Wetenschap
Een lichtgewicht en nauwkeurig deep learning-model voor audiovisuele emotieherkenning
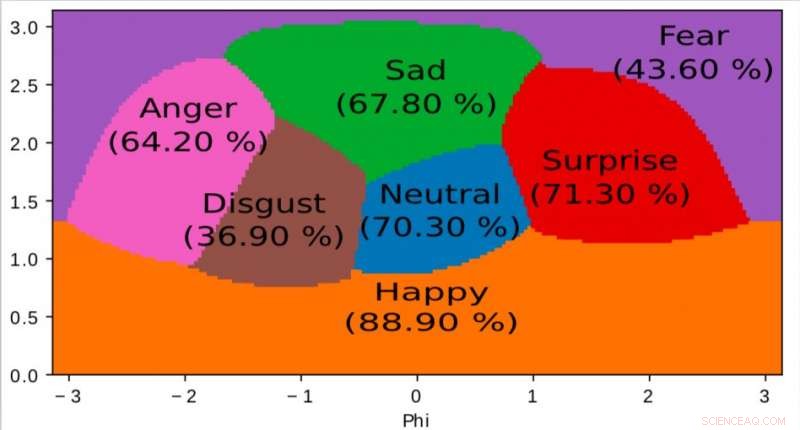
Een weergave van de interne ruimte geleerd door ons algoritme en gebruikt om emoties in kaart te brengen in een 2D continue ruimte. Het is interessant om op te merken dat zelfs als de trainingsgegevens alleen discrete emotielabels bevatten, het netwerk leert een continue ruimte, niet alleen om de emotionele toestand van mensen fijn te beschrijven, maar ook om emoties in relatie tot elkaar te positioneren. Deze ruimte vertoont sterke gelijkenis met de opwindingsvalentieruimte die wordt gedefinieerd door de moderne psychologie. Krediet:Jurie et al.
Onderzoekers van Orange Labs en Normandie University hebben een nieuw diep neuraal model ontwikkeld voor audiovisuele emotieherkenning dat goed presteert bij kleine trainingssets. hun studie, die voorgepubliceerd was op arXiv , volgt een filosofie van eenvoud, de parameters die het model uit datasets haalt aanzienlijk beperken en eenvoudige leertechnieken gebruiken.
Neurale netwerken voor emotieherkenning hebben een aantal nuttige toepassingen binnen de context van de gezondheidszorg, klant analyse, toezicht, en zelfs animatie. Hoewel state-of-the-art deep learning-algoritmen opmerkelijke resultaten hebben bereikt, de meesten zijn nog steeds niet in staat om hetzelfde begrip van emoties te bereiken dat door mensen wordt bereikt.
"Ons algemene doel is om de interactie tussen mens en computer te vergemakkelijken door computers in staat te stellen verschillende subtiele details waar te nemen die door mensen worden uitgedrukt, " Frederic Jurie, een van de onderzoekers die het onderzoek heeft uitgevoerd, vertelde TechXplore. "Het waarnemen van emoties in beelden, video, stem en geluid vallen binnen deze context."
Onlangs, studies hebben multimodale en temporele datasets samengesteld die geannoteerde video's en audiovisuele clips bevatten. Toch bevatten deze datasets doorgaans een relatief klein aantal geannoteerde voorbeelden, terwijl je goed presteert, de meeste bestaande deep learning-algoritmen vereisen grotere datasets.
De onderzoekers probeerden dit probleem aan te pakken door een nieuw raamwerk te ontwikkelen voor audiovisuele emotieherkenning, die de analyse van visuele en audiobeelden combineert, een hoge mate van nauwkeurigheid behouden, zelfs met relatief kleine trainingsdatasets. Ze trainden hun neurale model op AFEW, een dataset van 773 audiovisuele clips uit films en geannoteerd met discrete emoties.

Illustratie van hoe deze 2D-ruimte kan worden gebruikt om emoties te beheersen die worden uitgedrukt door gezichten, op een continue manier, met behulp van adversarial generatieve netwerken (GAN). Krediet:Jurie et al.
"Je kunt dit model zien als een zwarte doos die de video verwerkt en automatisch de emotionele toestand van mensen afleidt, Jurie legt uit. "Een groot voordeel van zulke diepe neurale modellen is dat ze zelf leren hoe ze de video moeten verwerken door voorbeelden te analyseren, en vereisen geen experts om specifieke verwerkingseenheden te leveren."
Het door de onderzoekers bedachte model volgt het filosofische principe van het scheermes van Occam, wat suggereert dat tussen twee benaderingen of verklaringen, de eenvoudigste is de beste keuze. In tegenstelling tot andere deep learning-modellen voor emotieherkenning, daarom, hun model is relatief eenvoudig gehouden. Het neurale netwerk leert een beperkt aantal parameters uit de dataset en maakt gebruik van basisleerstrategieën.
"Het voorgestelde netwerk is gemaakt van gecascadeerde verwerkingslagen die de informatie abstraheren, van het signaal tot de interpretatie ervan, "Zei Jurie. "Audio en video worden verwerkt door twee verschillende kanalen van het netwerk en worden de laatste tijd gecombineerd in het proces, bijna aan het einde."
Wanneer getest, hun lichtmodel behaalde een veelbelovende nauwkeurigheid van emotieherkenning van 60,64 procent. Het werd ook vierde bij de 2018 Emotion Recognition in the Wild (EmotiW) uitdaging, gehouden op de ACM International Conference on Multimodal Interaction (ICMI), in Colorado.

Illustratie van hoe deze 2D-ruimte kan worden gebruikt om emoties te beheersen die worden uitgedrukt door gezichten, op een continue manier, met behulp van adversarial generatieve netwerken (GAN). Krediet:Jurie et al.
"Ons model is het bewijs dat volgens het scheermesprincipe van Occam, d.w.z., door altijd de eenvoudigste alternatieven te kiezen voor het ontwerpen van neurale netwerken, het is mogelijk om de grootte van de modellen te beperken en zeer compacte maar ultramoderne neurale netwerken te verkrijgen, die gemakkelijker te trainen zijn, "Zei Jurie. "Dit staat in contrast met de onderzoekstrend om neurale netwerken steeds groter te maken."
De onderzoekers zullen nu doorgaan met het onderzoeken van manieren om een hoge nauwkeurigheid in emotieherkenning te bereiken door gelijktijdig visuele en auditieve gegevens te analyseren, gebruikmakend van de beperkte geannoteerde trainingsdatasets die momenteel beschikbaar zijn.
"We zijn geïnteresseerd in verschillende onderzoeksrichtingen, zoals hoe de verschillende modaliteiten beter te fuseren, hoe emotie te representeren door compact semantisch volledige descriptoren te betekenen (en niet alleen klassenlabels) of hoe onze algoritmen in staat te stellen om met minder te leren, of zelfs zonder geannoteerde gegevens, ' zei Jurrie.
© 2018 Tech Xplore
 Psychologie is de sleutel om mensen eruit te krijgen voordat het noodlot toeslaat
Psychologie is de sleutel om mensen eruit te krijgen voordat het noodlot toeslaat- Hoe lang blijft een vlinder in een pop?
- Wetenschappers gebruiken nieuwe methoden om de beweging van koolstof in noordelijke terrestrische ecosystemen te onderzoeken
- NE Australische hittegolf op zee schudt populaties koraalrifdieren op
- Hoeveel biomassa groeit er in de savanne?
Hoofdlijnen
- Hoe zijn ggo's gemaakt?
- Omgaan met antibiotica niet genoeg om resistentie om te keren
- Reflecteert Saturnus licht?
- Hoe vogelgenetica zich aanpast aan klimaatverandering
- De krimpende eland van Isle Royale
- Wat zijn de zes menselijke levensprocessen?
- Biologen maken kever met functioneel extra oog
- Wat is apoptose?
- CRISPR-octrooioorlogen benadrukken het probleem van het verlenen van brede intellectuele eigendomsrechten voor technologie die publieke voordelen biedt
- De technische sector maakt zich zorgen over de handelsspanningen tussen de VS en China

- Let op de kloof tussen apps voor openbaar vervoer en taxi's

- Huawei gaat over op 5G terwijl de politiek zich afspeelt

- VS gebruiken nep-sociale media om mensen te controleren die land binnenkomen

- Hoe kunstmatige intelligentie nepnieuws kan detecteren – en creëren


 Alexa, mijn hoofd doet pijn:Britse gezondheidsdienst meldt zich aan bij Amazon
Alexa, mijn hoofd doet pijn:Britse gezondheidsdienst meldt zich aan bij Amazon- Science Fair Project over rijpende bananen
- Elektronische grensvlaktoestand die de waterstofopslagcapaciteit in Pd-MOF-materialen verbetert
- Een populatie asteroïden van interstellaire oorsprong bewoont het zonnestelsel
- Dokter voert eerste 5G-operatie uit in stap richting robotica-droom
- Natuurkundigen creëren nieuw nanodeeltje voor kankertherapie
- Nieuw rapport schetst mogelijke opbrengstuitdagingen voor opschaling van natuurlijke landbouw zonder budget in India
- Hoe kinderen te leren waar eten vandaan komt - laat ze tuinieren
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Portuguese | Swedish | German | Dutch | Danish | Norway | Spanish |

-
Wetenschap © https://nl.scienceaq.com
