Wetenschap
Een nieuwe complexe netwerkgebaseerde benadering van onderwerpmodellering
Krediet:Gerlach et al.
Onderzoekers van de Northwestern University, de Universiteit van Bath, en de Universiteit van Sydney hebben een nieuwe netwerkbenadering van onderwerpmodellen ontwikkeld, machine learning-strategieën die abstracte onderwerpen en semantische structuren in tekstdocumenten kunnen ontdekken.
"Een van de belangrijkste computationele en wetenschappelijke uitdagingen in de moderne tijd is om nuttige informatie te extraheren uit ongestructureerde teksten, "De onderzoekers legden in hun studie uit. "Onderwerpmodellen zijn een populaire machine-learningbenadering die de latente actuele structuur van een verzameling documenten afleidt."
Momenteel worden onderwerpmodellen gebruikt om semantisch gerelateerde teksten te identificeren en documenten te classificeren binnen een aantal velden, inclusief sociologie, geschiedenis, taalkunde, en psychologie. De meest gebruikte methode, latente Dirichlet-toewijzing (LDA), wordt ook gebruikt voor bibliometrische, psychologische en politieke analyse, maar ook voor beeldverwerking.
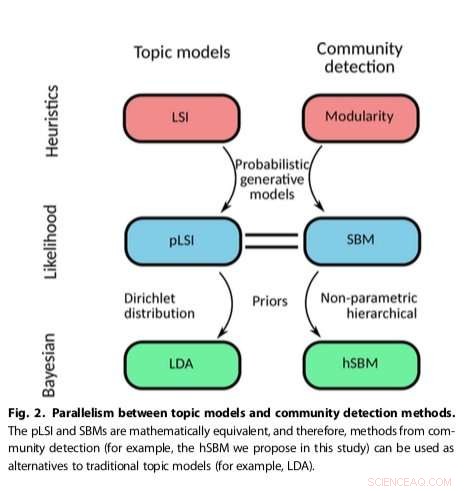
Ondanks het wijdverbreide succes, LDA vertoont verschillende gebreken in de manier waarop het tekst weergeeft, zoals een gebrek aan methode om het aantal onderwerpen te kiezen, discrepanties met statistische eigenschappen van echte teksten en een gebrek aan rechtvaardiging voor de Bayesiaanse prior, wat in Bayesiaanse statistische gevolgtrekking de kansverdeling is die wordt uitgedrukt voordat het bewijs wordt gepresenteerd.
Krediet:Gerlach et al.
Een groot deel van het recente onderzoek naar onderwerpmodellen was gericht op het creëren van meer geavanceerde versies van LDA die beter presteren of bepaalde aspecten van documenten effectief kunnen analyseren.
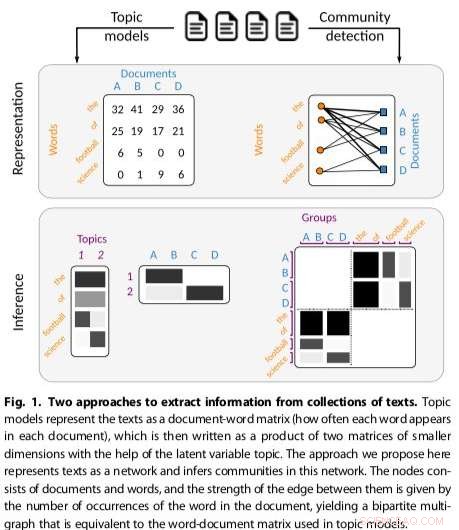
De aanpak die door dit team van onderzoekers is ontwikkeld, komt voort uit de netwerktheorie, een theorie die wordt gebruikt in de natuurkunde en andere wetenschappelijke gebieden die technieken biedt voor het analyseren van grafieken, evenals structuren in systemen met verschillende interactie agenten. Hun nieuwe raamwerk voor onderwerpmodellering is gebaseerd op de benadering die wordt gebruikt om gemeenschappen in complexe netwerken te vinden, die, in de context van netwerktheorie, is een grafiek met kenmerken die voorkomen bij het modelleren van real-life systemen.
"Ik werkte aan natuurlijke taal en onderwerpmodellering vanuit het perspectief van complexe systemen en complexe netwerken, "Martin Gerlach, postdoctoraal onderzoeker aan de Northwestern University vertelde TechXplore. "De problemen leken erg op elkaar, toch leken de gemeenschappen van informatica (onderwerpmodellering) en complexe netwerken grotendeels onafhankelijk te werken. opgeleid als fysicus, we wilden laten zien dat twee schijnbaar verschillende problemen kunnen worden teruggebracht tot dezelfde onderliggende wiskunde."
Gerlach en zijn collega's bedachten een nieuwe benadering voor het identificeren van actuele structuren die verband houdt met het probleem van het vinden van gemeenschappen in complexe netwerken. Hun techniek vertegenwoordigt tekstcorpora als bipartiete netwerken, een klasse van complexe netwerken die knooppunten verdelen in sets X en Y, alleen verbindingen tussen knooppunten in verschillende sets toestaan.
Krediet:Gerlach et al.
"We hebben het probleem van onderwerpmodellering in kaart gebracht met het probleem van gemeenschapsdetectie in een netwerk dat bestaat uit woorden en documenten die aantonen dat ze wiskundig equivalent zijn, ’ legde Gerlach uit.
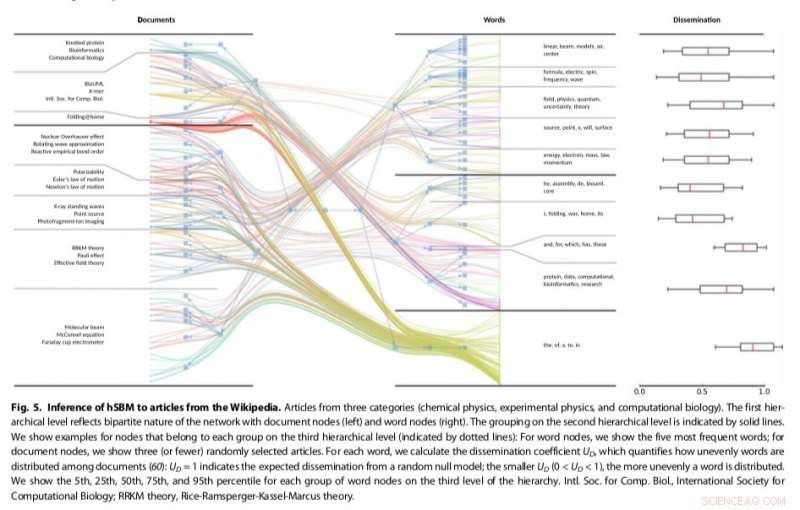
De aanpak van de onderzoekers, die bestaande methoden voor gemeenschapsdetectie aanpast, bleek veelzijdiger en principiëler te zijn dan andere bestaande onderwerpmodellen, bijvoorbeeld het detecteren van het aantal onderwerpen dat aanwezig is in teksten en het hiërarchisch groeperen van zowel woorden als documenten. Hun methode maakte gebruik van een stochastisch blokmodel (SBM), een generatief model voor grafieken dat gemeenschappen in het algemeen in kaart brengt, subsets van items die met elkaar verbonden zijn.
"We lossen enkele van de intrinsieke en bekende problemen op van populaire algoritmen voor onderwerpmodellering zoals LDA (bijvoorbeeld hoe het aantal onderwerpen te bepalen), "zei Gerlach. "Bovendien, ons werk laat zien hoe we methoden van community-detectie en onderwerpmodellering formeel kunnen relateren, het openen van de mogelijkheid van kruisbestuiving tussen deze twee velden."
De door Gerlach en zijn collega's ontwikkelde SBM-aanpak zou interessante toepassingen kunnen hebben op andere gebieden waar machine learning wordt gebruikt, zoals de analyse van genetische codes of afbeeldingen. In de toekomst, de onderzoekers zijn van plan om het potentieel van complexe netwerken te blijven verkennen, zowel binnen de context van tekstanalyse als daarbuiten.
"De gelijkwaardigheid tussen onderwerpmodellering en gemeenschapsdetectie maakt het mogelijk om inzichten die in elk van de gemeenschappen zijn opgedaan te gebruiken en toe te passen op het andere domein, " zei Gerlach. "Ik hoop deze inzichten te gebruiken om een beter begrip te krijgen van deze machine learning-algoritmen; waarom ze werken, en nog belangrijker, onder welke voorwaarden ze niet werken."
© 2018 Tech Xplore
 De bizarre wereld van topologische materialen
De bizarre wereld van topologische materialen- Verbinding regelt biologische klok met licht
- Wat kunnen we gebruiken in plaats van Liquid Bluing voor Crystal Experiments?
- Wetenschappers vinden moleculaire vernietigingscode voor enzym dat betrokken is bij cholesterolproductie
- Chemische waarschuwingssymbolen en hun betekenis
In de VS zijn er twee belangrijke organisaties achter de chemische waarschuwingssymbolen op gevaarlijke stoffen: de Occupational Safety and Health Administration (OSHA) en de non-profit National Fire
- Waarom wetenschappers koraalrifgegevens moeten openen om habitats te beschermen
- Het verminderen van de uitstoot van zwaveldioxide alleen kan de luchtvervuiling niet substantieel verminderen
- Klimaatverandering veroorzaakt grote schade aan Colombiaanse gletsjers:overheid
- Opinie:klimaatverandering, pandemieën, biodiversiteitsverlies – geen enkel land is voldoende voorbereid
- Hoe krijgen vissen voedsel?
Hoofdlijnen
- Ziektekiemen kunnen onze persoonlijkheid helpen vormen
- Wat zijn 3 functies van de navelstreng?
- Strategie voor celdeling gedeeld door alle domeinen van het leven
- Wat zijn de voor- en nadelen van endotherm zijn?
- Hoe is een Paramecium Digest Food?
- De terugkeer van wolven naar Oregon brengt conflicten en kansen
- Darwins afschuwelijke mysterie oplossen:hoe bloeiende planten de wereld veroverden
- Waarom zouden wetenschappers een hybride mens-koe-embryo willen creëren?
- Genetisch verhogen van de voedingswaarde van maïs kan miljoenen ten goede komen






 Magnetisme van zwarte gaten verrassend slap
Magnetisme van zwarte gaten verrassend slap- Neutronen onderzoeken biologische materialen voor inzicht in COVID-19-virusinfectie
- Nieuwe explosie bij St. Vincent vulkaan; cruiseschip helpt evacués
- Oost-Antarctische zomerkoelingstrends veroorzaakt door clusters van tropische regenval
- Zoutzuur Veiligheidsmaatregelen
- Student maakt spray voor flitsontsmetting van instellingen
- Hoe Reaction Order te vinden
De reactiesnelheid van een gegeven reactie is de snelheid waarmee de componenten de specifieke reactie aangaan, waardoor een nieuw resultaat wordt gevormd (bijvoorbeeld verbinding of neerslag). De reactievolgorde is daa
- Geconstrueerde eiwitten plakken als lijm, zelfs in water
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
