Wetenschap
Een evaluatie van de compromissen tussen nauwkeurigheid en efficiëntie van neurale taalmodellen
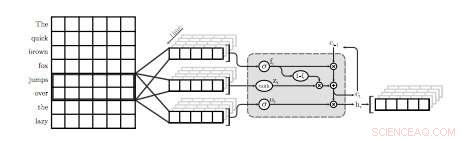
Een illustratie van de eerste QRNN-laag voor taalmodellering. In deze visualisatie een QRNN-laag met een venstergrootte van twee convolves en pools met behulp van inbeddingen van de invoer. Let op de afwezigheid van terugkerende gewichten. Krediet:Tang &Lin.
Een team van onderzoekers van de Universiteit van Waterloo in Canada heeft onlangs een onderzoek uitgevoerd naar de afwegingen tussen nauwkeurigheid en efficiëntie van neurale taalmodellen (NLM's) die specifiek worden toegepast op mobiele apparaten. In hun krant die voorgepubliceerd was op arXiv, de onderzoekers stelden ook een eenvoudige techniek voor om enige verwarring te herstellen, een maatstaf voor de prestaties van een taalmodel, met een verwaarloosbare hoeveelheid geheugen.
NLM's zijn taalmodellen op basis van neurale netwerken waarmee algoritmen de typische verdeling van woordreeksen kunnen leren en voorspellingen kunnen doen over het volgende woord in een zin. Deze modellen hebben een aantal handige toepassingen, bijvoorbeeld, slimmere softwaretoetsenborden voor mobiele telefoons of andere apparaten mogelijk maken.
"Neurale taalmodellen (NLM's) bestaan in een afwegingsruimte voor nauwkeurigheid en efficiëntie waar betere verwarring doorgaans ten koste gaat van grotere rekencomplexiteit, ' schreven de onderzoekers in hun paper. 'In een softwaretoetsenbordtoepassing op mobiele apparaten, dit vertaalt zich in een hoger stroomverbruik en een kortere batterijduur."
Wanneer toegepast op softwaretoetsenborden, NLM's kunnen leiden tot nauwkeurigere voorspelling van het volgende woord, waardoor gebruikers met een enkele tik het volgende woord in een bepaalde zin kunnen invoeren. Twee bestaande toepassingen die neurale netwerken gebruiken om deze functie te bieden, zijn SwiftKey1 en Swype2. Echter, deze toepassingen vereisen vaak veel vermogen om te functioneren, de batterijen van mobiele apparaten snel leegmaken.
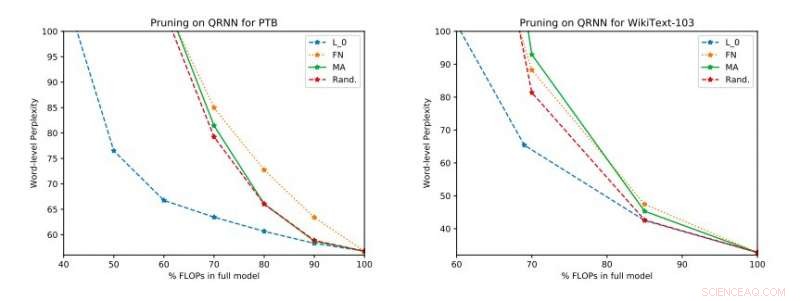
Volledige experimentele resultaten op Penn Treebank en WikiText-103. We illustreren de wisselwerking tussen verwarring en efficiëntie op de testset die is verkregen voordat de update met één rang werd toegepast. Krediet:Tang &Lin.
"Op basis van standaardstatistieken zoals verbijstering, neurale technieken vertegenwoordigen een vooruitgang in de state-of-the-art taalmodellering, " legden de onderzoekers uit in hun paper. "Betere modellen, echter, gaan ten koste van de computationele complexiteit, wat zich vertaalt in een hoger stroomverbruik. In de context van mobiele apparaten, energie-efficiëntie is, natuurlijk, een belangrijke optimalisatiedoelstelling."
Volgens de onderzoekers is NLM's zijn tot nu toe voornamelijk geëvalueerd in de context van beeldherkenning en het spotten van trefwoorden, terwijl de wisselwerking tussen nauwkeurigheid en efficiëntie in toepassingen voor natuurlijke taalverwerking (NLP) nog niet grondig is onderzocht. Hun studie richt zich op dit onontgonnen onderzoeksgebied, het uitvoeren van een evaluatie van NLM's en hun compromissen tussen nauwkeurigheid en efficiëntie op een Raspberry Pi.
"Onze empirische evaluaties houden rekening met zowel verbijstering als energieverbruik op een Raspberry Pi, waar we laten zien welke methoden het beste werkpunt voor verwarring en energieverbruik bieden, " zeiden de onderzoekers. "Op één werkpunt, een van de technieken kan een energiebesparing van 40 procent opleveren ten opzichte van de state-of-the-art [methoden] met slechts een relatieve toename van 17 procent in verwarring."
In hun studie hebben de onderzoekers evalueerden ook een aantal inferentietijdsnoeitechnieken op quasi-recurrente neurale netwerken (QRNN's). Uitbreiding van de bruikbaarheid van bestaande snoeimethoden voor trainingstijd naar QRNN's tijdens runtime, ze bereikten verschillende werkpunten binnen de afwegingsruimte voor nauwkeurigheid en efficiëntie. Om de prestaties te verbeteren met een kleine hoeveelheid geheugen, ze stelden voor om gewichtsupdates met één rang te trainen en op te slaan op de gewenste werkpunten.
© 2018 Tech Xplore
 Rijstwetenschappers vereenvoudigen de opname van stikstof in moleculen
Rijstwetenschappers vereenvoudigen de opname van stikstof in moleculen- Diepeutectische oplosmiddelen vervangen vervuilende industriële oplosmiddelen
- Nieuwe reactie maakt indoline-steigers beschikbaar voor farmaceutische ontwikkeling
- Polymeer gloeit omkeerbaar wit wanneer uitgerekt
- Flexibele en kosteneffectieve fabricage van op de natuur geïnspireerde structurele kleuren
- Deadlines kunnen effectief zijn bij het opbouwen van steun voor maatregelen tegen klimaatverandering
- Verbazingwekkende koeien zijn veelbelovend in baanbrekende duurzame voedselsystemen van de toekomst
- Zeedieren slaan koolstof op in de oceaan - kan de bescherming ervan de klimaatverandering helpen vertragen?
- Hoe vroeg komt de lente bij jou in de buurt? Er achter komen ...
- De richtlijnen voor drinkwater in de VS verschillen sterk van staat tot staat
Hoofdlijnen
- Zijn mannen gewelddadiger dan vrouwen?
- De toekomst zaaien? Ark conserven zeldzaam, bedreigde planten
- Endoplasmatisch reticulum (ruw en glad): structuur en functie (met diagram)
- Voorbeelden van genetische kenmerken
- Politieke instabiliteit en zwak bestuur leiden tot verlies van soorten, studie vondsten
- Wanneer citroenen je leven geven:Herpetofauna-aanpassing aan citrusboomgaarden in Belize
- Eiwit beëindigt opzettelijk de eigen synthese door de synthesemachinerie te destabiliseren - het ribosoom
- Mexico zegt dat de bedreigde vaquita-bruinvis in gevangenschap is gestorven
- Over de zes koninkrijken
- Phishing-succes gekoppeld aan incentives en vasthouden aan een effectieve strategie

- Elektrisch textiel verlicht een lamp wanneer uitgerekt

- Sociaal ondersteunende robot helpt kinderen met autisme bij het leren

- Studie gebruikt AI om niet-ontplofte bommen uit de oorlog in Vietnam te schatten
- Barr waarschuwt dat de tijd dringt voor bedrijven om encryptie te openen


 Onderzoekers ontwikkelen veiliger elektrolyten en gebruiken nieuwe technieken om ze te beoordelen
Onderzoekers ontwikkelen veiliger elektrolyten en gebruiken nieuwe technieken om ze te beoordelen- Hoeveelheid water in stamcellen kan zijn lot bepalen als vet of bot
- Natuurkundigen opgewonden door ontdekking van nieuwe vorm van materie, excitonium
- Math Fair Projects on Fibonacci Numbers
- Het zal moeilijk zijn, maar we kunnen de wereld voeden met plantaardig eiwit
- Tektonische platen zwakker dan eerder gedacht, zeggen wetenschappers
- 'S Werelds eerste afvuren van luchtademende elektrische boegschroef
- Het voorgestelde verbod van het VK kan belangrijke producten met microplastics missen
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
