Wetenschap
Brain-geïnspireerde AI inspireert inzichten over de hersenen (en vice versa)
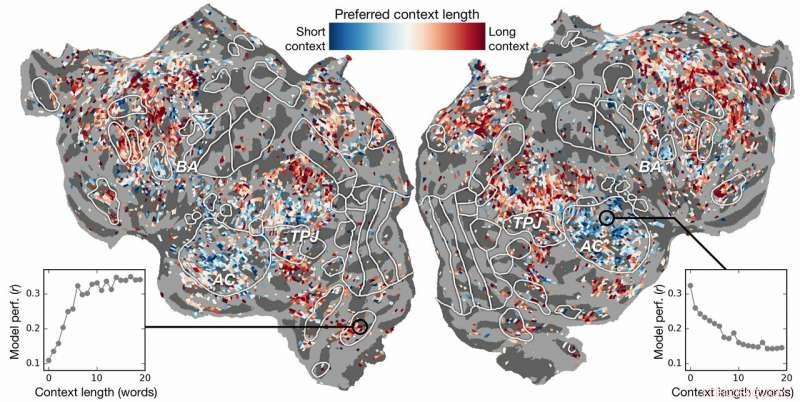
Voorkeur voor contextlengte over de cortex. Een index van de voorkeur voor contextlengte wordt berekend voor elke voxel in één onderwerp en geprojecteerd op het corticale oppervlak van dat onderwerp. Voxels die in blauw worden weergegeven, kunnen het beste worden gemodelleerd met behulp van korte context, terwijl rode voxels het best kunnen worden gemodelleerd met een lange context. Krediet:Huth-lab, UT Austin
Kan kunstmatige intelligentie (AI) ons helpen begrijpen hoe de hersenen taal begrijpen? Kan neurowetenschap ons helpen begrijpen waarom AI en neurale netwerken effectief zijn in het voorspellen van menselijke waarneming?
Onderzoek van Alexander Huth en Shailee Jain van de Universiteit van Texas in Austin (UT Austin) suggereert dat beide mogelijk zijn.
In een paper gepresenteerd op de 2018 Conference on Neural Information Processing Systems (NeurIPS), de wetenschappers beschreven de resultaten van experimenten die kunstmatige neurale netwerken gebruikten om met grotere nauwkeurigheid dan ooit tevoren te voorspellen hoe verschillende gebieden in de hersenen op specifieke woorden reageren.
"Als woorden in ons hoofd komen, we vormen ons een idee van wat iemand tegen ons zegt, en we willen begrijpen hoe dat tot ons komt in de hersenen, " zei Hut, assistent-professor Neurowetenschappen en Computerwetenschappen aan de UT Austin. "Het lijkt alsof er systemen voor zouden moeten zijn, maar praktisch, zo werkt taal gewoon niet. Zoals alles in de biologie, het is heel moeilijk om terug te brengen tot een eenvoudige reeks vergelijkingen."
Het werk maakte gebruik van een type terugkerend neuraal netwerk genaamd lange korte termijn geheugen (LSTM), dat in zijn berekeningen de relaties van elk woord met wat eraan voorafging omvat om de context beter te bewaren.
"Als een woord meerdere betekenissen heeft, je leidt de betekenis van dat woord af voor die bepaalde zin, afhankelijk van wat eerder is gezegd, " zei Jaïn, een doctoraat student in Huth's lab aan de UT Austin. "Onze hypothese is dat dit zou leiden tot betere voorspellingen van hersenactiviteit omdat de hersenen om context geven."
Het klinkt vanzelfsprekend, maar decennialang hielden neurowetenschappelijke experimenten rekening met de reactie van de hersenen op individuele woorden zonder een idee te hebben van hun verband met reeksen woorden of zinnen. (Huth beschrijft het belang van het doen van "real-world neuroscience" in een paper van maart 2019 in de Journal of Cognitive Neuroscience .)
In hun werk, de onderzoekers voerden experimenten uit om te testen, en uiteindelijk voorspellen, hoe verschillende gebieden in de hersenen zouden reageren bij het luisteren naar verhalen (in het bijzonder, het nachtvlinder-radio-uurtje). Ze gebruikten gegevens die zijn verzameld van fMRI-machines (functionele magnetische resonantiebeeldvorming) die veranderingen in het bloedoxygenatieniveau in de hersenen vastleggen op basis van hoe actieve groepen neuronen zijn. Dit dient als correspondent voor waar taalconcepten worden "vertegenwoordigd" in de hersenen.
Met behulp van krachtige supercomputers in het Texas Advanced Computing Center (TACC), ze trainden een taalmodel met behulp van de LSTM-methode, zodat het effectief kon voorspellen welk woord zou komen - een taak die lijkt op Google auto-complete zoekopdrachten, waar de menselijke geest bijzonder bedreven in is.
"Bij het proberen om het volgende woord te voorspellen, dit model moet impliciet al die andere dingen leren over hoe taal werkt, " zei Hut, "zoals welke woorden de neiging hebben om andere woorden te volgen, zonder ooit daadwerkelijk toegang te hebben tot de hersenen of enige gegevens over de hersenen."
Op basis van zowel het taalmodel als de fMRI-gegevens, ze trainden een systeem dat kon voorspellen hoe de hersenen zouden reageren wanneer het elk woord in een nieuw verhaal voor de eerste keer hoort.
Eerdere inspanningen hadden aangetoond dat het mogelijk is om taalreacties in de hersenen effectief te lokaliseren. Echter, het nieuwe onderzoek toonde aan dat het toevoegen van het contextuele element - in dit geval tot 20 woorden die eerder kwamen - de voorspellingen van hersenactiviteit aanzienlijk verbeterde. Ze ontdekten dat hun voorspellingen zelfs verbeterden als er zo min mogelijk context werd gebruikt. Hoe meer context geboden, hoe beter de nauwkeurigheid van hun voorspellingen.
"Onze analyse toonde aan dat als de LSTM meer woorden bevat, dan wordt het beter in het voorspellen van het volgende woord, " zei Jaïn, "wat betekent dat het informatie moet bevatten van alle woorden uit het verleden."
Het onderzoek ging verder. Het onderzocht welke delen van de hersenen gevoeliger waren voor de hoeveelheid context die werd opgenomen. Ze vonden, bijvoorbeeld, dat concepten die lijken te zijn gelokaliseerd in de auditieve cortex minder afhankelijk waren van de context.
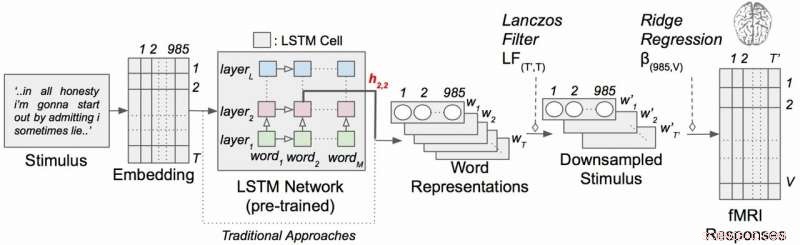
Contextueel taalcoderingsmodel met verhalende stimuli. Elk woord in het verhaal wordt eerst geprojecteerd in een 985-dimensionale inbeddingsruimte. Sequenties van woordrepresentaties worden vervolgens ingevoerd in een LSTM-netwerk dat vooraf is getraind als een taalmodel. Krediet:Huth-lab, UT Austin
"Als je het woord hond hoort, dit gebied maakt niet uit wat de 10 woorden daarvoor waren, het gaat gewoon reageren op het geluid van het woord hond", Hut legde uit.
Anderzijds, hersengebieden die te maken hebben met denken op een hoger niveau waren gemakkelijker te lokaliseren wanneer er meer context werd opgenomen. Dit ondersteunt theorieën over de geest en het taalbegrip.
"Er was een heel mooie overeenkomst tussen de hiërarchie van het kunstmatige netwerk en de hiërarchie van de hersenen, die we interessant vonden, ' zei Hut.
Natuurlijke taalverwerking - of NLP - heeft de afgelopen jaren grote vooruitgang geboekt. Maar als het gaat om het beantwoorden van vragen, natuurlijke gesprekken voeren, of het analyseren van de gevoelens in geschreven teksten, NLP heeft nog een lange weg te gaan. De onderzoekers denken dat hun door LSTM ontwikkelde taalmodel op deze gebieden kan helpen.
De LSTM (en neurale netwerken in het algemeen) werken door waarden in hoogdimensionale ruimte toe te wijzen aan individuele componenten (hier, woorden) zodat elk onderdeel kan worden gedefinieerd door zijn duizenden ongelijksoortige relaties met vele andere dingen.
De onderzoekers trainden het taalmodel door het tientallen miljoenen woorden uit Reddit-posts te geven. Hun systeem deed vervolgens voorspellingen voor hoe duizenden voxels (driedimensionale pixels) in de hersenen van zes proefpersonen zouden reageren op een tweede reeks verhalen die noch het model, noch de individuen eerder hadden gehoord. Omdat ze geïnteresseerd waren in de effecten van contextlengte en het effect van individuele lagen in het neurale netwerk, ze testten in wezen 60 verschillende factoren (20 lengtes van contextbehoud en drie verschillende laagdimensies) voor elk onderwerp.
Dit alles leidt tot rekenproblemen van enorme omvang, enorme hoeveelheden rekenkracht nodig hebben, geheugen, opslag, en gegevens ophalen. De middelen van TACC waren zeer geschikt voor het probleem. De onderzoekers gebruikten de Maverick-supercomputer, die zowel GPU's als CPU's bevat voor de computertaken, en Corral, een bron voor opslag en gegevensbeheer, om de gegevens te bewaren en te verspreiden. Door het probleem te parallelliseren over veel processors, ze waren in staat om het computationele experiment in weken in plaats van jaren uit te voeren.
"Om deze modellen effectief te ontwikkelen, je hebt veel trainingsgegevens nodig, Huth zei. "Dat betekent dat je elke keer dat je de gewichten wilt bijwerken, je hele dataset moet doorlopen. En dat is inherent erg traag als je geen parallelle middelen gebruikt zoals die bij TACC."
Als het ingewikkeld klinkt, wel het is.
Dit brengt Huth en Jain ertoe om een meer gestroomlijnde versie van het systeem te overwegen, waar in plaats van een taalvoorspellingsmodel te ontwikkelen en het vervolgens toe te passen op de hersenen, ze ontwikkelen een model dat de hersenreactie direct voorspelt. Ze noemen dit een end-to-end systeem en dat is waar Huth en Jain naartoe hopen te gaan in hun toekomstig onderzoek. Een dergelijk model zou zijn prestaties direct op hersenreacties verbeteren. Een verkeerde voorspelling van hersenactiviteit zou feedback geven aan het model en verbeteringen stimuleren.
"Als dit werkt, dan is het mogelijk dat dit netwerk tekst of intaketaal kan leren lezen op dezelfde manier als onze hersenen, "Zei Huth. "Stel je Google Translate voor, maar het begrijpt wat je zegt, in plaats van alleen een reeks regels te leren."
Met zo'n systeem, Huth gelooft dat het slechts een kwestie van tijd is voordat een systeem voor het lezen van gedachten dat hersenactiviteit in taal kan vertalen, haalbaar is. Ondertussen, ze krijgen door hun experimenten inzicht in zowel neurowetenschappen als kunstmatige intelligentie.
"Het brein is een zeer effectieve rekenmachine en het doel van kunstmatige intelligentie is om machines te bouwen die echt goed zijn in alle taken die een brein kan doen, "Zei Jain. "Maar, we begrijpen niet veel van de hersenen. Dus, we proberen kunstmatige intelligentie te gebruiken om eerst te vragen hoe de hersenen werken, en dan, op basis van de inzichten die we verkrijgen door deze verhoormethode, en door theoretische neurowetenschap, we gebruiken die resultaten om betere kunstmatige intelligentie te ontwikkelen.
"Het idee is om cognitieve systemen te begrijpen, zowel biologisch als kunstmatig, en om ze samen te gebruiken om betere machines te begrijpen en te bouwen."
 Hoe een schimmel het immuunsysteem kan verlammen
Hoe een schimmel het immuunsysteem kan verlammen- Op algen geïnspireerde polymeren verlichten de weg voor verbeterd nachtzicht
- Groene chemici vinden een manier om cashewnootdoppen om te zetten in zonnebrandcrème
- Door meniscus ondersteunde techniek produceert perovskiet PV-films met een hoog rendement
- Chemici ontwikkelen een raamwerk om een efficiënte synthese van informatierijke moleculen mogelijk te maken
- Planet markeert nieuwe hoogtepunten voor warmte, verontreinigende stoffen, zeeniveau in 2016:rapport
- Sicilië Etna hoger dan ooit na zes maanden activiteit
- We moeten de bescherming van het milieu versterken tijdens droogte - of we worden geconfronteerd met onomkeerbaar verlies
- Wetenschappers vinden potentiële magmabron in Italiaanse supervulkaan
- No-go-waarschuwing nu Japanse vulkaan voor het eerst in 250 jaar uitbarst
Hoofdlijnen
- Dierenartsen voeren de eerste bekende hersenoperatie uit om hydrocephalus bij pelsrobben te behandelen
- Experts:broederij in Idaho die is gebouwd om zalm te redden doodt ze
- Nieuwe Peruaanse vogelsoorten ontdekt door zijn gezang
- Studie verlicht genetische oorsprong van diversiteit in huidskleur
- Ocean meeting haalt meer dan $7 miljard op voor mariene bescherming
- Naarmate het klimaat warmer wordt, meer vogelnesten worden vernietigd in Finse landbouwgronden
- Insectencompound Oog versus Menselijk Oog
- Functies van menselijke organen
- Begrazing van vee schaadt leefgebied van reuzenpanda's
- Op condensatoren gebaseerde architectuur voor AI-hardwareversnellers
- Dokter voert eerste 5G-operatie uit in stap richting robotica-droom

- Intel lanceringsevenement luidt 9e generatie processors in

- Bijproduct van biodiesel helpt brandstof schoon te maken

- Digitale soevereiniteit:kan het Russische internet zich afsluiten van de rest van de wereld?


 Centimetermetingen op een Ruler
Centimetermetingen op een Ruler- Kan vacuümfysica worden onthuld door lasergestuurde microbellen?
- Eikenbomen in steden in het zuiden van de VS zijn natuurlijke stedelijke luchtfilters
- Hoe verandert deze blauwe bloementhee van kleur?
- Waarom is gedestilleerd water een goede controle voor wetenschappelijke projecten?
De belangrijkste reden waarom gedestilleerd water de beste keuze biedt voor gebruik in wetenschappelijke projecten is dat het inert is, wat betekent dat er na distil
- Tsunami onthult menselijke geluidsoverlast in Hawaiiaanse wateren
- VENu maakt het mogelijk om een neutrino-jager aan het werk te zien
- Genetische schakelaars bij kanker nader bekijken
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
