Wetenschap
Computers trainen om dynamische gebeurtenissen te herkennen
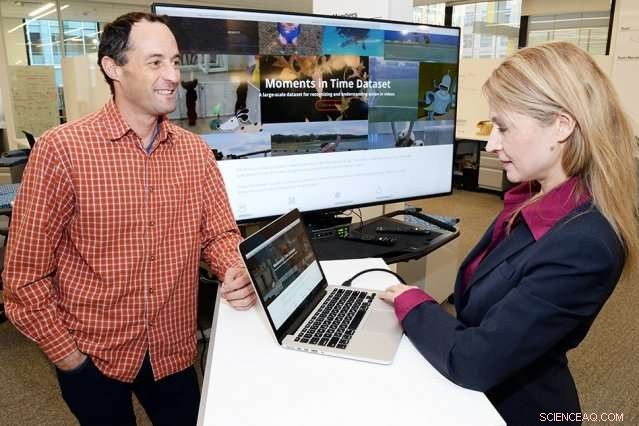
Aude Oliva (rechts), een hoofdonderzoeker bij het Computer Science and Artificial Intelligence Laboratory en Dan Gutfreund (links), een hoofdonderzoeker bij het MIT–IBM Watson AI Laboratory en een staflid bij IBM Research, zijn de hoofdonderzoekers voor de Moments in Time Dataset, een van de projecten met betrekking tot AI-algoritmen gefinancierd door het MIT–IBM Watson AI Laboratory. Credit:John Mottern/Feature Photo Service voor IBM
Een persoon die video's bekijkt die laten zien dat dingen opengaan - een deur, een boek, gordijnen, een bloeiende bloem, een gapende hond - begrijpt gemakkelijk dat hetzelfde type actie in elke clip wordt weergegeven.
"Computermodellen slagen er jammerlijk niet in om deze dingen te identificeren. Hoe doen mensen dat zo moeiteloos?" vraagt Dan Gutfreund, een hoofdonderzoeker bij het MIT-IBM Watson AI Laboratory en een staflid bij IBM Research. "We verwerken informatie zoals die zich in ruimte en tijd afspeelt. Hoe kunnen we computermodellen dat leren?"
Dat zijn de grote vragen achter een van de nieuwe projecten die aan de gang zijn bij het MIT-IBM Watson AI Laboratory, een samenwerking voor onderzoek naar de grenzen van kunstmatige intelligentie. Afgelopen najaar gelanceerd, het lab verbindt MIT- en IBM-onderzoekers samen om te werken aan AI-algoritmen, de toepassing van AI op industrieën, de fysica van AI, en manieren om AI te gebruiken om gedeelde welvaart te bevorderen.
De Moments in Time-dataset is een van de projecten met betrekking tot AI-algoritmen die door het lab worden gefinancierd. Het koppelt Gutfreund aan Aude Oliva, een hoofdonderzoeker aan het MIT Computer Science and Artificial Intelligence Laboratory, als hoofdonderzoekers van het project. Moments in Time is gebaseerd op een verzameling van 1 miljoen geannoteerde video's van dynamische gebeurtenissen die zich binnen drie seconden ontvouwen. Gutfreund en Oliva, die ook de uitvoerend directeur van het MIT is bij het MIT-IBM Watson AI Lab, gebruiken deze clips om een van de volgende grote stappen voor AI aan te pakken:machines leren om acties te herkennen.
Leren van dynamische scènes
Het doel is om diepgaande algoritmen te bieden met een grote dekking van een ecosysteem van visuele en auditieve momenten die modellen in staat kunnen stellen om informatie te leren die niet noodzakelijk op een gecontroleerde manier wordt aangeleerd en om te generaliseren naar nieuwe situaties en taken, zeggen de onderzoekers.
"Als we opgroeien, wij kijken om ons heen, we zien mensen en objecten bewegen, we horen geluiden die mensen en objecten maken. We hebben veel visuele en auditieve ervaringen. Een AI-systeem moet op dezelfde manier leren en gevoed worden met video's en dynamische informatie, ' zegt Oliva.
Voor elke actiecategorie in de dataset, zoals koken, rennen, of openen, er zijn er meer dan 2, 000 video's. De korte clips stellen computermodellen in staat om de diversiteit aan betekenissen rond specifieke acties en gebeurtenissen beter te leren kennen.
"Deze dataset kan dienen als een nieuwe uitdaging om AI-modellen te ontwikkelen die schaalbaar zijn tot het niveau van complexiteit en abstracte redenering dat een mens dagelijks verwerkt, "Oliva voegt eraan toe, beschrijven van de betrokken factoren. Evenementen kunnen mensen, voorwerpen, dieren, en natuur. Ze kunnen symmetrisch zijn in de tijd, bijvoorbeeld openen betekent sluiten in omgekeerde volgorde. En ze kunnen van voorbijgaande aard of aanhoudend zijn.
Oliva en Gutfreund, samen met aanvullende onderzoekers van MIT en IBM, meer dan een jaar wekelijks bijeengekomen om technische problemen aan te pakken, zoals het kiezen van de actiecategorieën voor annotaties, waar vind je de video's, en hoe je een breed scala kunt samenstellen zodat het AI-systeem zonder vooroordelen leert. Het team ontwikkelde ook modellen voor machine learning, die vervolgens werden gebruikt om de gegevensverzameling te schalen. "We hebben heel goed op elkaar afgestemd omdat we hetzelfde enthousiasme en hetzelfde doel hebben, ' zegt Oliva.
Menselijke intelligentie vergroten
Een belangrijk doel van het lab is de ontwikkeling van AI-systemen die verder gaan dan gespecialiseerde taken om complexere problemen aan te pakken en te profiteren van robuust en continu leren. "We zijn op zoek naar nieuwe algoritmen die niet alleen gebruikmaken van big data, indien beschikbaar, maar leer ook van beperkte gegevens om de menselijke intelligentie te vergroten, " zegt Sophie V. Vandebroek, chief operating officer van IBM Research, over de samenwerking.
Naast het koppelen van de unieke technische en wetenschappelijke sterke punten van elke organisatie, IBM brengt MIT-onderzoekers ook een toestroom van middelen, gesignaleerd door zijn investering van $ 240 miljoen in AI-inspanningen in de komende 10 jaar, gewijd aan het MIT-IBM Watson AI Lab. En de afstemming van de interesse van MIT en IBM in AI blijkt gunstig, volgens Oliva.
"IBM kwam naar MIT met een interesse in het ontwikkelen van nieuwe ideeën voor een kunstmatige-intelligentiesysteem op basis van visie. Ik stelde een project voor waarbij we datasets bouwen om het model over de wereld te voeden. Het was nog niet eerder op dit niveau gedaan. Het was een nieuwe onderneming. Nu hebben we de mijlpaal van 1 miljoen video's voor visuele AI-training bereikt, en mensen kunnen naar onze website gaan, download de dataset en onze deep-learning computermodellen, die zijn geleerd om acties te herkennen."
Kwalitatieve resultaten tot nu toe hebben aangetoond dat modellen momenten goed kunnen herkennen wanneer de actie goed is ingekaderd en van dichtbij, maar ze werken niet goed als de categorie fijnkorrelig is of als er achtergrondruis is, onder andere. Oliva zegt dat MIT- en IBM-onderzoekers een artikel hebben ingediend waarin de prestaties worden beschreven van neurale netwerkmodellen die op de dataset zijn getraind. die zelf werd verdiept door gedeelde standpunten. "IBM-onderzoekers gaven ons ideeën om actiecategorieën toe te voegen om meer rijkdom te hebben op gebieden als gezondheidszorg en sport. Ze verbreedden onze blik. Ze gaven ons ideeën over hoe AI een impact kan hebben vanuit het perspectief van het bedrijfsleven en de behoeften van de wereld, " ze zegt.
Deze eerste versie van de Moments in Time-dataset is een van de grootste door mensen geannoteerde videodatasets die visuele en hoorbare korte gebeurtenissen vastlegt. die allemaal zijn getagd met een actie- of activiteitenlabel uit 339 verschillende klassen die een breed scala aan veelvoorkomende werkwoorden bevatten. De onderzoekers zijn van plan meer datasets te produceren met verschillende abstractieniveaus om te dienen als opstap naar de ontwikkeling van leeralgoritmen die analogieën tussen dingen kunnen bouwen, nieuwe gebeurtenissen bedenken en synthetiseren, en scenario's interpreteren.
Met andere woorden, ze zijn net begonnen, zegt Gutfreund. "We verwachten dat de Moments in Time-dataset modellen in staat zal stellen om acties en dynamiek in video's rijkelijk te begrijpen."
Dit verhaal is opnieuw gepubliceerd met dank aan MIT News (web.mit.edu/newsoffice/), een populaire site met nieuws over MIT-onderzoek, innovatie en onderwijs.
 Onderzoek naar de relatie tussen het tweelichaam en het collectief
Onderzoek naar de relatie tussen het tweelichaam en het collectief- Wetenschappers halen waterstofgas uit olie en bitumen, potentiële vervuilingsvrije energie geven
- Kalium-aangedreven oplaadbare batterijen:een poging tot een duurzamer milieu
- Groene plastic productie gemakkelijk gemaakt
- Wetenschappers stellen redoxmechanisme voor water-gasverschuivingsreactie voor
- Niet aanpassen aan klimaatverandering kost waarschijnlijk minstens vijf keer meer
- Arctisch zee-ijs wordt sneller dunner dan verwacht
- In New-York, één non-profitorganisatie om textielverspilling tegen te gaan
- Verschillen tussen een kat, een hond en een menselijk skelet
- Schadeschattingen voor orkanen zoals Dorian geven niet de volledige kosten weer van door klimaatverandering veroorzaakte rampen
Hoofdlijnen
- Hoe het Human Microbiome-project werkt
- Macht overdragen aan staten zal de bescherming van bedreigde diersoorten niet verbeteren
- Muizen in sociale conflicten vertonen gedrag dat zich aan regels houdt
- Sarcodina Life Cycle
- Habitat: definitie, soorten en voorbeelden
- Snellere Salmonella-test verhoogt voedselveiligheid voor mens en dier
- Wat zijn Agar Slants?
- Wat zou er gebeuren als een cel geen ribosomen zou hebben?
- Welke functies delen mitochondria en bacteriën?
- Israël probeert de groeiende wereldwijde honger naar voedseltechnologie te voeden

- Britse toezichthouder onderzoekt Facebook wegens politieke campagnes

- Explainer:hoe YouTube verandert wat het kinderen laat zien

- Instagram onthult nieuwe videoservice als uitdaging voor YouTube

- Je smartphone kan helpen om kankeronderzoek te versnellen terwijl je slaapt

 Hoe CAT-scans werken
Hoe CAT-scans werken - Kleine titanium barrière stopt groot probleem in brandstofproducerende zonnecellen
- Beelden van de zon van de GOES-16 satelliet
- Wat zijn de gevaren van CO2-gas?
- Gemakkelijke manier om Flubber te maken
- Wat we over onszelf kunnen leren door financiële handelsbots te bestuderen
- IJsbeerblogs onthullen gevaarlijke kloof tussen feiten en meningen over klimaatverandering
- Calciumbatterijen:nieuwe elektrolyten, verbeterde eigenschappen
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | German | Dutch | Danish | Norway | Swedish |

-
Wetenschap © https://nl.scienceaq.com
