Wetenschap
Google AI-onderzoeker kondigt Dataset Search aan

Krediet:CC0 Publiek Domein
Google, vanaf dag een, groot geworden door informatie te zoeken. Jaren later, Google heeft het serieus over datasets. Google lanceert een nieuwe zoekmachine om wetenschappers te helpen de datasets te vinden die ze nodig hebben.
Op woensdag, Google AI-onderzoeker Natasha Noy kondigde Google's lancering van Dataset Search aan. U krijgt nu eenvoudig toegang tot datasets, als je wetenschapper bent, of gewoon data "nerd" in een ander soort achtervolging, op zoek naar gegevens voor je werk en voor je verhalen en voor je intellectuele nieuwsgierigheid.
Het doel is om u meer van een enkele interface te bieden. Jon Fingas in Engadget bekeken hoe dit het zoeken naar gegevens ten goede kan komen.
"De tool geeft meer directe toegang tot data gepresenteerd in een open standaard die duidelijk maakt wie de info heeft gemaakt, hoe het is verzameld en hoe u het mag gebruiken. Je kon niet alleen klimaatgegevens opsporen voor een rapport, maar zorg ervoor dat het relevant en legaal is om te gebruiken."
Dit is een wereldwijde (zoals in internationale) push die in meerdere talen werkt met binnenkort ondersteuning voor extra talen. James Vincent in De rand citeerde Noy:"Ik denk dat het aantal repositories de afgelopen jaren is geëxplodeerd."
"Voer gewoon in waarnaar u op zoek bent en we zullen u naar de gepubliceerde dataset op de site van de repositoryprovider leiden, "zei ze. Momenteel, datasets en gerelateerde data zijn meestal verspreid over meerdere datarepository's en het kan zijn dat informatie over deze datasets niet gekoppeld of geïndexeerd is door zoekmachines. Voor de persoon die een zoekopdracht uitvoert, data discovery wordt op zijn best vervelend.
Ze zijn serieus voorstander van een ecosysteem waarin aanbieders van datasets zelf worden aangemoedigd, via richtlijnen die Google ontwikkelde, om hun gegevens te beschrijven "op een manier dat Google (en andere zoekmachines) de inhoud van hun pagina's beter kunnen begrijpen, " ze zei.
Voor hun aanpak hierbij gebruikten ze de open standaard schema.org. Op het verlanglijstje van Noy:dat alle datasetaanbieders achter deze gemeenschappelijke standaard gaan staan. Het is te hopen dat meer datarepositories de schema.org-standaard zullen gebruiken om hun datasets te beschrijven. Op die manier, zei Noyes, datasets maken deel uit van een 'robuust ecosysteem'.
"Een zoektool als deze is slechts zo goed als de metadata die data-uitgevers bereid zijn te verstrekken. We hopen dat velen van jullie de open standaarden gebruiken om je data te beschrijven, zodat onze gebruikers de gegevens kunnen vinden waarnaar ze op zoek zijn."
Jon Fingas in Engadget :"Het is op dit moment verre van een definitieve bron. Het is een begin, echter, en Google hoopt ongetwijfeld dat dit anderen zal aanmoedigen om hun openbare gegevens beter doorzoekbaar te maken."
En alsof dit alles nog niet genoeg was, Google zal een aantal wegen inslaan om het meeste uit data over data over data te halen.
Volgens De rand , Jeni Tennis, hoofd van het Open Data Instituut, zei idealiter dat Google zijn eigen dataset publiceert hoe Dataset Search wordt gebruikt. Ze zei dat Google een dataset over het zoeken naar datasets zou moeten publiceren die zou worden geïndexeerd door Dataset Search. voegde Vincent er aan toe. Hij citeerde haar:
"Gewoon begrijpen hoe mensen zoeken is belangrijk... wat voor soort termen ze gebruiken, hoe ze die uitdrukken, ", zegt Tennison. "Als we grip willen krijgen op hoe mensen naar data zoeken en deze toegankelijker willen maken, het zou geweldig zijn als Google zijn eigen gegevens hierover zou openen." Met andere woorden, hij voegde toe, Google zou een dataset over het zoeken naar datasets moeten publiceren die zou worden geïndexeerd door Dataset Search.
© 2018 Tech Xplore
 Hoe te gebruiken Natriumperboraat
Hoe te gebruiken Natriumperboraat- Waarom vormt water waterstofbruggen?
Er zijn twee verschillende chemische bindingen aanwezig in water. De covalente bindingen tussen de zuurstof en de waterstofatomen zijn het gevolg van het delen van de elektronen. Dit is wat de watermoleculen zel
- Hoe de dichtheid van water te verhogen
- Ontdekking van een nieuwe wet van fasescheiding
- Science Fair Project over het effect van koolzuurhoudende dranken op vlees
- De ontdekking van de zwaartekracht en de mensen die het hebben ontdekt
- Duiker filmt afvalland in de wateren van Bali
- Bloedzuigende insecten en insecten
- Studie helpt verklaren Groenlandse gletsjers varieerde kwetsbaarheid voor smelten
- Veranderende moesson veranderde vroege culturen in China, studie zegt:
Hoofdlijnen
- Het verschil tussen histon en nonhiston
- Hoe converteert ADP naar ATP?
- Noorse rechtbank verleent uitstel aan zeven wolven
- Hoe evolueert de mens?
- Uniek veldonderzoek levert eerste overzichtsfoto van diepzeevoedselwebben op
- Verschillende soorten brood Mold
- Fysische structuur van chromosomen
- Waarom stinkt de stinkplant?
- DNA versus RNA: wat zijn de overeenkomsten en verschillen? (met diagram)
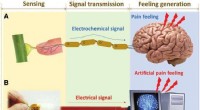
- Psychosensorische elektronische huidtechnologie voor toekomstige AI en humanoïde ontwikkeling
- Onderzoekers bedenken nieuwe methode om zelfkleurende ramen te maken

- Facebook om banen te maken, kredietadvertenties doorzoekbaar voor gebruikers in de VS

- Facebook-crisis noopt tot soul-searching in Silicon Valley

- Hoe een gloeilamp te laten werken met een batterij


 Microkrediet gebruiken om rijstopbrengst in Bangladesh te verhogen
Microkrediet gebruiken om rijstopbrengst in Bangladesh te verhogen- Onderzoekers volgen grondwaterlozingen in zoutvijvers
- Afbeelding:Mount Sharp fotobommen Mars Curiosity rover
- Muziek is essentieel voor de overdracht van etnobiologische kennis
- Visualisatie van het galactische centrum levert sterrenkracht
- Onderzoekers behalen kwantumvoordeel
- Verbetering van 3D-geprinte protheses en integratie van elektronische sensoren
- Wat is een totale zonsverduistering en waarom is deze zo ongewoon?
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Portuguese | Swedish | German | Dutch | Danish | Norway | Spanish |

-
Wetenschap © https://nl.scienceaq.com
