Wetenschap
Onderzoekers ontwikkelen uitgebreidere analysemethode voor akoestische scènes
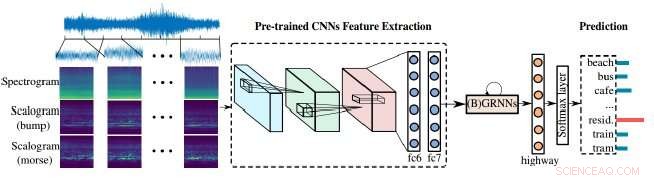
Voorspellingen van geluiden werden bereikt door een verbeterde methode ontwikkeld door een internationaal team van onderzoekers. Credit: IEEE/CAA Journal of Automatica Sinica
Onderzoekers hebben een verbeterde methode gedemonstreerd voor audio-analysemachines om onze lawaaierige wereld te verwerken. Hun benadering hangt af van de combinatie van scalogrammen en spectrogrammen - de visuele representaties van audio - en convolutionele neurale netwerken (CNN's), de leertool die machines gebruiken om visuele beelden beter te analyseren. In dit geval, de visuele beelden worden gebruikt om audio te analyseren om geluid beter te identificeren en te classificeren.
Het team publiceerde hun resultaten in het tijdschrift IEEE/CAA Journal of Automatica Sinica ( JAS ), een gezamenlijke publicatie van de IEEE en de Chinese Association of Automation.
"Machines hebben grote vooruitgang geboekt in de analyse van spraak en muziek, maar de algemene geluidsanalyse bleef sterk achter - meestal in het verleden zijn veelal geïsoleerde geluids-'gebeurtenissen' zoals geweerschoten en dergelijke het doelwit geweest, " zei Björn Schuller, een professor en voorzitter van Embedded Intelligence for Health Care and Wellbeing aan de Universiteit van Augsburg in Duitsland, die het onderzoek leidde. "Audio uit de echte wereld is meestal een sterk vermengde mix van verschillende geluidsbronnen, die elk verschillende toestanden en eigenschappen hebben."
Schuller noemt het geluid van een auto als voorbeeld. Het is geen enkelvoudig audio-evenement; nogal verschillende delen van de auto-onderdelen, zijn banden in wisselwerking met de weg, het merk en de snelheid van de auto zorgen allemaal voor hun eigen unieke kenmerken.
"Tegelijkertijd, er kan muziek of spraak in de auto zijn, " zei Schuller, die ook universitair hoofddocent Machine Learning is aan het Imperial College London, en gasthoogleraar aan de School of Computer Science and Technology aan het Harbin Institute of Technology in China. "Zodra computers alle delen van deze 'akoestische scène' kunnen begrijpen, ze zullen aanzienlijk beter zijn in het opsplitsen in elk deel en elk deel toeschrijven zoals beschreven."
Spectrogrammen bieden een visuele weergave van audioscènes, maar ze hebben een vaste tijdfrequentieresolutie, dat is het moment waarop frequenties veranderen. Scalogrammen, anderzijds, een meer gedetailleerde visuele weergave van akoestische scènes bieden dan spectrogrammen, bijvoorbeeld, akoestische scènes zoals de muziek of de spraak of andere geluiden in de auto kunnen nu beter worden weergegeven.
"Er zijn meestal meerdere geluiden in één scène, dus... er moeten meerdere frequenties zijn en ze veranderen met de tijd, " zei Zhao Ren, een auteur op het papier en een Ph.D. kandidaat aan de Universiteit van Augsburg die samenwerkt met Schuller. "Gelukkig, scalogrammen zouden dit probleem precies kunnen oplossen, omdat het meerdere schalen bevat."
"Scalogrammen kunnen worden gebruikt om spectrogrammen te helpen bij het extraheren van functies voor classificatie van akoestische scènes, "Ren zei, en zowel spectrogrammen als scalogrammen moeten kunnen leren om te blijven verbeteren.
"Verder, voorgetrainde neurale netwerken bouwen een brug tussen [de] beeld- en audioverwerking."
De vooraf getrainde neurale netwerken die de auteurs hebben gebruikt, zijn Convolutional Neural Networks (CNN's). CNN's zijn geïnspireerd door hoe neuronen werken in de visuele cortex van dieren en de kunstmatige neurale netwerken kunnen worden gebruikt om visuele beelden met succes te verwerken. Dergelijke netwerken zijn cruciaal in machine learning, en in dit geval helpen bij het verbeteren van de scalpogrammen.
CNN's krijgen wat training voordat ze worden toegepast op een scène, maar ze leren vooral van blootstelling. Door geluiden te leren van een combinatie van verschillende frequenties en toonladders, het algoritme kan de bronnen beter voorspellen en, eventueel, het resultaat van een ongewoon geluid voorspellen, zoals een motorstoring van een auto.
"Het uiteindelijke doel is machinaal horen/luisteren op een holistische manier... over spraak, muziek, en klinken zoals een mens zou doen, "Schuller zei, opmerkend dat dit in combinatie met het reeds geavanceerde werk op het gebied van spraakanalyse een rijker en dieper begrip zou opleveren, "om dan 'het hele plaatje' in de audio te krijgen."
 Humanitaire forensische wetenschappers sporen de vermiste, identificeer de doden en troost de levenden
Humanitaire forensische wetenschappers sporen de vermiste, identificeer de doden en troost de levenden- Lignine – een supergroene brandstof voor brandstofcellen
- Hoe de Valence orbitaal van een element te bepalen
- Ultrakleine holle nanodeeltjes van legering voor synergetische katalyse van waterstofevolutie
- Ultradunne gespoten MXene-antennes zijn klaar voor 5G
- Studie van microfossielen brengt extreme opwarming van de aarde en veranderingen in het milieu in kaart
- VN-klimaatchef:Kooldioxidebesparingsplannen ingediend voor wereldtop schieten tekort
- Wateren voor de kust van New England in het midden van een recordjaar voor warmte
- Nieuw inzicht in het Grote Sterven
- Wetenschappers stoppen diepwatersondes in Caribische wateren
Hoofdlijnen
- Human Heart Science Projects
- Nieuw onderzoek benadrukt de noodzaak om te leren van klimaatveranderingen uit het verleden
- Relatie tussen DNA en natuurlijke selectie
- Informatie over bloedvaten
- Genetische studie onderzoekt manieren om de productiviteit en malsheid van vlees te verhogen
- Vliegen ontwikkelen springen zonder poten
- Afwijkende hyfen veroorzaakt door immuunreacties van de gastheer op plantpathogene schimmel
- Hoe maak je een modelhart met materialen uit je thuis
- Zoogdier waarvan lang gedacht werd dat het uitgestorven was in Australië duikt weer op
- Onderzoek naar aardgasopslag kan opwarming van de aarde tegengaan

- Airbus benoemt eind dit jaar nieuwe CEO:bedrijf

- Alibaba koopt NetEases import e-commerce-eenheid voor $ 2 miljard

- Yahoo Japan, Lijn om bedrijf samen te voegen tot online gigant

- E-scooters in Auckland kosten het gezondheidssysteem $ 1 miljoen in 7 maanden


 Krill zou een geheim wapen kunnen zijn in de strijd tegen plastic in de oceaan
Krill zou een geheim wapen kunnen zijn in de strijd tegen plastic in de oceaan- De joystick weggooien? Zwitsers ontwikkelen jack dat drones bestuurt
- Mars 2020 rover krijgt zijn wielen
- Emotie-leestechnologie faalt in de test voor raciale vooroordelen
- 3D hohlraum-model helpt bij implosies met indirecte aandrijving bij NIF
- Het voedsel gebruiken dat wordt verspild in New York City
- Kan het echt kikkers regenen?
- Nieuw internationaal onderzoek geeft ondernemers tips om de sleur te verslaan
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
