvinder van de interactieve interface van Northstar. "Vervolgens, je kunt dingen aan elkaar koppelen om complexere vragen over je data te creëren."
AutoML benaderen
Met VDS, gebruikers kunnen nu ook voorspellende analyses uitvoeren op die gegevens door modellen op maat te maken voor hun taken, zoals gegevensvoorspelling, afbeelding classificatie, of het analyseren van complexe grafiekstructuren.
Met behulp van het bovenstaande voorbeeld, zeggen dat de medische onderzoekers willen voorspellen welke patiënten mogelijk een bloedziekte hebben op basis van alle kenmerken in de dataset. Ze slepen en neerzetten "AutoML" uit de lijst met algoritmen. Het zal eerst een lege doos produceren, maar met een "doel"-tabblad, waaronder ze de "bloed" -functie zouden laten vallen. Het systeem vindt automatisch de best presterende machine learning-pijplijnen, weergegeven als tabbladen met constant bijgewerkte nauwkeurigheidspercentages. Gebruikers kunnen het proces op elk moment stoppen, verfijn de zoekopdracht, en de foutenpercentages van elk model onderzoeken, structuur, berekeningen, en andere dingen.
Krediet:Melanie Gonick
Volgens de onderzoekers is VDS is de snelste interactieve AutoML-tool tot nu toe, Met dank, gedeeltelijk, naar hun aangepaste 'schattingsengine'. De engine zit tussen de interface en de cloudopslag. De hefboomwerking van de engine maakt automatisch verschillende representatieve voorbeelden van een dataset die progressief kunnen worden verwerkt om binnen enkele seconden hoogwaardige resultaten te produceren.
"Samen met mijn co-auteurs heb ik twee jaar besteed aan het ontwerpen van VDS om na te bootsen hoe een datawetenschapper denkt, "Shang zegt, wat betekent dat het onmiddellijk identificeert welke modellen en voorverwerkingsstappen het wel of niet moet uitvoeren voor bepaalde taken, gebaseerd op verschillende gecodeerde regels. Het kiest eerst uit een grote lijst van die mogelijke machine learning-pijplijnen en voert simulaties uit op de voorbeeldset. Daarbij, het onthoudt resultaten en verfijnt de selectie. Na het leveren van snelle geschatte resultaten, het systeem verfijnt de resultaten in de backend. Maar de uiteindelijke cijfers liggen meestal heel dicht bij de eerste benadering.
"Voor het gebruik van een voorspeller, u wilt geen vier uur wachten om uw eerste resultaten terug te krijgen. Je wilt nu al zien wat er aan de hand is en, als u een fout ontdekt, je kunt het meteen corrigeren. Dat is normaal gesproken niet mogelijk in een ander systeem, " zegt Kraska. De eerdere gebruikersstudie van de onderzoekers, in feite, "laat zien dat op het moment dat u het geven van resultaten aan gebruikers uitstelt, ze beginnen de betrokkenheid bij het systeem te verliezen."
De onderzoekers evalueerden de tool op 300 real-world datasets. In vergelijking met andere geavanceerde AutoML-systemen, VDS' approximations were as accurate, but were generated within seconds, which is much faster than other tools, which operate in minutes to hours.
Volgende, the researchers are looking to add a feature that alerts users to potential data bias or errors. Bijvoorbeeld, to protect patient privacy, sometimes researchers will label medical datasets with patients aged 0 (if they do not know the age) and 200 (if a patient is over 95 years old). But novices may not recognize such errors, which could completely throw off their analytics.
"If you're a new user, you may get results and think they're great, " Kraska says. "But we can warn people that there, in feite, may be some outliers in the dataset that may indicate a problem."
Dit verhaal is opnieuw gepubliceerd met dank aan MIT News (web.mit.edu/newsoffice/), een populaire site met nieuws over MIT-onderzoek, innovatie en onderwijs.
 Moleculaire dynamische simulatie werpt nieuw licht op de vorming van methaanhydraat
Moleculaire dynamische simulatie werpt nieuw licht op de vorming van methaanhydraat- Algoritme voorspelt de samenstelling van nieuwe materialen
- Van identificatie tot chemische vingerafdruk voor explosieven in forensisch onderzoek
- Nieuw organisch plastic materiaal zorgt ervoor dat elektronica bij extreme temperaturen kan functioneren zonder in te boeten aan prestaties
- Stoichiometrie maken Easy
- Onderzoekers gebruiken satellietbeelden om het grondwatergebruik in de centrale vallei van Californië in kaart te brengen
- Experts op het gebied van risicocommunicatie analyseren visuele reacties op afbeeldingen met tornadowaarschuwingen
- WWF slaat alarm over kolossale olievlek in de Zwarte Zee
- Onderzoek toont zes decennia aan verandering in planktongemeenschappen
- VN-chef dringt aan op actie om rampen klimaatverandering af te wenden
Hoofdlijnen
- Het grote structurele voordeel Eukaryoten hebben over prokaryoten
- De verschillen tussen fotosynthese en ademhaling
- Wat doet een skelet bewegen?
Het skelet is het starre raamwerk dat een lichaam zijn algemene vorm geeft, maar op zichzelf is het niet in staat tot beweging. Wat een skelet doet bewegen is de samentrekking en ontspanning van spieren die ermee verbon
- Een win-win voor gevlekte uilen en bosbeheer
- Feiten over de menselijke schedel voor kinderen
- Onderzoek bevestigt het:we worden echt dommer
- Hoe de droogrot Serpula lacrymans zich aanpasten aan een nieuwe ecologische habitat
- Voordelen en nadelen van Hydrostatic Skeleton
- Nieuwe suikerglasfilm gebruikt virussen om schadelijke bacteriën in voedsel te doden
- Woede als Zambia belasting op internetbellen aankondigt

- AI-technieken die worden gebruikt om de gezondheid en veiligheid van batterijen te verbeteren

- Drones betere voeten geven zodat ze kunnen rusten op nabijgelegen structuren

- Zelfrijdende bezorgrobots van Amazon gaan naar Californië

- Onderzoeker blogde over tijdelijke oplossing voor Apple OS-updates USB-beperkte modus


 Mannen van kleur vermijden openbare plaatsen uit angst voor betrokkenheid bij strafrechtelijke agenten
Mannen van kleur vermijden openbare plaatsen uit angst voor betrokkenheid bij strafrechtelijke agenten- Video:Bijen leiden de weg naar de toekomst van de landbouw
- Old Faithfuls geologisch hart onthuld
- Quantum RAM:de grote vragen modelleren met de zeer kleine
- Onderzoek naar de milieu-impact van conflicten
- De cryo-elektronenmicroscopiestructuur van huntingtine
- De ongelijkheid in blootstelling aan luchtvervuiling blijft bestaan in Massachusetts
- Succesvolle lancering van raket uit ballon op grote hoogte maakt ruimte toegankelijker voor microsatellieten
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
